Conditional Representation Learning for Customized Tasks
作者: Honglin Liu, Chao Sun, Peng Hu, Yunfan Li, Xi Peng
分类: cs.CV
发布日期: 2025-10-06 (更新: 2025-12-13)
🔗 代码/项目: GITHUB
💡 一句话要点
提出条件表示学习(CRL),为定制任务提取特定语义的图像表征。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 条件表示学习 视觉-语言模型 大型语言模型 定制任务 图像表示
📋 核心要点
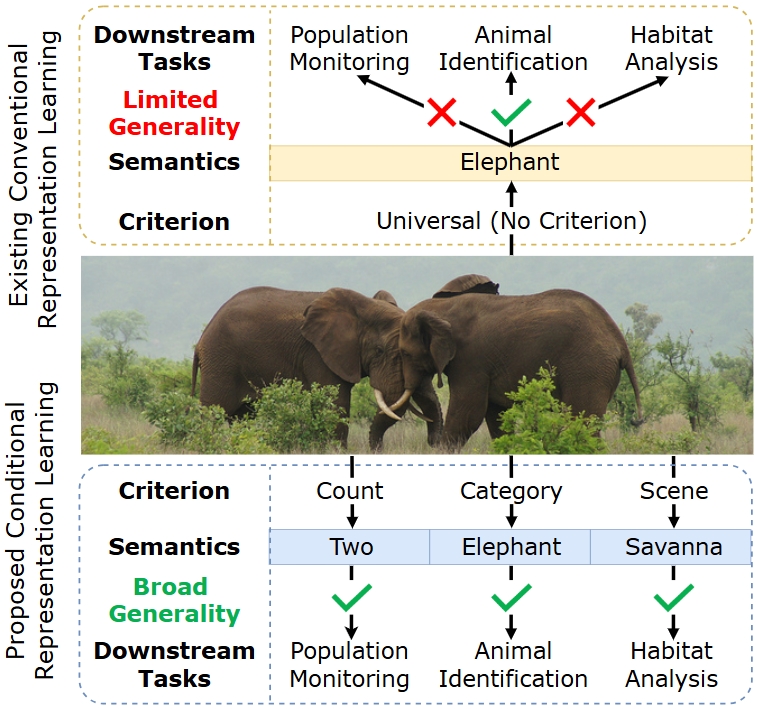
- 现有通用表示学习方法难以满足特定下游任务的需求,且有监督微调成本高昂。
- CRL利用LLM生成描述性文本构建语义基,并用VLM将图像表示投影到条件特征空间。
- 实验表明,CRL在分类和检索任务上表现优异,证明了其有效性和通用性。
📝 摘要(中文)
传统的表示学习方法学习的是一种通用的表示,主要捕捉的是主要的语义信息,但这并不总是与定制的下游任务相符。例如,在动物栖息地分析中,研究人员优先考虑与场景相关的特征,而通用的嵌入则强调类别语义,导致结果不理想。为了解决这个问题,现有的方法通常采用有监督的微调,但这会带来很高的计算和标注成本。本文提出了一种条件表示学习(CRL)方法,旨在提取针对任意用户指定标准的表示。具体来说,我们揭示了一个空间的语义是由它的基决定的,因此可以使用一组描述性词语来近似定制特征空间的基。基于这一洞察,给定一个用户指定的标准,CRL首先利用大型语言模型(LLM)生成描述性文本来构建语义基,然后利用视觉-语言模型(VLM)将图像表示投影到这个条件特征空间中。条件表示更好地捕捉了特定标准的语义,可以用于多个定制任务。在分类和检索任务上的大量实验证明了所提出的CRL的优越性和通用性。
🔬 方法详解
问题定义:现有通用表示学习方法提取的特征主要关注图像的通用语义,忽略了特定任务的需求。例如,在动物栖息地分析中,研究人员可能更关注场景特征,而通用表示则侧重于动物类别。此外,通过有监督微调来适应特定任务需要大量的标注数据和计算资源,成本高昂。
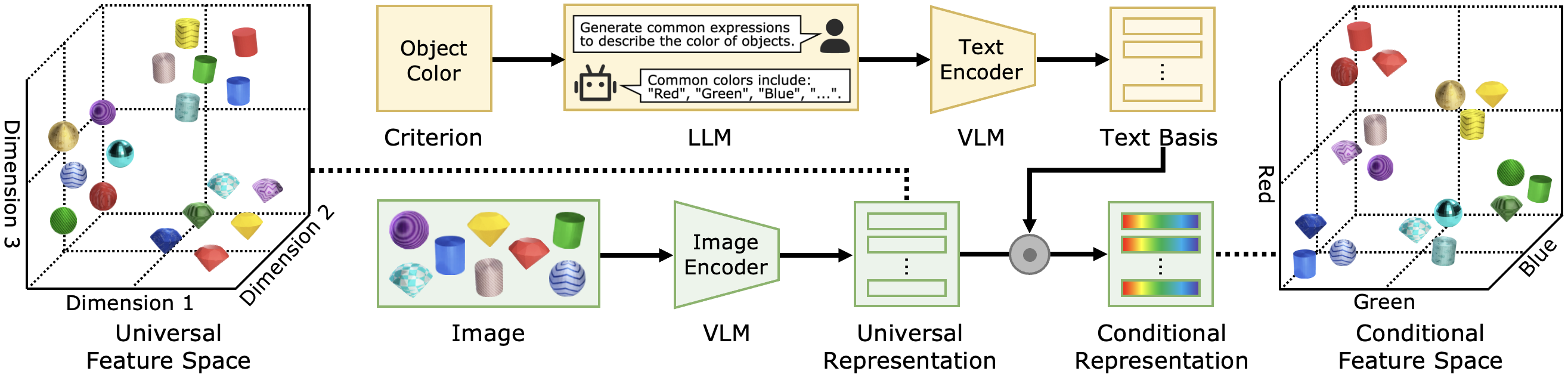
核心思路:论文的核心思路是,特征空间的语义是由其基决定的。因此,可以通过构建一个与特定任务相关的语义基,并将图像表示投影到这个基所定义的空间中,从而获得针对该任务的定制化表示。论文利用大型语言模型(LLM)生成描述性文本来近似这个语义基。
技术框架:CRL的整体框架包括以下几个主要步骤:1) 用户指定任务标准(例如,描述动物栖息地的文本)。2) 利用LLM(如GPT-3)根据任务标准生成描述性文本,这些文本被视为语义基的近似。3) 使用视觉-语言模型(VLM,如CLIP)将图像和描述性文本嵌入到同一个特征空间中。4) 通过某种投影方式(例如,线性变换)将图像的视觉特征投影到由描述性文本所定义的语义基上,得到条件表示。
关键创新:CRL的关键创新在于利用LLM生成描述性文本来构建任务相关的语义基,从而避免了对大量标注数据的依赖。与传统的微调方法相比,CRL只需要用户提供任务描述,而不需要标注数据。此外,CRL通过VLM将视觉特征和语义基对齐,实现了跨模态的知识迁移。
关键设计:在具体实现上,论文可能需要考虑以下关键设计:1) 如何选择合适的LLM和VLM?不同的模型可能具有不同的性能和适用性。2) 如何设计投影方式?简单的线性变换可能无法充分捕捉视觉特征和语义基之间的复杂关系。3) 如何优化损失函数?需要设计合适的损失函数来鼓励视觉特征向语义基对齐,并避免过拟合。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CRL在分类和检索任务上显著优于现有的通用表示学习方法。具体性能提升数据未知,但论文强调了CRL在多个定制任务上的优越性和通用性,证明了其有效性。
🎯 应用场景
CRL可广泛应用于需要定制化图像表示的场景,如细粒度图像分类、特定属性图像检索、以及机器人视觉中的任务导向感知。该方法降低了对大量标注数据的依赖,使得在资源受限的环境中也能实现高效的图像理解和应用,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Conventional representation learning methods learn a universal representation that primarily captures dominant semantics, which may not always align with customized downstream tasks. For instance, in animal habitat analysis, researchers prioritize scene-related features, whereas universal embeddings emphasize categorical semantics, leading to suboptimal results. As a solution, existing approaches resort to supervised fine-tuning, which however incurs high computational and annotation costs. In this paper, we propose Conditional Representation Learning (CRL), aiming to extract representations tailored to arbitrary user-specified criteria. Specifically, we reveal that the semantics of a space are determined by its basis, thereby enabling a set of descriptive words to approximate the basis for a customized feature space. Building upon this insight, given a user-specified criterion, CRL first employs a large language model (LLM) to generate descriptive texts to construct the semantic basis, then projects the image representation into this conditional feature space leveraging a vision-language model (VLM). The conditional representation better captures semantics for the specific criterion, which could be utilized for multiple customized tasks. Extensive experiments on classification and retrieval tasks demonstrate the superiority and generality of the proposed CRL. The code is available at https://github.com/XLearning-SCU/2025-NeurIPS-CRL.