RAP: 3D Rasterization Augmented End-to-End Planning
作者: Lan Feng, Yang Gao, Eloi Zablocki, Quanyi Li, Wuyang Li, Sichao Liu, Matthieu Cord, Alexandre Alahi
分类: cs.CV, cs.RO
发布日期: 2025-10-05
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出RAP:基于光栅化的数据增强端到端自动驾驶规划方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 端到端规划 自动驾驶 数据增强 3D光栅化 模仿学习
📋 核心要点
- 现有端到端驾驶模仿学习方法依赖专家数据,缺乏闭环部署中的恢复能力,难以应对未见场景。
- RAP方法通过3D光栅化技术生成语义保真、可扩展的增强数据,并引入特征空间对齐弥合模拟与现实差距。
- RAP在多个自动驾驶基准测试中取得领先,证明了轻量级光栅化数据增强在端到端训练中的有效性。
📝 摘要(中文)
端到端驾驶的模仿学习策略仅在专家演示数据上训练。在闭环部署后,此类策略缺乏恢复数据:小错误无法纠正,并迅速累积成失败。一个有希望的方向是生成超出已记录路径的替代视角和轨迹。先前的工作探索了通过神经渲染或游戏引擎实现的照片级逼真数字孪生,但这些方法速度慢且成本高昂,因此主要用于评估。本文认为,照片级逼真度对于训练端到端规划器是不必要的。重要的是语义保真度和可扩展性:驾驶取决于几何和动力学,而不是纹理或光照。受此启发,我们提出了3D光栅化,它用轻量级的光栅化带注释的图元替换了昂贵的渲染,从而实现了诸如反事实恢复操作和跨代理视图合成之类的数据增强。为了将这些合成视图有效地转移到真实世界的部署中,我们引入了光栅到真实特征空间的对齐,从而弥合了sim-to-real的差距。这些组件共同构成了光栅化增强规划(RAP),这是一个用于规划的可扩展数据增强管道。RAP在四个主要基准测试中排名第一:NAVSIM v1/v2、Waymo Open Dataset Vision-based E2E Driving和Bench2Drive,实现了最先进的闭环鲁棒性和长尾泛化。我们的结果表明,具有特征对齐的轻量级光栅化足以扩展E2E训练,从而为照片级逼真渲染提供了一种实用的替代方案。
🔬 方法详解
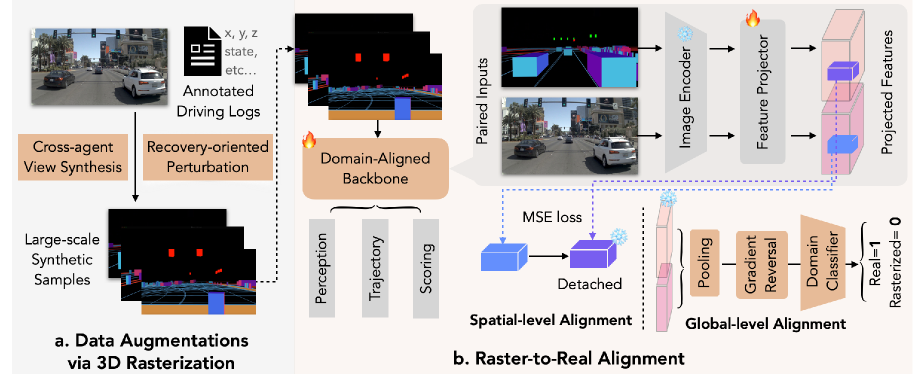
问题定义:端到端自动驾驶规划的模仿学习方法依赖于专家数据,在实际部署中缺乏从错误中恢复的能力。现有方法尝试使用逼真的渲染引擎或神经渲染生成更多数据,但计算成本高昂,难以扩展到大规模训练。因此,如何在保证语义信息的前提下,高效地生成用于训练的数据成为关键问题。
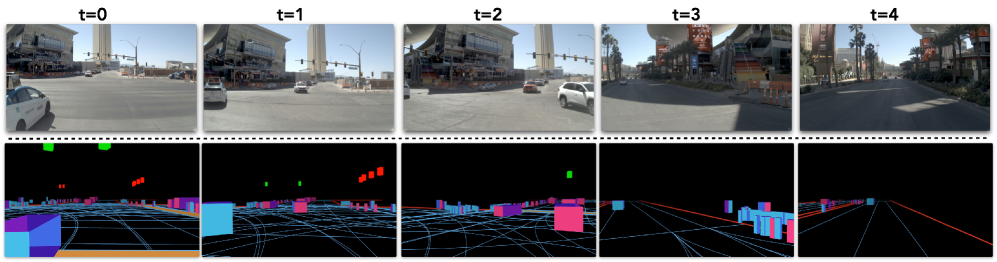
核心思路:论文的核心思路是用轻量级的3D光栅化技术替代高成本的逼真渲染,生成用于数据增强的合成视图。作者认为,对于端到端规划而言,语义保真度比照片级真实感更重要。通过光栅化带注释的图元,可以高效地生成反事实恢复操作和跨智能体视角的合成数据。
技术框架:RAP (Rasterization Augmented Planning) 包含两个主要模块:3D光栅化数据增强和光栅到真实特征空间对齐。首先,3D光栅化模块将场景中的物体表示为带语义信息的图元,并进行光栅化,生成合成视图。然后,光栅到真实特征空间对齐模块学习一个映射,将光栅化图像的特征与真实图像的特征对齐,从而减小sim-to-real的差距。最后,将增强后的数据用于训练端到端规划器。
关键创新:RAP的关键创新在于使用3D光栅化进行数据增强,并结合特征空间对齐来弥合模拟与现实的差距。与传统的基于渲染的数据增强方法相比,RAP更加高效且易于扩展。此外,RAP强调语义保真度而非照片级真实感,更符合端到端规划的需求。
关键设计:3D光栅化模块使用预定义的图元(例如,立方体、圆柱体)表示场景中的物体,并为每个图元分配语义标签。光栅到真实特征空间对齐模块使用对抗训练的方式,学习一个判别器来区分光栅化图像的特征和真实图像的特征,并使用一个生成器来生成与真实图像特征相似的光栅化图像特征。损失函数包括对抗损失、内容损失和风格损失。
🖼️ 关键图片

📊 实验亮点
RAP在NAVSIM v1/v2、Waymo Open Dataset Vision-based E2E Driving和Bench2Drive四个主要基准测试中均排名第一,显著提升了闭环鲁棒性和长尾泛化能力。实验结果表明,RAP方法在性能上优于现有的基于渲染的数据增强方法,证明了轻量级光栅化数据增强在端到端训练中的有效性。
🎯 应用场景
RAP方法可应用于自动驾驶系统的训练和验证,尤其是在数据稀缺或难以获取的场景下。通过生成大量的合成数据,可以提高自动驾驶系统的鲁棒性和泛化能力,降低开发成本。此外,该方法还可以应用于机器人导航、虚拟现实等领域。
📄 摘要(原文)
Imitation learning for end-to-end driving trains policies only on expert demonstrations. Once deployed in a closed loop, such policies lack recovery data: small mistakes cannot be corrected and quickly compound into failures. A promising direction is to generate alternative viewpoints and trajectories beyond the logged path. Prior work explores photorealistic digital twins via neural rendering or game engines, but these methods are prohibitively slow and costly, and thus mainly used for evaluation. In this work, we argue that photorealism is unnecessary for training end-to-end planners. What matters is semantic fidelity and scalability: driving depends on geometry and dynamics, not textures or lighting. Motivated by this, we propose 3D Rasterization, which replaces costly rendering with lightweight rasterization of annotated primitives, enabling augmentations such as counterfactual recovery maneuvers and cross-agent view synthesis. To transfer these synthetic views effectively to real-world deployment, we introduce a Raster-to-Real feature-space alignment that bridges the sim-to-real gap. Together, these components form Rasterization Augmented Planning (RAP), a scalable data augmentation pipeline for planning. RAP achieves state-of-the-art closed-loop robustness and long-tail generalization, ranking first on four major benchmarks: NAVSIM v1/v2, Waymo Open Dataset Vision-based E2E Driving, and Bench2Drive. Our results show that lightweight rasterization with feature alignment suffices to scale E2E training, offering a practical alternative to photorealistic rendering. Project page: https://alan-lanfeng.github.io/RAP/.