Learning from All: Concept Alignment for Autonomous Distillation from Multiple Drifting MLLMs
作者: Xiaoyu Yang, Jie Lu, En Yu
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-10-05
💡 一句话要点
提出基于概念对齐的自主蒸馏方法,解决多漂移MLLM教师模型的知识蒸馏问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 概念漂移 多模态大语言模型 自主偏好优化 概念对齐 多教师学习 推理轨迹 CXR-MAX数据集
📋 核心要点
- 现有MLLM知识蒸馏方法忽略了多教师模型推理轨迹中的概念漂移问题,导致学生模型性能下降。
- 提出“学习、比较、批判”范式,通过自主偏好优化(APO)实现概念对齐,解决教师模型漂移问题。
- 实验表明,该方法在一致性、鲁棒性和泛化性方面优于现有知识蒸馏方法,并构建了大规模数据集CXR-MAX。
📝 摘要(中文)
本文旨在解决从多模态大型语言模型(MLLM)中进行知识蒸馏时的一个关键但未被充分探索的挑战:多个漂移教师模型生成的推理轨迹表现出概念漂移,即它们的推理分布不可预测地演变,并将偏差传递给学生模型,最终损害其性能。为了解决这个问题,我们率先建立了概念漂移和知识蒸馏之间的理论联系,将来自多个MLLM教师的非平稳推理动态视为多流推理轨迹的下一个token预测。在概念漂移的指导下,我们引入了“学习、比较、批判”的范式,最终实现了自主偏好优化(APO)。在教师的积极指导下,学生模型首先通过比较多个教师来学习和自我提炼首选的思维方式。然后,它对教师的漂移推理进行批判性反思,通过APO执行概念对齐,最终产生一个鲁棒、一致和可泛化的模型。大量的实验证明了我们在知识蒸馏中一致性、鲁棒性和泛化性的优越性能。此外,我们还贡献了一个大规模数据集CXR-MAX(多教师对齐X射线),包含170,982个从基于MIMIC-CXR的公开MLLM中提取的蒸馏推理轨迹。
🔬 方法详解
问题定义:论文旨在解决从多个漂移的多模态大型语言模型(MLLM)教师模型中进行知识蒸馏时,由于教师模型推理轨迹中的概念漂移导致的性能下降问题。现有方法通常忽略了这种概念漂移,导致学生模型学习到不一致和有偏差的知识。
核心思路:论文的核心思路是将概念漂移与知识蒸馏联系起来,并将多教师模型的非平稳推理动态建模为多流推理轨迹的下一个token预测问题。通过“学习、比较、批判”的范式,学生模型可以在教师的指导下学习、比较和批判不同的推理轨迹,从而实现概念对齐,避免受到教师模型漂移的影响。
技术框架:整体框架包含三个主要阶段:学习阶段,学生模型学习多个教师模型的推理轨迹;比较阶段,学生模型比较不同教师模型的推理结果,选择更优的推理路径;批判阶段,学生模型对教师模型的漂移推理进行批判性反思,通过自主偏好优化(APO)进行概念对齐。APO的目标是使学生模型的推理结果与教师模型中更一致、更可靠的推理结果对齐。
关键创新:最重要的技术创新点在于将概念漂移引入到知识蒸馏中,并提出了基于自主偏好优化(APO)的概念对齐方法。与现有方法不同,该方法能够主动识别和纠正教师模型中的概念漂移,从而提高学生模型的鲁棒性和泛化能力。
关键设计:自主偏好优化(APO)是关键设计之一。具体而言,APO可能涉及设计一个奖励函数,该函数基于教师模型之间的一致性以及学生模型与教师模型之间的对齐程度来评估学生模型的推理结果。损失函数可能包含交叉熵损失,用于衡量学生模型预测的token与教师模型提供的token之间的差异,以及一个正则化项,用于惩罚学生模型与教师模型之间的不一致性。具体的网络结构细节未知,但可能涉及使用Transformer架构来建模推理轨迹。
🖼️ 关键图片
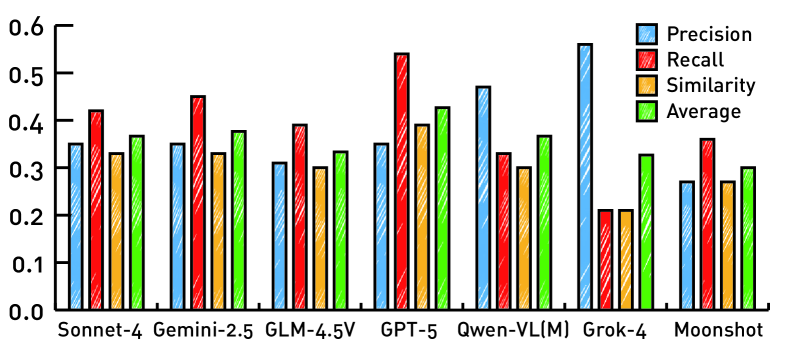
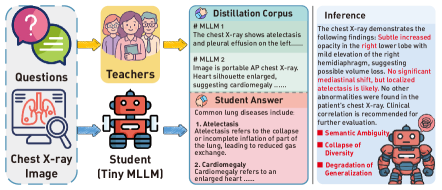

📊 实验亮点
论文通过大量实验验证了所提出方法的有效性。实验结果表明,该方法在一致性、鲁棒性和泛化性方面均优于现有的知识蒸馏方法。具体性能数据未知,但摘要强调了在知识蒸馏任务中,该方法能够显著提升模型的一致性、鲁棒性和泛化能力。
🎯 应用场景
该研究成果可应用于医疗诊断、智能客服、教育辅导等领域,尤其是在需要从多个专家或模型中学习知识的场景下。通过解决概念漂移问题,可以提高模型的鲁棒性和泛化能力,使其在复杂和动态的环境中表现更好。未来,该方法可以推广到其他类型的知识蒸馏任务中,例如从大型语言模型到小型语言模型的蒸馏。
📄 摘要(原文)
This paper identifies a critical yet underexplored challenge in distilling from multimodal large language models (MLLMs): the reasoning trajectories generated by multiple drifting teachers exhibit concept drift, whereby their reasoning distributions evolve unpredictably and transmit biases to the student model, ultimately compromising its performance. To tackle this issue, we pioneer a theoretical connection between concept drift and knowledge distillation, casting the non-stationary reasoning dynamics from multiple MLLM teachers as next-token prediction of multi-stream reasoning trajectories.Guided by concept drift, we introduce the "learn, compare, critique" paradigm, culminating in autonomous preference optimization (APO). Under the active guidance of the teachers, the student model first learns and self-distils preferred thinking by comparing multiple teachers. It then engages in critical reflection over the drifting inference from teachers, performing concept alignment through APO, ultimately yielding a robust, consistent, and generalizable model.Extensive experiments demonstrate our superior performance of consistency, robustness and generalization within knowledge distillation. Besides, we also contributed a large-scale dataset, CXR-MAX (Multi-teachers Alignment X-rays), comprising 170,982 distilled reasoning trajectories derived from publicly accessible MLLMs based on MIMIC-CXR. Our code and data are public at: https://anonymous.4open.science/r/Autonomous-Distillation/.