\textsc{GUI-Spotlight}: Adaptive Iterative Focus Refinement for Enhanced GUI Visual Grounding
作者: Bin Lei, Nuo Xu, Ali Payani, Mingyi Hong, Chunhua Liao, Yu Cao, Caiwen Ding
分类: cs.CV, cs.AI
发布日期: 2025-10-05
💡 一句话要点
GUI-Spotlight:自适应迭代聚焦优化,增强GUI视觉定位
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: GUI视觉定位 多模态学习 迭代聚焦 自适应工具调用 屏幕元素定位
📋 核心要点
- 现有MLLM在GUI交互中视觉定位精度不足,限制了其在复杂环境中的应用,尤其是在需要精确指针操作的场景。
- GUI-Spotlight通过迭代调用专用工具,动态缩小关注区域,实现对屏幕元素的精准定位,提升视觉定位准确性。
- 实验表明,GUI-Spotlight仅用少量训练数据,在ScreenSpot-Pro上超越了使用更多数据的V2P-7B和GTA-1-7B模型。
📝 摘要(中文)
多模态大型语言模型(MLLM)显著扩展了图形用户界面(GUI)系统的能力,使其超越了受控模拟环境,进入了跨多样平台的复杂现实世界。然而,实际应用仍然受到视觉定位可靠性的限制,即文本引用到屏幕上精确元素的映射。这种限制阻碍了系统准确执行指针级别的动作,如点击或拖动。为了解决这个问题,我们引入了GUI-Spotlight——一个为图像定位推理而训练的模型,它动态地调用多个专用工具来迭代地缩小其对屏幕相关区域的关注,从而大大提高视觉定位的准确性。在ScreenSpot-Pro基准测试中,仅使用18.5K训练样本训练的GUI-Spotlight达到了52.8%的准确率,超过了V2P-7B(使用9.6M训练样本的50.6%)和GTA-1-7B(使用1.56M训练样本的50.1%)。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型在图形用户界面中进行视觉定位时精度不足的问题。现有方法难以准确地将文本指令映射到屏幕上的特定元素,导致无法执行精确的点击、拖拽等操作。这种不准确性限制了MLLM在复杂、真实的GUI环境中的应用。
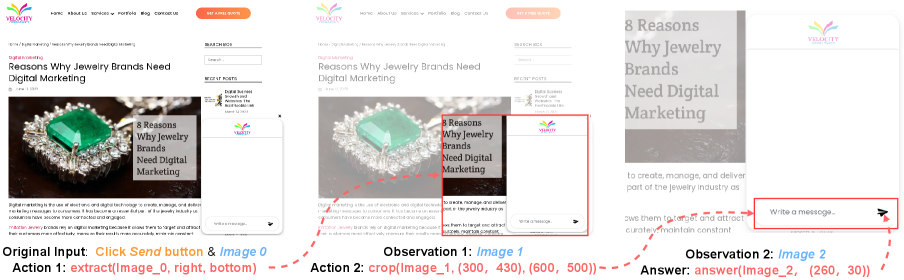
核心思路:论文的核心思路是采用一种自适应的迭代聚焦优化方法。模型不是一次性地尝试定位目标元素,而是通过多次迭代,逐步缩小搜索范围,最终精确定位到目标。这种方法类似于人眼在寻找目标时,会先大致定位区域,然后逐步聚焦到具体目标。
技术框架:GUI-Spotlight的技术框架包含一个主模型和多个专用工具。主模型负责接收文本指令和图像输入,并决定调用哪个专用工具。专用工具则负责执行特定的视觉定位任务,例如区域建议、目标检测等。整个过程是一个迭代循环,每次迭代都会更新模型对目标位置的估计,直到达到预定的精度或迭代次数上限。
关键创新:GUI-Spotlight的关键创新在于其动态调用专用工具的机制。模型可以根据当前的状态和任务需求,灵活地选择合适的工具,从而提高定位的效率和准确性。此外,迭代聚焦的策略也使得模型能够处理更加复杂的场景,例如目标元素被遮挡或背景干扰严重的情况。
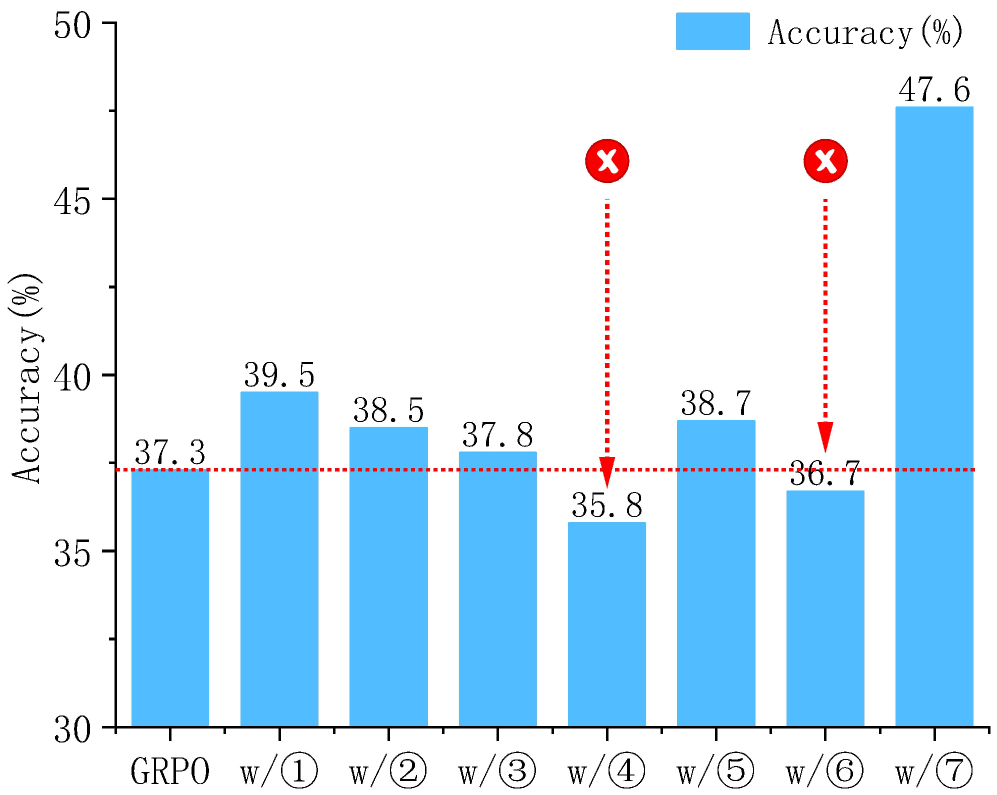
关键设计:论文中没有详细说明具体的参数设置、损失函数和网络结构等技术细节。但是,可以推测,模型可能使用了常见的视觉定位损失函数,例如交叉熵损失或IoU损失。专用工具可能采用了不同的网络结构,例如Faster R-CNN、YOLO等,以适应不同的视觉定位任务。迭代次数和精度阈值是重要的超参数,需要根据具体的应用场景进行调整。
🖼️ 关键图片
📊 实验亮点
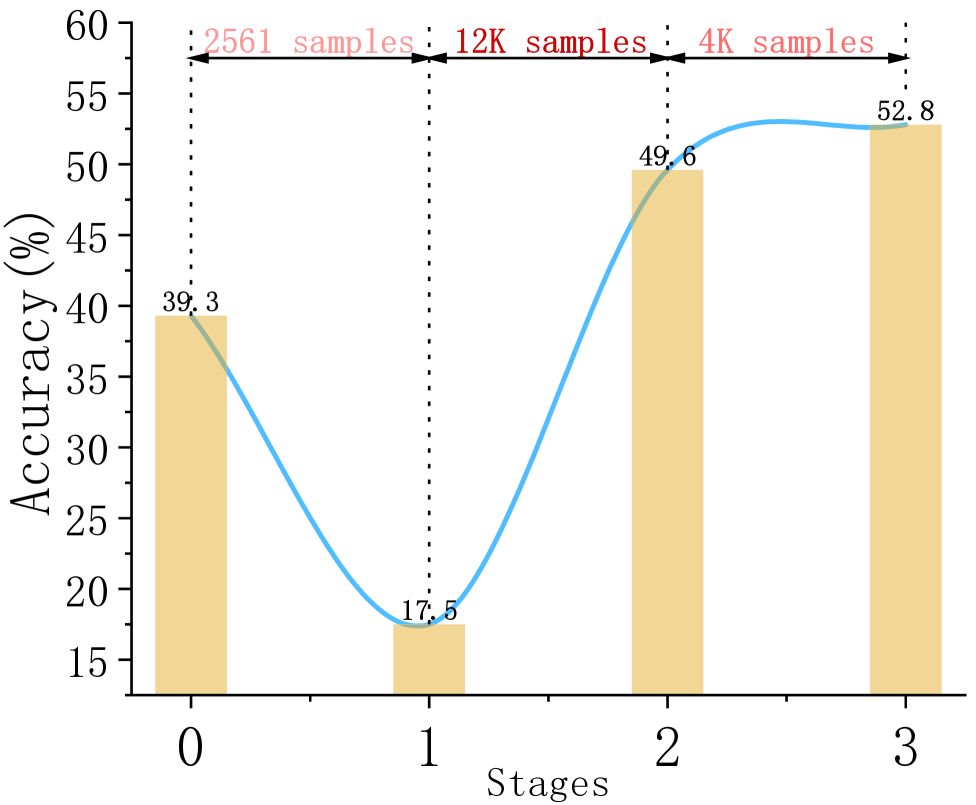
GUI-Spotlight在ScreenSpot-Pro基准测试中取得了显著的成果。仅使用18.5K的训练样本,就达到了52.8%的准确率,超过了使用更多训练样本的V2P-7B(50.6%,9.6M样本)和GTA-1-7B(50.1%,1.56M样本)。这表明GUI-Spotlight具有很高的样本效率和泛化能力,能够在有限的数据下学习到有效的视觉定位策略。
🎯 应用场景
GUI-Spotlight具有广泛的应用前景,可用于自动化测试、机器人流程自动化(RPA)、辅助技术等领域。它可以帮助自动化测试工具更准确地定位GUI元素,提高测试效率。在RPA中,它可以使机器人更可靠地与GUI界面进行交互,完成各种自动化任务。对于残疾人士,它可以提供更精确的屏幕阅读和控制功能,提高他们的生活质量。未来,该技术有望进一步发展,实现更智能、更人性化的GUI交互。
📄 摘要(原文)
Multimodal large language models (MLLMs) have markedly expanded the competence of graphical user-interface (GUI) systems, propelling them beyond controlled simulations into complex, real-world environments across diverse platforms. However, practical usefulness is still bounded by the reliability of visual grounding, i.e., mapping textual references to exact on-screen elements. This limitation prevents the system from accurately performing pointer-level actions such as clicking or dragging. To address it, we introduce GUI-Spotlight -- a model trained for image-grounded reasoning that dynamically invokes multiple specialized tools to iteratively narrow its focus to the relevant region of the screen, thereby substantially improving visual grounding accuracy. On the ScreenSpot-Pro benchmark, GUI-Spotlight trained with only 18.5K training samples achieves 52.8\% accuracy, surpassing V2P-7B (50.6\% with 9.6M training samples) and GTA-1-7B (50.1\% with 1.56M training samples).