Enhanced Self-Distillation Framework for Efficient Spiking Neural Network Training
作者: Xiaochen Zhao, Chengting Yu, Kairong Yu, Lei Liu, Aili Wang
分类: cs.CV
发布日期: 2025-10-04
🔗 代码/项目: GITHUB
💡 一句话要点
提出增强自蒸馏框架以提高脉冲神经网络训练效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 脉冲神经网络 自蒸馏 训练效率 神经形态计算 深度学习
📋 核心要点
- 现有的脉冲神经网络训练方法在性能和计算效率上均不及人工神经网络,且面临显著的计算和内存开销。
- 本文提出了一种增强自蒸馏框架,通过将中间层发火率投影到轻量级ANN分支上,利用自生成的高质量知识优化模型。
- 在多个数据集上的实验结果表明,该方法显著降低了训练复杂度,同时提升了SNN的性能。
📝 摘要(中文)
脉冲神经网络(SNN)因其稀疏激活模式在神经形态硬件上展现出卓越的能效。然而,基于代理梯度和时间反向传播(BPTT)的传统训练方法在性能上落后于人工神经网络(ANN),并且在时间维度上计算和内存开销显著增加。为在有限计算资源下实现高性能SNN训练,本文提出了一种增强自蒸馏框架,与基于速率的反向传播联合优化。具体而言,中间SNN层的发火率被投影到轻量级ANN分支上,模型自生成的高质量知识用于通过ANN路径优化子结构。与传统自蒸馏范式不同,我们观察到低质量自生成知识可能阻碍收敛。为此,我们将教师信号解耦为可靠和不可靠组件,确保仅使用可靠知识指导模型优化。大量在CIFAR-10、CIFAR-100、CIFAR10-DVS和ImageNet上的实验表明,我们的方法在减少训练复杂度的同时实现了高性能SNN训练。
🔬 方法详解
问题定义:本文旨在解决脉冲神经网络(SNN)训练中的性能不足和计算开销问题。现有基于代理梯度和BPTT的方法在时间维度上计算和内存需求呈线性增长,限制了其在资源受限环境下的应用。
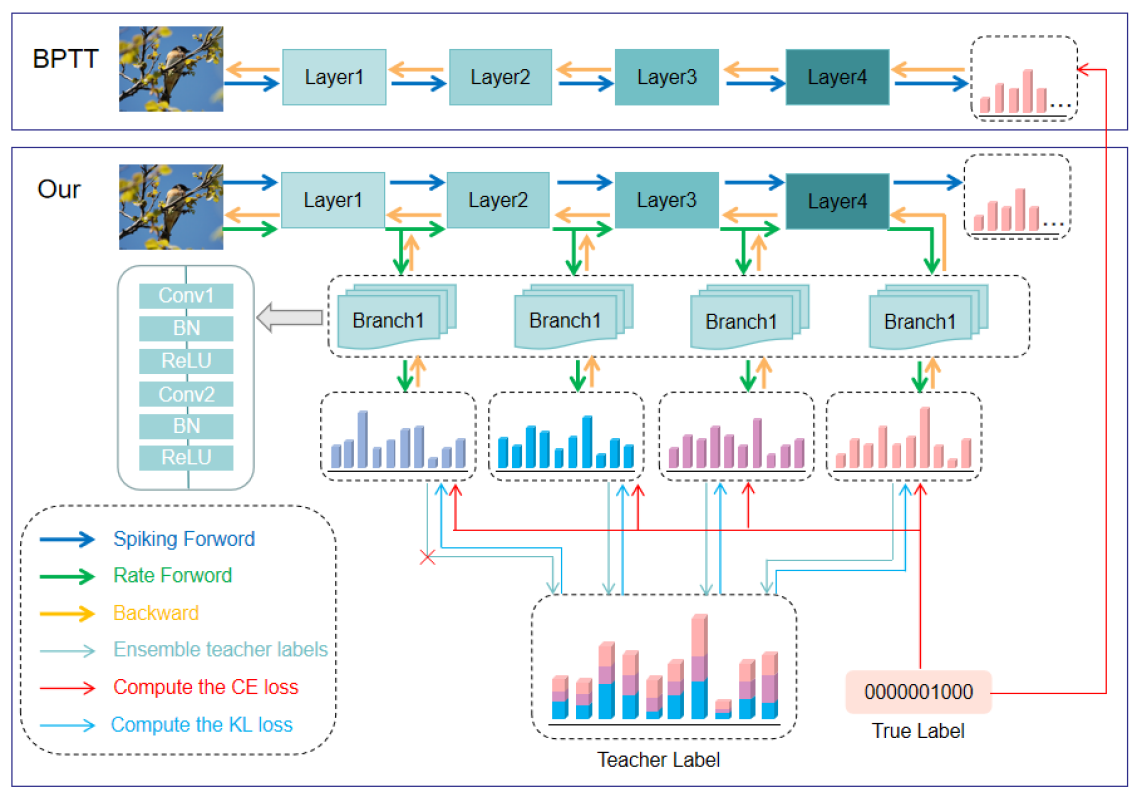
核心思路:提出的增强自蒸馏框架通过将SNN中间层的发火率映射到轻量级的人工神经网络(ANN)分支上,利用自生成的高质量知识来优化模型的子结构,从而提高训练效率和性能。
技术框架:该框架包括两个主要模块:一是通过ANN分支获取中间层发火率,二是将教师信号解耦为可靠和不可靠部分,确保优化过程中只使用可靠知识。
关键创新:最重要的创新在于将自蒸馏过程中的知识质量进行区分,避免低质量知识对模型收敛的负面影响,这一设计与传统自蒸馏方法有本质区别。
关键设计:在参数设置上,采用了适应性损失函数来平衡可靠与不可靠知识的影响,同时优化了网络结构以适应轻量级ANN的需求。具体的网络架构和损失函数设计在实验中经过多次验证,以确保最佳性能。
🖼️ 关键图片
📊 实验亮点
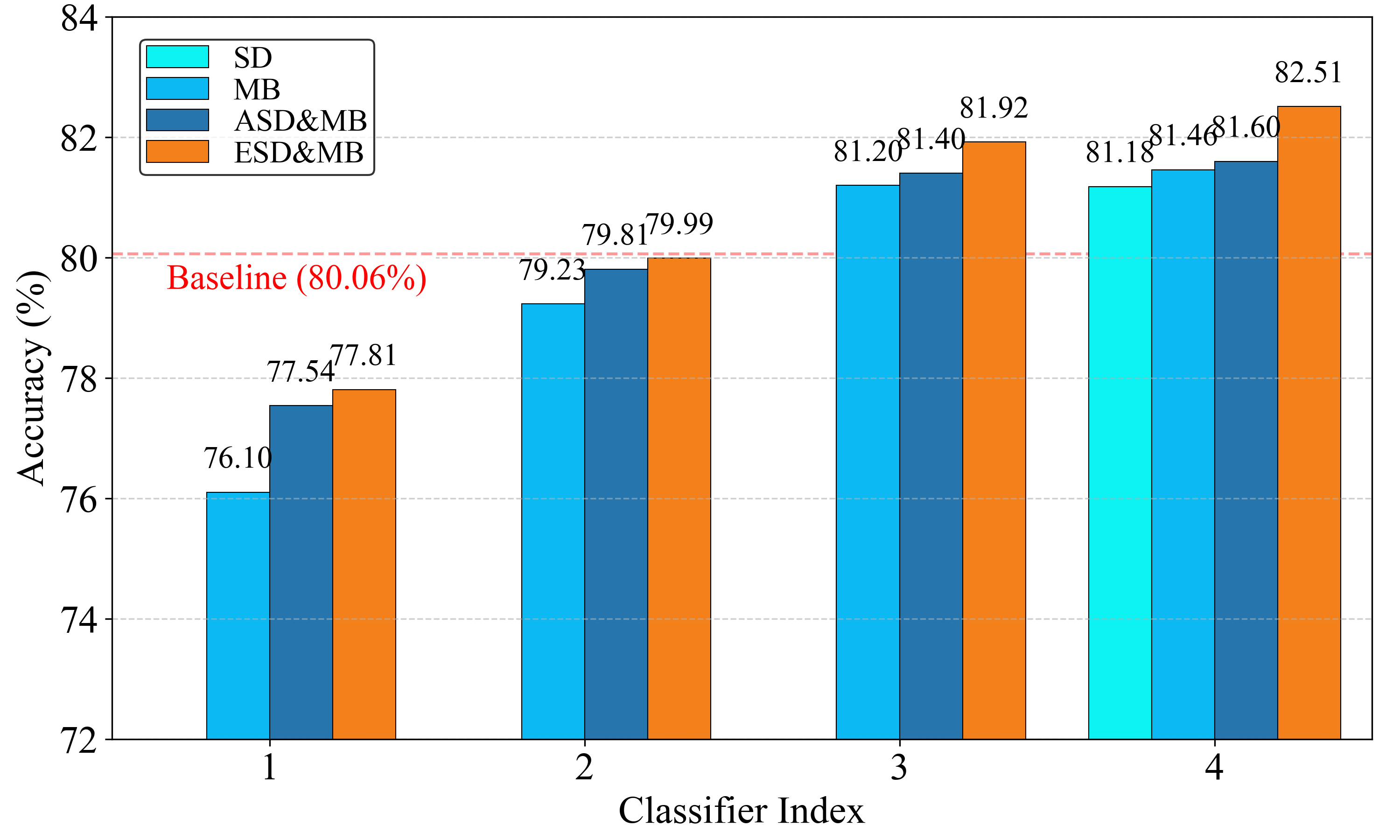
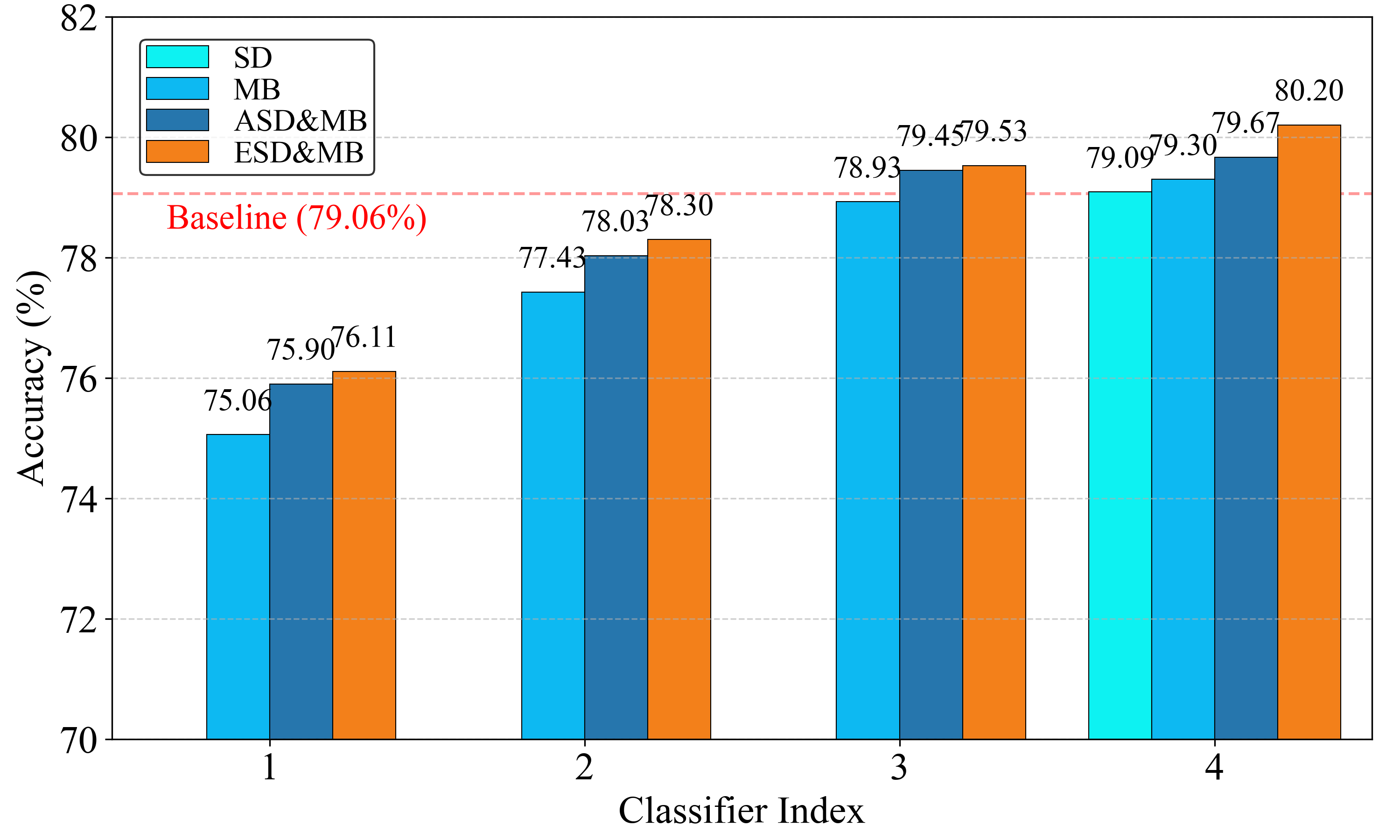
在CIFAR-10、CIFAR-100、CIFAR10-DVS和ImageNet等数据集上的实验结果显示,提出的方法在训练复杂度上显著降低,同时在性能上超过了传统的训练方法,具体提升幅度未知。
🎯 应用场景
该研究的潜在应用领域包括智能传感器、机器人控制和边缘计算等场景,能够在资源受限的环境中实现高效的脉冲神经网络训练,推动神经形态计算的发展。未来,该框架有望在更广泛的应用中提升SNN的实际效能和应用价值。
📄 摘要(原文)
Spiking Neural Networks (SNNs) exhibit exceptional energy efficiency on neuromorphic hardware due to their sparse activation patterns. However, conventional training methods based on surrogate gradients and Backpropagation Through Time (BPTT) not only lag behind Artificial Neural Networks (ANNs) in performance, but also incur significant computational and memory overheads that grow linearly with the temporal dimension. To enable high-performance SNN training under limited computational resources, we propose an enhanced self-distillation framework, jointly optimized with rate-based backpropagation. Specifically, the firing rates of intermediate SNN layers are projected onto lightweight ANN branches, and high-quality knowledge generated by the model itself is used to optimize substructures through the ANN pathways. Unlike traditional self-distillation paradigms, we observe that low-quality self-generated knowledge may hinder convergence. To address this, we decouple the teacher signal into reliable and unreliable components, ensuring that only reliable knowledge is used to guide the optimization of the model. Extensive experiments on CIFAR-10, CIFAR-100, CIFAR10-DVS, and ImageNet demonstrate that our method reduces training complexity while achieving high-performance SNN training. Our code is available at https://github.com/Intelli-Chip-Lab/enhanced-self-distillation-framework-for-snn.