Exploring Instruction Data Quality for Explainable Image Quality Assessment
作者: Yunhao Li, Sijing Wu, Huiyu Duan, Yucheng Zhu, Qi Jia, Guangtao Zhai
分类: cs.CV
发布日期: 2025-10-04
💡 一句话要点
针对可解释图像质量评估,提出基于聚类的数据选择方法IQA-Select,提升效率并优化性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可解释图像质量评估 指令调优 数据选择 聚类分析 多模态学习
📋 核心要点
- 现有可解释图像质量评估方法依赖大规模指令调优数据,但存在计算成本高和数据冗余问题。
- 论文提出基于聚类的数据选择框架IQA-Select,通过选择高质量子集提升模型性能和效率。
- 实验表明,IQA-Select仅用10%的数据即可超越全量微调,在Q-Bench和AesBench上分别达到102.1%和103.7%的性能。
📝 摘要(中文)
近年来,强大的多模态大型语言模型(MLLM)快速发展,可解释图像质量评估(IQA)逐渐流行,旨在提供与图像质量相关的描述和答案。为了实现这一目标,现有方法试图构建大规模指令调优数据集,以遵循著名的缩放定律,赋予MLLM质量感知能力。然而,大量的指令调优数据可能导致巨大的计算成本和冗余数据,进而损害模型性能。为了解决这个问题,本文挑战了缩放定律,并系统地研究了指令调优数据集的数据质量在可解释IQA中的作用。利用强大的预训练MLLM,我们首先研究了使用不同大小的指令调优数据进行微调后模型性能的变化。我们发现,使用适当的比例随机选择数据集的子集,甚至可以比使用整个指令调优数据集进行训练获得更好的结果,这表明当前可解释IQA指令调优数据存在冗余。除了随机抽样子集外,我们还提出了一种基于聚类的数据选择框架,包括三个阶段:聚类特征提取、聚类配额分配和聚类抽样策略。然后,我们系统地分析了每个阶段的选择,并提出了一种简单而高效的用于可解释IQA的数据选择方法IQA-Select。实验结果表明,在Q-Bench和AesBench中,仅使用10%的选定数据,IQA-Select即可分别达到完整微调的102.1%和103.7%的性能,从而显著降低计算成本,同时获得更好的性能。
🔬 方法详解
问题定义:现有可解释图像质量评估方法依赖于大规模指令调优数据集,以提升多模态大型语言模型(MLLM)的质量感知能力。然而,这种方法面临着两个主要问题:一是计算成本高昂,训练庞大的数据集需要大量的计算资源;二是数据集中存在冗余信息,并非所有数据都对模型性能提升有贡献,反而可能损害模型性能。因此,如何高效地利用有限的计算资源,选择最具代表性和信息量的指令数据,是当前可解释IQA面临的关键挑战。
核心思路:论文的核心思路是挑战传统的“缩放定律”,即并非数据越多越好,而是数据质量更为重要。通过精心选择高质量的指令数据子集,可以在显著降低计算成本的同时,甚至超越使用全量数据进行训练的效果。论文提出了一种基于聚类的数据选择框架,旨在从原始数据集中筛选出最具代表性和信息量的样本,从而提高训练效率和模型性能。
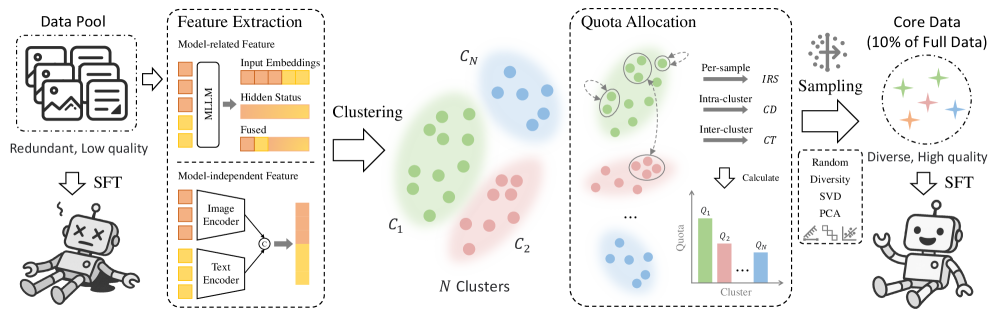
技术框架:IQA-Select框架包含三个主要阶段: 1. 聚类特征提取:首先,从指令数据中提取特征,用于后续的聚类分析。具体实现方式未知,但推测可能使用预训练模型的embedding作为特征。 2. 聚类配额分配:根据每个簇的重要性,为每个簇分配不同的抽样配额。重要性高的簇分配更多的抽样名额,以保证其代表性样本能够被选中。 3. 聚类抽样策略:在每个簇内,根据一定的策略进行抽样,选择最具代表性的样本。具体抽样策略未知,但可能包括随机抽样、基于距离的抽样等。
关键创新:该方法的核心创新在于,它打破了可解释IQA领域对大规模数据的盲目追求,转而关注数据质量。通过聚类分析,能够识别出数据集中最具代表性和信息量的样本,从而避免了冗余数据的干扰,提高了训练效率和模型性能。此外,该框架具有通用性,可以灵活地调整各个阶段的策略,以适应不同的数据集和任务需求。
关键设计:论文中提到对框架的三个阶段进行了系统分析,并提出了简单但高效的数据选择方法IQA-Select。具体的技术细节,例如特征提取方法、聚类算法、配额分配策略和抽样策略,在摘要中没有详细说明。这些细节是实现IQA-Select的关键,需要参考论文正文才能了解。
🖼️ 关键图片

📊 实验亮点
实验结果表明,IQA-Select仅使用10%的选定数据,即可在Q-Bench和AesBench数据集上分别达到完整微调的102.1%和103.7%的性能。这意味着在显著降低计算成本的同时,模型性能甚至有所提升,验证了该方法在可解释图像质量评估任务中的有效性。
🎯 应用场景
该研究成果可广泛应用于图像质量评估、图像增强、图像修复等领域。通过选择高质量的训练数据,可以有效提升相关AI模型的性能和效率,降低计算成本。此外,该方法还可以应用于其他需要大规模指令调优的多模态学习任务中,具有重要的实际应用价值和潜力。
📄 摘要(原文)
In recent years, with the rapid development of powerful multimodal large language models (MLLMs), explainable image quality assessment (IQA) has gradually become popular, aiming at providing quality-related descriptions and answers of images. To achieve this goal, recent methods seek to construct a large-scale instruction tuning dataset to empower the MLLM with quality perception ability following the well-known scaling law. However, a large amount of instruction tuning data may cause substantial computational costs and redundant data, which in turn will cause harm to the performance of the model. To cope with this problem, in this paper, we challenge the scaling law and systematically investigate the role of data quality of the instruction tuning dataset for explainable IQA. Using a powerful pre-trained MLLM, we first investigate the changes in model performance after fine-tuning with different sizes of instruction tuning data. We find that selecting a subset of the data set randomly using an appropriate ratio can even lead to better results than training with the entire instruction tuning dataset, demonstrating the redundancy of current explainable IQA instruction tuning data. Beyond randomly sampling a subset, we propose a clustering-based data selection framework with three stages: clustering feature extraction, cluster quota allocation, and cluster sampling strategy. Then we systematically analyze the choices of each stage and propose a simple but efficient data selection method IQA-Select for explainable IQA. The experimental results demonstrate that IQA-Select can achieve 102.1% and 103.7% performance of full fine-tuning using only 10% selected data in Q-Bench and AesBench respectively, significantly reducing computational costs while achieving better performance.