UGround: Towards Unified Visual Grounding with Unrolled Transformers
作者: Rui Qian, Xin Yin, Chuanhang Deng, Zhiyuan Peng, Jian Xiong, Wei Zhai, Dejing Dou
分类: cs.CV
发布日期: 2025-10-04
备注: https://github.com/rui-qian/UGround
🔗 代码/项目: GITHUB
💡 一句话要点
提出UGround,通过解缠Transformer动态选择中间层,实现统一的视觉定位。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉定位 Transformer 解缠表示 强化学习 Mask as Prompt 随机跳跃连接 语义分割 视觉推理
📋 核心要点
- 现有视觉定位方法依赖固定Transformer最后一层,易累积误差且缺乏中间修正。
- UGround通过随机跳跃连接动态选择Transformer中间层,并使用Mask作为Prompt。
- 实验表明UGround在多种视觉定位任务上有效,包括推理分割和多目标定位。
📝 摘要(中文)
本文提出了一种统一的视觉定位范式UGround,它动态地选择解缠Transformer的中间层作为“mask as prompt”,从而区别于利用固定最后一层隐藏层作为“
🔬 方法详解
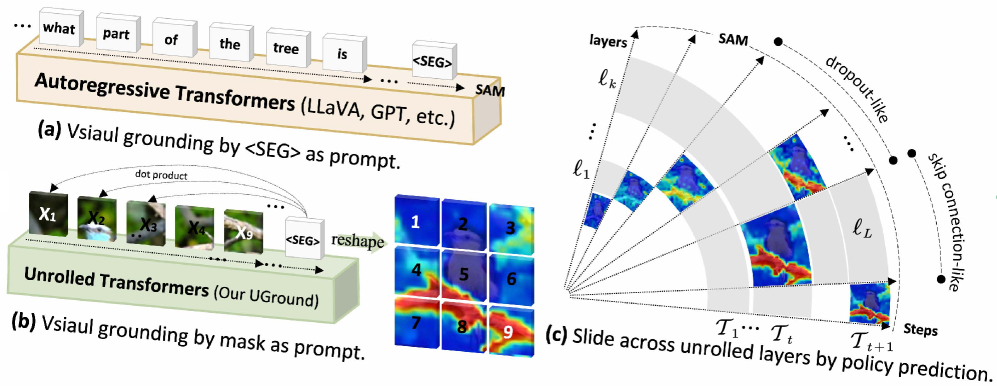
问题定义:现有视觉定位方法通常使用Transformer的最后一层隐藏层作为视觉信息的来源,这导致两个主要问题:一是逐层传播的误差会累积放大,缺乏中间层的修正;二是直接将文本嵌入投影到视觉空间,缺乏明确的空间线索,影响定位精度。
核心思路:UGround的核心思路是动态地选择Transformer的中间层作为视觉信息的来源,并利用Mask作为Prompt,为视觉模型提供更明确的空间线索。通过随机跳跃连接,模型可以根据输入动态选择合适的中间层,从而避免误差累积。同时,利用Mask作为Prompt,将文本信息与图像的空间信息相结合,提高定位的准确性。
技术框架:UGround的整体框架包括以下几个主要模块:1) 解缠Transformer:用于提取图像的视觉特征,并生成不同层的隐藏表示;2) 随机跳跃连接(SSC):通过强化学习策略,动态选择Transformer的中间层;3) Mask as Prompt (MasP):利用选定隐藏层的信息生成Mask,并将其作为Prompt输入到视觉模型(如SAM)中;4) 视觉模型(如SAM):根据Mask生成最终的分割结果。
关键创新:UGround最重要的技术创新点在于动态层选择和Mask作为Prompt。动态层选择允许模型根据输入自适应地选择合适的视觉特征层,避免了固定最后一层带来的误差累积问题。Mask作为Prompt则将文本信息与图像的空间信息相结合,为视觉模型提供了更明确的指导,提高了定位的准确性。与现有方法相比,UGround不再依赖固定的最后一层,而是能够充分利用Transformer中间层的信息,从而实现更准确的视觉定位。
关键设计:随机跳跃连接(SSC)使用强化学习进行训练,奖励函数旨在鼓励选择更有效的中间层。Mask as Prompt (MasP) 使用相似度图作为软logit mask,引导SAM生成分割结果。具体来说,相似度图是通过计算
🖼️ 关键图片


📊 实验亮点
UGround在多个视觉定位任务上取得了显著的性能提升。例如,在推理分割任务上,UGround首次实现了统一框架下的有效分割,并在多目标定位任务上表现出强大的泛化能力。实验结果表明,UGround能够有效地利用Transformer中间层的信息,并生成更准确的分割结果。
🎯 应用场景
UGround具有广泛的应用前景,包括智能交通、机器人导航、图像编辑、视频监控等领域。例如,在智能交通中,UGround可以用于定位交通标志和行人,提高自动驾驶系统的安全性。在机器人导航中,UGround可以用于识别和定位目标物体,帮助机器人完成复杂的任务。在图像编辑中,UGround可以用于精确地分割图像中的物体,方便用户进行编辑和修改。
📄 摘要(原文)
We present UGround, a \textbf{U}nified visual \textbf{Ground}ing paradigm that dynamically selects intermediate layers across \textbf{U}nrolled transformers as
mask as prompt'', diverging from the prevailing pipeline that leverages the fixed last hidden layer as\texttt{} as prompt''. UGround addresses two primary challenges posed by the prevailing paradigm: (1) its reliance on the fixed last hidden layer, which sequentially amplifies cumulative errors arising from layer-by-layer propagation without intermediate correction, and (2) its use of \texttt{ } as a prompt, which implicitly projects textual embeddings into visual space without explicit spatial cues (\eg, coordinates). Central to UGround is Policy-Prompted Masking, which comprises two key components: Stochastic Skip Connection (SSC) and Mask as Prompt (MasP). SSC is a reinforcement learning policy that, via stochastic sampling, allows each \texttt{ } token to slide across unrolled transformer layers, enabling dynamic layer selection at which it connects to the vision model (\eg, SAM) in a skip-connection fashion. Given the selected hidden layer, MasP uses the similarity map derived from the \texttt{ } token and image tokens as a soft logit mask to prompt SAM for mask generation, offering explicit spatial cues through its activation regions. To validate the effectiveness of UGround, we, for the first time, have unified visual grounding within a single framework from an attribute perspective, spanning from traditional refer expression segmentation to newly proposed reasoning segmentation, single-target to multi-target, positive query to false premise (empty target). All codes and models are publicly available at \href{https://github.com/rui-qian/UGround}{https://github.com/rui-qian/UGround}.