LIBERO-PRO: Towards Robust and Fair Evaluation of Vision-Language-Action Models Beyond Memorization
作者: Xueyang Zhou, Yangming Xu, Guiyao Tie, Yongchao Chen, Guowen Zhang, Duanfeng Chu, Pan Zhou, Lichao Sun
分类: cs.CV, cs.RO
发布日期: 2025-10-04
备注: 12 pages,7 figures, 5 tables
🔗 代码/项目: GITHUB
💡 一句话要点
LIBERO-PRO:提升视觉-语言-动作模型评估的鲁棒性和公平性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 VLA模型 基准测试 鲁棒性评估 泛化能力 机器人操作 环境感知
📋 核心要点
- 现有VLA模型评估基准LIBERO存在过度依赖记忆、泛化能力评估不足的问题。
- LIBERO-PRO通过引入对象、状态、指令和环境扰动,系统评估模型的鲁棒性和泛化能力。
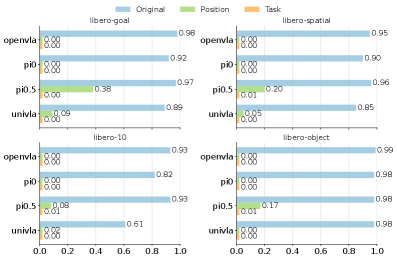
- 实验表明,现有模型在LIBERO-PRO的扰动下性能显著下降,暴露了其严重依赖记忆的问题。
📝 摘要(中文)
LIBERO已成为评估视觉-语言-动作(VLA)模型的广泛采用的基准。然而,其当前的训练和评估设置存在问题,常常导致过高的性能估计,并阻碍了公平的模型比较。为了解决这些问题,我们引入了LIBERO-PRO,这是一个扩展的LIBERO基准,它在四个维度上系统地评估模型在合理扰动下的性能:操纵对象、初始状态、任务指令和环境。实验结果表明,尽管现有模型在标准LIBERO评估下达到了90%以上的准确率,但在我们的广义设置下,它们的性能崩溃到0.0%。至关重要的是,这种差异揭示了模型对训练集中动作序列和环境布局的死记硬背,而不是真正的任务理解或环境感知。例如,当目标对象被不相关的物品替换时,模型仍然坚持执行抓取动作,并且即使给出损坏的指令甚至混乱的token,它们的输出也保持不变。这些发现暴露了当前评估实践中的严重缺陷,我们呼吁社区放弃误导性的方法,转而采用对模型泛化和理解的稳健评估。我们的代码可在https://github.com/Zxy-MLlab/LIBERO-PRO获得。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型的评估基准,如LIBERO,存在过度依赖训练数据记忆的问题。模型在标准评估下表现良好,但缺乏对环境和任务的真正理解,导致泛化能力不足。现有评估方法无法有效区分模型是真正理解了任务,还是仅仅记住了训练数据中的特定动作序列和环境布局。
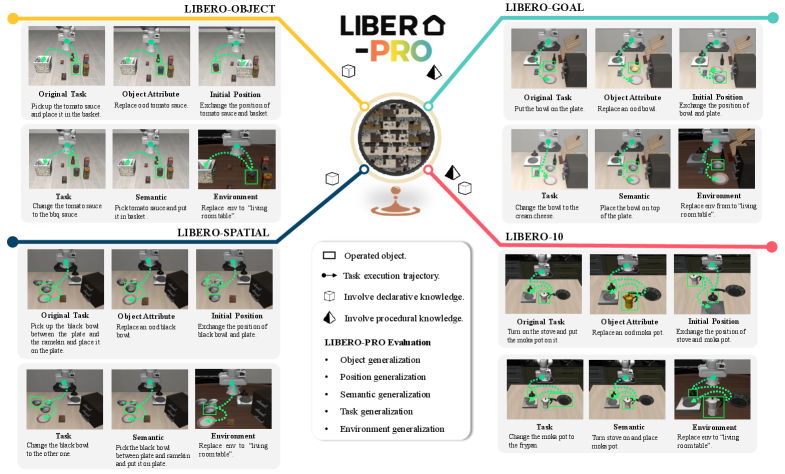
核心思路:LIBERO-PRO的核心思路是通过引入系统性的扰动,来挑战模型对训练数据的过度依赖,从而更准确地评估模型的泛化能力和鲁棒性。这些扰动包括改变操纵对象、初始状态、任务指令和环境,迫使模型在非理想条件下执行任务,从而暴露其对环境和任务理解的不足。
技术框架:LIBERO-PRO在LIBERO的基础上进行了扩展,主要包含以下几个模块:1) 环境扰动模块:用于改变环境的布局和视觉特征。2) 对象扰动模块:用于替换或修改任务相关的对象。3) 状态扰动模块:用于改变机器人的初始状态。4) 指令扰动模块:用于修改或损坏任务指令。模型在这些扰动后的环境中执行任务,并根据其完成任务的准确率来评估其性能。
关键创新:LIBERO-PRO的关键创新在于其系统性的扰动设计,能够有效地暴露模型对训练数据记忆的依赖,并更准确地评估模型的泛化能力。与传统的评估方法相比,LIBERO-PRO能够更真实地反映模型在实际应用中的性能。
关键设计:LIBERO-PRO的关键设计包括:1) 扰动类型的选择:选择了对象、状态、指令和环境这四个维度进行扰动,覆盖了VLA模型可能遇到的主要挑战。2) 扰动强度的控制:对每种扰动都设置了不同的强度级别,以便更细致地评估模型的鲁棒性。3) 评估指标的设计:除了传统的准确率之外,还引入了新的评估指标,用于衡量模型对不同类型扰动的敏感程度。
🖼️ 关键图片

📊 实验亮点
实验结果显示,现有模型在标准LIBERO评估中达到90%以上的准确率,但在LIBERO-PRO的扰动下,性能骤降至0%。这表明现有模型严重依赖对训练数据的记忆,缺乏真正的任务理解和环境感知能力。LIBERO-PRO能够有效区分模型的泛化能力,为VLA模型的研究提供了更可靠的评估工具。
🎯 应用场景
LIBERO-PRO可用于更可靠地评估和比较VLA模型,推动模型向更强的泛化能力和鲁棒性发展。其评估方法可应用于机器人操作、自动驾驶、智能助手等领域,帮助开发出真正理解环境和任务的智能系统。此外,该基准可以促进对VLA模型内在机制的理解,并指导模型设计和训练策略的改进。
📄 摘要(原文)
LIBERO has emerged as a widely adopted benchmark for evaluating Vision-Language-Action (VLA) models; however, its current training and evaluation settings are problematic, often leading to inflated performance estimates and preventing fair model comparison. To address these issues, we introduce LIBERO-PRO, an extended LIBERO benchmark that systematically evaluates model performance under reasonable perturbations across four dimensions: manipulated objects, initial states, task instructions, and environments. Experimental results reveal that, although existing models achieve over 90% accuracy under the standard LIBERO evaluation, their performance collapses to 0.0% under our generalized setting. Crucially, this discrepancy exposes the models' reliance on rote memorization of action sequences and environment layouts from the training set, rather than genuine task understanding or environmental perception. For instance, models persist in executing grasping actions when the target object is replaced with irrelevant items, and their outputs remain unchanged even when given corrupted instructions or even messy tokens. These findings expose the severe flaws in current evaluation practices, and we call on the community to abandon misleading methodologies in favor of robust assessments of model generalization and comprehension. Our code is available at: https://github.com/Zxy-MLlab/LIBERO-PRO.