Unsupervised Transformer Pre-Training for Images: Self-Distillation, Mean Teachers, and Random Crops
作者: Mattia Scardecchia
分类: cs.CV, cs.LG, eess.IV
发布日期: 2025-10-04
💡 一句话要点
DINOv2深度解读:基于自蒸馏、Mean Teacher和随机裁剪的无监督Transformer图像预训练
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自监督学习 Transformer 图像预训练 自蒸馏 Mean Teacher 多裁剪视图 视觉特征学习
📋 核心要点
- 现有自监督学习方法在捕捉图像高级语义和精细空间结构方面仍有提升空间,尤其是在通用视觉特征学习方面。
- DINOv2的核心在于多裁剪视图增强和使用Mean Teacher的自蒸馏,通过这种方式学习更鲁棒和泛化的视觉特征。
- DINOv2在多个下游任务中超越了其他自监督和弱监督方法,展现了Transformer骨干网络学习到的特征的优越性。
📝 摘要(中文)
近年来,自监督学习(SSL)的进步使得学习通用视觉特征成为可能,这些特征既能捕捉图像的高级语义,又能捕捉精细的空间结构。其中,DINOv2通过在大多数基准测试中超越弱监督方法(WSL),如OpenCLIP,确立了新的技术水平。本文探讨了DINOv2方法背后的核心思想,即多裁剪视图增强和使用Mean Teacher的自蒸馏,并追溯了它们在先前工作中的发展。然后,我们将DINO和DINOv2的性能与各种下游任务中的其他SSL和WSL方法进行了比较,并强调了它们使用Transformer骨干网络学习到的特征的一些显著涌现特性。最后,我们简要讨论了DINOv2的局限性、其影响以及未来的研究方向。
🔬 方法详解
问题定义:论文主要关注如何通过自监督学习方法,提升图像的通用视觉特征表示能力。现有方法在捕捉图像的高级语义和精细空间结构方面存在不足,尤其是在下游任务中的泛化能力有待提高。DINOv2旨在解决这一问题,学习更具鲁棒性和泛化性的视觉特征。
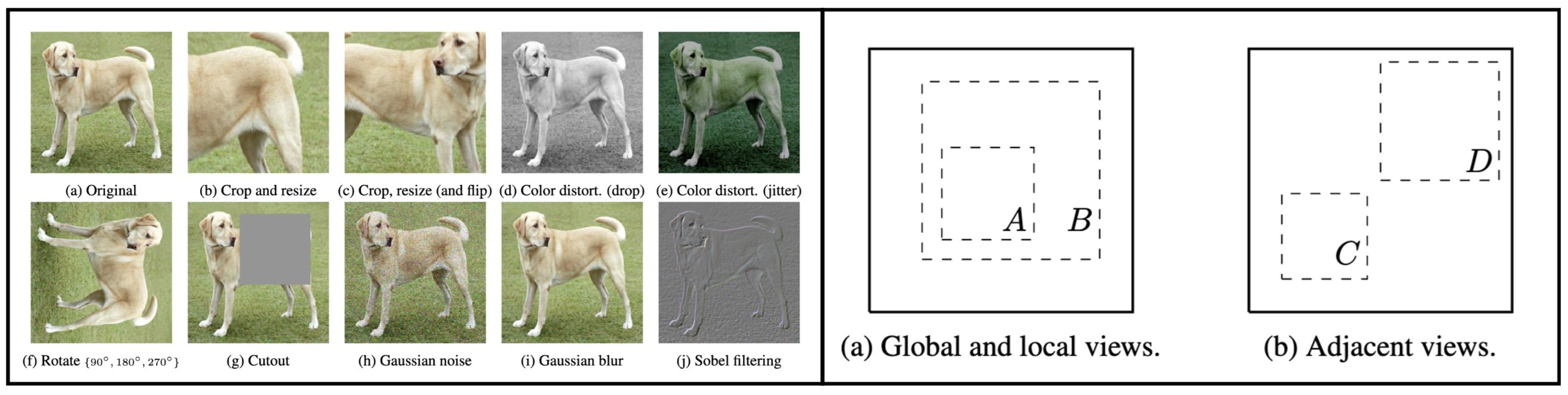
核心思路:DINOv2的核心思路是利用自蒸馏框架,结合多裁剪视图增强和Mean Teacher模型。通过让学生网络学习教师网络的输出来进行自监督训练,同时使用多裁剪视图增强来增加数据的多样性,从而提高模型的泛化能力。Mean Teacher模型则通过对学生网络进行指数移动平均,提供更稳定的训练目标。
技术框架:DINOv2的整体框架包括以下几个主要模块:1) 多裁剪视图生成模块,对输入图像进行不同尺度的随机裁剪,生成多个视图;2) 学生网络和教师网络,学生网络用于学习图像特征,教师网络是学生网络的指数移动平均,提供训练目标;3) 自蒸馏损失函数,用于衡量学生网络和教师网络输出之间的差异,指导学生网络学习;4) Transformer骨干网络,用于提取图像特征。
关键创新:DINOv2的关键创新在于将多裁剪视图增强、Mean Teacher和自蒸馏框架有效地结合起来,从而学习到更鲁棒和泛化的视觉特征。与之前的DINO相比,DINOv2在模型结构和训练策略上进行了优化,进一步提升了性能。此外,DINOv2展现了Transformer骨干网络在自监督学习中的强大潜力。
关键设计:DINOv2的关键设计包括:1) 使用ViT或ResNet作为骨干网络;2) 采用多裁剪策略,包括全局视图和局部视图;3) 使用交叉熵损失函数进行自蒸馏;4) 使用动量更新策略更新教师网络的参数;5) 使用LayerScale初始化方法稳定训练过程。
🖼️ 关键图片


📊 实验亮点
DINOv2在多个下游任务中取得了显著的性能提升,例如在ImageNet分类任务中,DINOv2超越了之前的自监督学习方法,甚至可以与一些弱监督方法相媲美。此外,DINOv2在目标检测和图像分割等任务中也表现出色,展现了其强大的泛化能力。
🎯 应用场景
DINOv2学习到的通用视觉特征可以广泛应用于各种计算机视觉任务,例如图像分类、目标检测、图像分割等。其强大的特征表示能力可以提升这些任务的性能,并降低对标注数据的依赖。此外,DINOv2还可以用于图像检索、图像生成等领域,具有广阔的应用前景。
📄 摘要(原文)
Recent advances in self-supervised learning (SSL) have made it possible to learn general-purpose visual features that capture both the high-level semantics and the fine-grained spatial structure of images. Most notably, the recent DINOv2 has established a new state of the art by surpassing weakly supervised methods (WSL) like OpenCLIP on most benchmarks. In this survey, we examine the core ideas behind its approach, multi-crop view augmentation and self-distillation with a mean teacher, and trace their development in previous work. We then compare the performance of DINO and DINOv2 with other SSL and WSL methods across various downstream tasks, and highlight some remarkable emergent properties of their learned features with transformer backbones. We conclude by briefly discussing DINOv2's limitations, its impact, and future research directions.