Beyond CNNs: Efficient Fine-Tuning of Multi-Modal LLMs for Object Detection on Low-Data Regimes
作者: Nirmal Elamon, Rouzbeh Davoudi
分类: cs.CV, cs.AI
发布日期: 2025-10-03
💡 一句话要点
利用多模态LLM在低数据量下高效微调,提升目标检测性能
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 目标检测 低资源学习 微调 跨模态融合 文本叠加检测
📋 核心要点
- 现有目标检测方法,如CNN,虽然有效,但在处理复杂场景和利用上下文信息方面存在局限性,且需要大量数据。
- 该论文提出通过在少量数据上微调多模态LLM,利用其语言理解能力来提升目标检测的准确性和效率。
- 实验结果表明,在人工文本叠加检测任务中,微调后的LLM在少量数据下即可达到甚至超过CNN的性能,提升高达36%。
📝 摘要(中文)
目标检测和理解领域正快速发展,这得益于传统基于CNN的模型和新兴的多模态大型语言模型(LLM)的进步。虽然像ResNet和YOLO这样的CNN在基于图像的任务中仍然非常有效,但最近基于Transformer的LLM引入了诸如动态上下文推理、语言引导提示和整体场景理解等新功能。然而,开箱即用的LLM的全部潜力仍未被充分利用,通常导致在专门的视觉任务上的次优性能。在这项工作中,我们对微调的传统CNN、零样本预训练的多模态LLM和微调的多模态LLM在图像中人工文本叠加检测这一具有挑战性的任务上进行了全面比较。我们研究的一个关键贡献是证明了LLM可以在非常有限的数据(少于1000张图像)上进行有效微调,以实现高达36%的准确率提升,匹配或超过通常需要更多数量级数据的基于CNN的基线。通过探索如何调整语言引导模型以实现精确的视觉理解和最小的监督,我们的工作有助于弥合视觉和语言之间的差距,为高效的跨模态学习策略提供新的见解。这些发现突出了基于LLM的方法在实际目标检测任务中的适应性和数据效率,并为在低资源视觉环境中应用多模态Transformer提供了可操作的指导。为了支持该领域的持续发展,我们已将用于微调模型的代码发布在我们的GitHub中,从而可以在相关应用中实现未来的改进和重用。
🔬 方法详解
问题定义:论文旨在解决在低数据量情况下,如何有效利用多模态LLM提升目标检测性能的问题。现有基于CNN的方法通常需要大量标注数据才能达到理想效果,且难以有效利用图像中的上下文信息。直接使用预训练的LLM进行目标检测,效果往往不佳,无法充分发挥其潜力。
核心思路:论文的核心思路是利用多模态LLM强大的语言理解和推理能力,通过在少量目标检测数据上进行微调,使LLM能够更好地理解图像内容和目标之间的关系,从而提升目标检测的准确性和效率。通过语言引导,LLM可以更好地理解任务目标,并利用其预训练的知识进行推理。
技术框架:整体框架包括以下几个阶段:1) 选择合适的多模态LLM作为基础模型;2) 构建包含图像和文本描述的目标检测数据集;3) 使用少量数据对LLM进行微调,使其适应目标检测任务;4) 使用微调后的LLM进行目标检测,并评估其性能。该框架的关键在于如何设计合适的微调策略,以及如何利用语言信息来引导LLM进行目标检测。
关键创新:该论文的关键创新在于证明了多模态LLM在少量数据下进行微调,即可在目标检测任务中取得显著的性能提升。这打破了传统目标检测方法依赖大量数据的限制,为低资源场景下的目标检测提供了一种新的解决方案。此外,论文还探索了如何利用语言信息来引导LLM进行目标检测,为跨模态学习提供了新的思路。
关键设计:论文的关键设计包括:1) 选择合适的预训练多模态LLM,例如CLIP或类似模型;2) 设计合适的文本提示,引导LLM关注目标检测任务;3) 使用交叉熵损失函数或类似的损失函数来优化LLM的参数;4) 探索不同的微调策略,例如只微调部分参数或使用不同的学习率。
🖼️ 关键图片
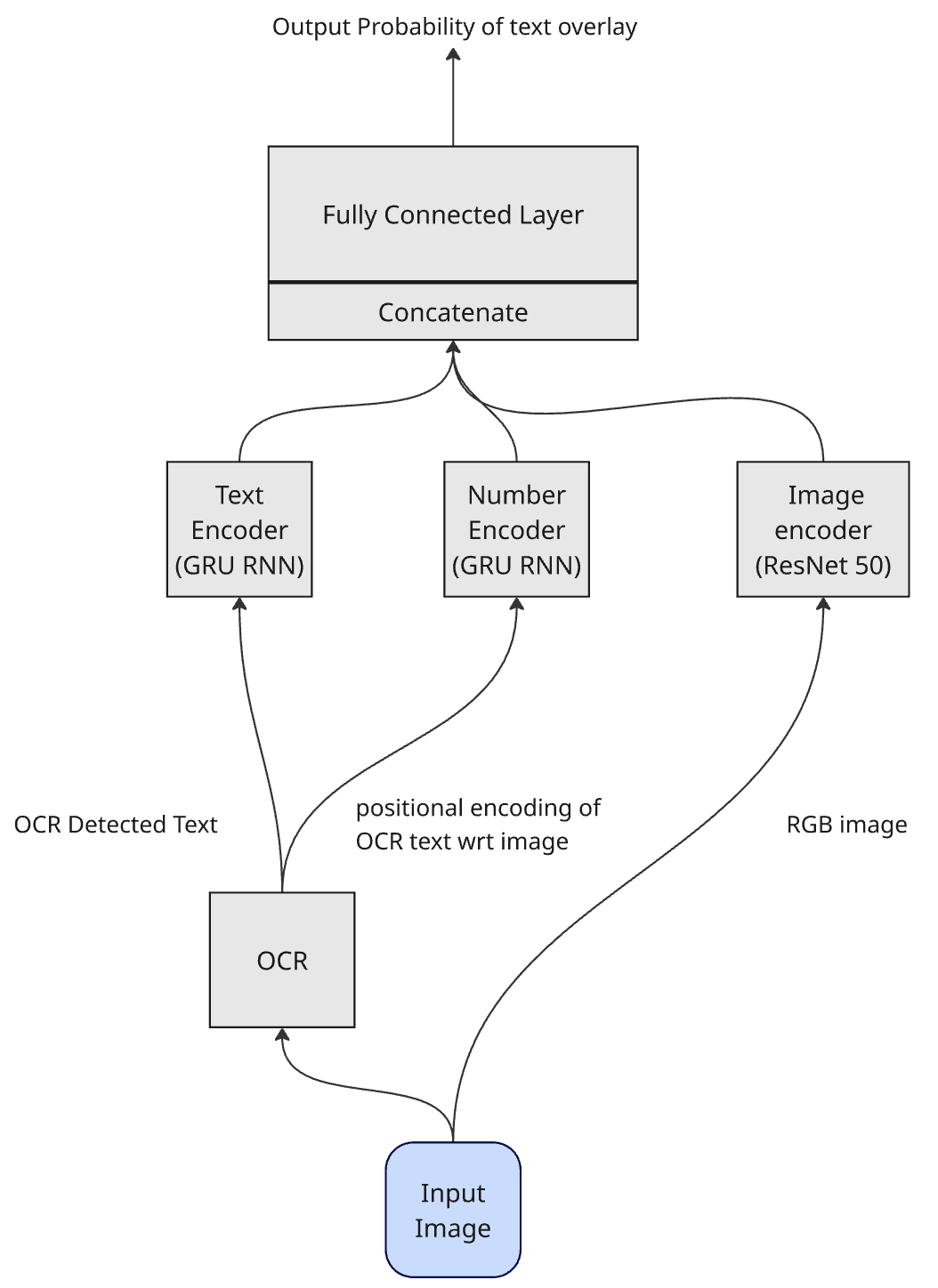
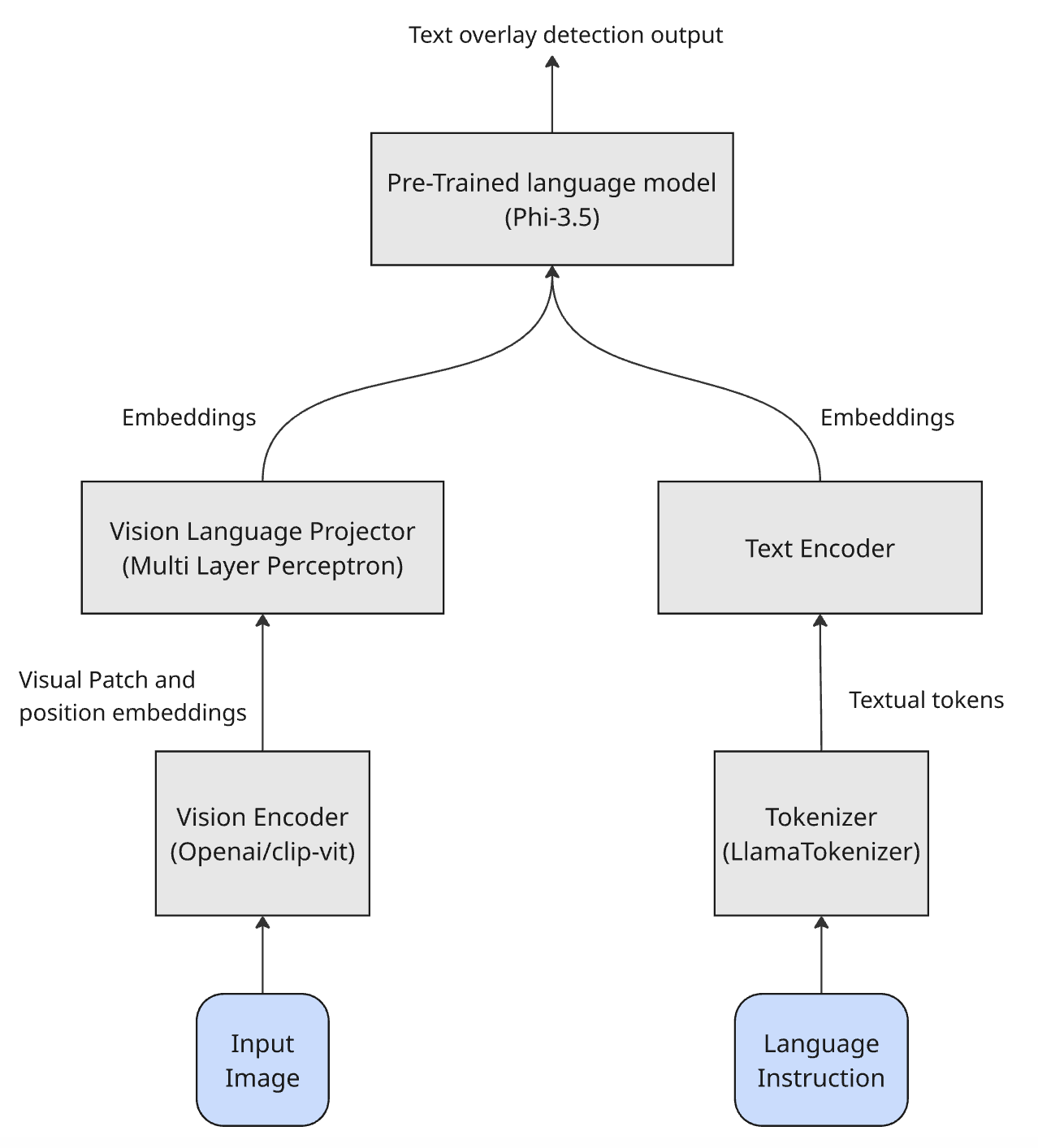
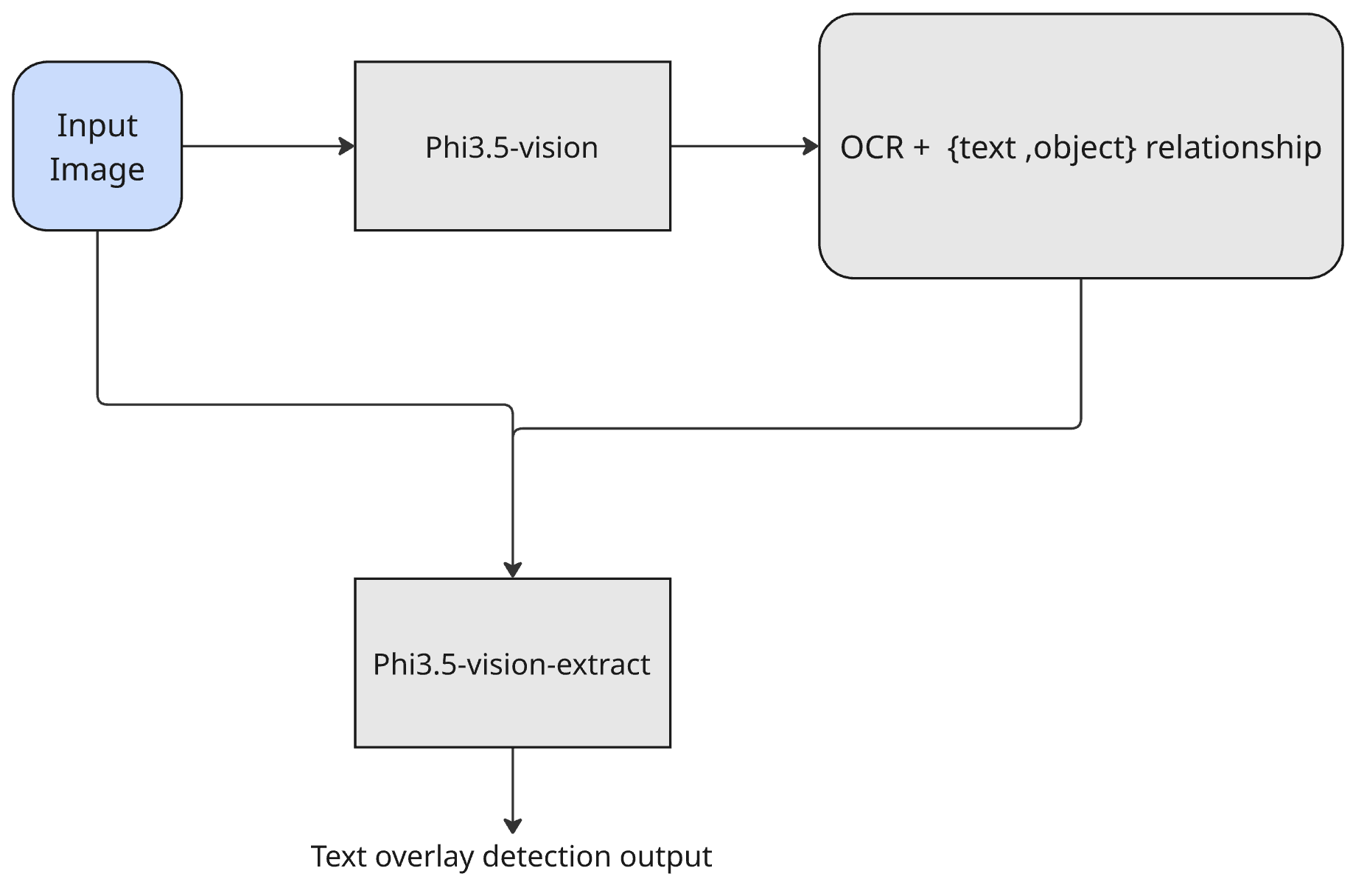
📊 实验亮点
实验结果表明,在人工文本叠加检测任务中,使用少于1000张图像进行微调的多模态LLM,其准确率提升高达36%,能够匹配甚至超过需要更多数量级数据的基于CNN的基线模型。这一结果突出了LLM在低数据量下的强大适应性和数据效率,为实际应用提供了有力的支持。
🎯 应用场景
该研究成果可应用于多种低资源目标检测场景,例如:工业质检中缺陷检测、医学图像分析中病灶检测、遥感图像分析中目标识别等。通过利用少量标注数据微调多模态LLM,可以快速构建高性能的目标检测系统,降低标注成本,加速应用落地。未来,该方法有望推广到更多视觉任务中,推动跨模态学习的发展。
📄 摘要(原文)
The field of object detection and understanding is rapidly evolving, driven by advances in both traditional CNN-based models and emerging multi-modal large language models (LLMs). While CNNs like ResNet and YOLO remain highly effective for image-based tasks, recent transformer-based LLMs introduce new capabilities such as dynamic context reasoning, language-guided prompts, and holistic scene understanding. However, when used out-of-the-box, the full potential of LLMs remains underexploited, often resulting in suboptimal performance on specialized visual tasks. In this work, we conduct a comprehensive comparison of fine-tuned traditional CNNs, zero-shot pre-trained multi-modal LLMs, and fine-tuned multi-modal LLMs on the challenging task of artificial text overlay detection in images. A key contribution of our study is demonstrating that LLMs can be effectively fine-tuned on very limited data (fewer than 1,000 images) to achieve up to 36% accuracy improvement, matching or surpassing CNN-based baselines that typically require orders of magnitude more data. By exploring how language-guided models can be adapted for precise visual understanding with minimal supervision, our work contributes to the broader effort of bridging vision and language, offering novel insights into efficient cross-modal learning strategies. These findings highlight the adaptability and data efficiency of LLM-based approaches for real-world object detection tasks and provide actionable guidance for applying multi-modal transformers in low-resource visual environments. To support continued progress in this area, we have made the code used to fine-tune the models available in our GitHub, enabling future improvements and reuse in related applications.