Spatial-ViLT: Enhancing Visual Spatial Reasoning through Multi-Task Learning
作者: Chashi Mahiul Islam, Oteo Mamo, Samuel Jacob Chacko, Xiuwen Liu, Weikuan Yu
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-10-03
备注: 12 pages, 5 figures
💡 一句话要点
Spatial-ViLT通过多任务学习增强视觉空间推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 空间推理 多任务学习 深度图 3D坐标 边缘检测 ViLT 多模态融合
📋 核心要点
- 现有视觉-语言模型在空间推理方面存在不足,尤其是在处理3D场景和复杂物体关系时。
- SpatialViLT通过多任务学习融合深度图、3D坐标和边缘图等空间特征,增强模型对空间信息的理解。
- SpatialEnsemble结合SpatialViLT和MaskedSpatialViLT,在VSR数据集上取得了state-of-the-art的性能。
📝 摘要(中文)
视觉-语言模型(VLM)在多模态推理方面取得了进展,但在3D场景和复杂物体配置的空间推理方面仍然面临挑战。为了解决这个问题,我们引入了SpatialViLT,这是一种增强的VLM,它通过多任务学习框架集成了深度图、3D坐标和边缘图等空间特征。这种方法利用空间理解来丰富多模态嵌入。我们提出了两种变体:SpatialViLT和MaskedSpatialViLT,分别侧重于完整和掩码的对象区域。此外,SpatialEnsemble结合了这两种方法,实现了最先进的准确性。我们的模型在方向、拓扑和邻近关系等空间推理类别中表现出色,这已在具有挑战性的视觉空间推理(VSR)数据集上得到证明。这项工作代表了在增强AI系统的空间智能方面的重要一步,这对于高级多模态理解和实际应用至关重要。
🔬 方法详解
问题定义:现有视觉-语言模型在理解图像中的空间关系方面存在局限性,尤其是在涉及3D场景和复杂物体配置时。这些模型难以准确推断物体之间的方向、拓扑和邻近关系。现有的方法通常忽略了图像中丰富的空间信息,导致推理性能下降。
核心思路:SpatialViLT的核心思路是通过多任务学习的方式,将空间信息(如深度图、3D坐标和边缘图)融入到视觉-语言模型的嵌入中。通过显式地建模空间关系,模型能够更好地理解图像中的物体布局和相互作用。
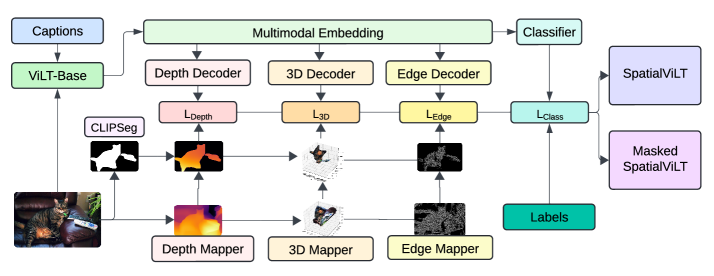
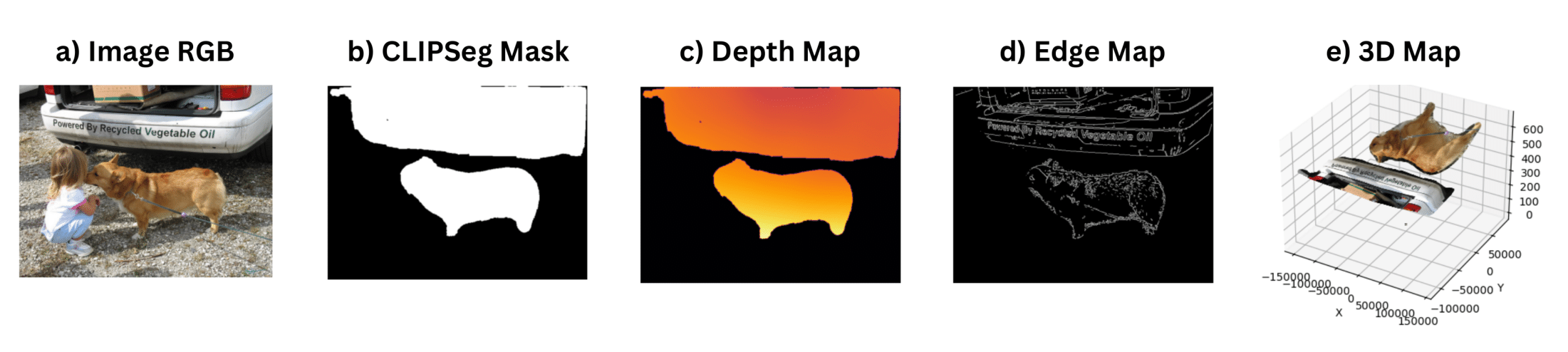
技术框架:SpatialViLT的整体框架基于ViLT模型,并在此基础上添加了空间特征提取模块和多任务学习目标。首先,使用预训练的深度估计模型、3D坐标回归模型和边缘检测模型提取图像的空间特征。然后,将这些空间特征与原始图像特征一起输入到ViLT模型中进行融合。最后,通过多任务学习,同时优化模型在空间推理任务和视觉-语言任务上的性能。SpatialEnsemble则是SpatialViLT和MaskedSpatialViLT的集成。
关键创新:SpatialViLT的关键创新在于将空间信息显式地融入到视觉-语言模型的学习过程中。与以往的方法相比,SpatialViLT不仅关注图像的视觉内容,还关注图像中物体的空间布局和相互关系。这种方法能够显著提高模型在空间推理任务上的性能。
关键设计:SpatialViLT采用了多任务学习框架,同时优化模型在多个任务上的性能。这些任务包括空间推理任务(如方向、拓扑和邻近关系预测)和视觉-语言任务(如图像描述和视觉问答)。为了平衡不同任务之间的学习,SpatialViLT使用了动态权重调整策略。此外,SpatialViLT还采用了数据增强技术,如随机裁剪和旋转,以提高模型的鲁棒性。
🖼️ 关键图片

📊 实验亮点
SpatialViLT在Visual Spatial Reasoning (VSR)数据集上取得了显著的性能提升。SpatialEnsemble模型在VSR数据集上达到了state-of-the-art的准确率,超过了现有的视觉-语言模型。实验结果表明,SpatialViLT在方向、拓扑和邻近关系等空间推理类别中均表现出色,验证了其有效性。
🎯 应用场景
SpatialViLT在机器人导航、自动驾驶、虚拟现实和增强现实等领域具有广泛的应用前景。例如,在机器人导航中,SpatialViLT可以帮助机器人理解周围环境的空间布局,从而实现更准确的路径规划和避障。在自动驾驶中,SpatialViLT可以帮助车辆理解交通场景中的物体关系,从而提高驾驶安全性。在虚拟现实和增强现实中,SpatialViLT可以帮助用户与虚拟环境进行更自然的交互。
📄 摘要(原文)
Vision-language models (VLMs) have advanced multimodal reasoning but still face challenges in spatial reasoning for 3D scenes and complex object configurations. To address this, we introduce SpatialViLT, an enhanced VLM that integrates spatial features like depth maps, 3D coordinates, and edge maps through a multi-task learning framework. This approach enriches multimodal embeddings with spatial understanding. We propose two variants: SpatialViLT and MaskedSpatialViLT, focusing on full and masked object regions, respectively. Additionally, SpatialEnsemble combines both approaches, achieving state-of-the-art accuracy. Our models excel in spatial reasoning categories such as directional, topological, and proximity relations, as demonstrated on the challenging Visual Spatial Reasoning (VSR) dataset. This work represents a significant step in enhancing the spatial intelligence of AI systems, crucial for advanced multimodal understanding and real-world applications.