LEAML: Label-Efficient Adaptation to Out-of-Distribution Visual Tasks for Multimodal Large Language Models
作者: Ci-Siang Lin, Min-Hung Chen, Yu-Yang Sheng, Yu-Chiang Frank Wang
分类: cs.CV
发布日期: 2025-10-03
💡 一句话要点
LEAML:面向多模态大语言模型,高效适应领域外视觉任务
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 领域自适应 视觉问答 伪标签生成 选择性更新 标签高效 caption distillation 知识迁移
📋 核心要点
- 多模态大语言模型在特定领域外任务中,面临标注数据稀缺的挑战。
- LEAML框架利用少量标注数据和大量未标注数据,通过伪标签生成和选择性神经元更新实现高效适应。
- 实验表明,LEAML在胃肠内窥镜和体育VQA任务上,显著优于标准微调方法。
📝 摘要(中文)
多模态大语言模型(MLLMs)在通用视觉基准测试中表现出色,但在医学影像等专业领域,由于标注数据有限且昂贵,其在领域外(OOD)任务中表现不佳。我们提出了LEAML,一个标签高效的自适应框架,它利用稀缺的标注VQA样本和丰富的未标注图像。我们的方法使用一个由caption distillation正则化的QA生成器,为未标注数据生成领域相关的伪问答对。重要的是,我们选择性地更新与问答最相关的神经元,使QA生成器能够在蒸馏过程中有效地获取领域特定知识。在胃肠内窥镜和体育VQA上的实验表明,LEAML在最小监督下始终优于标准微调,突出了我们提出的LEAML框架的有效性。
🔬 方法详解
问题定义:多模态大语言模型在通用视觉任务上表现良好,但在特定领域(如医学影像、专业体育)的视觉问答(VQA)任务中,由于缺乏足够的标注数据,模型性能显著下降。现有方法通常采用全参数微调,但效率低下,且容易过拟合。
核心思路:LEAML的核心思路是利用未标注数据,通过伪标签生成和选择性神经元更新,提升模型在目标领域的适应能力。通过caption distillation正则化的QA生成器生成高质量的伪问答对,并仅更新与问答任务相关的神经元,从而实现高效的知识迁移。
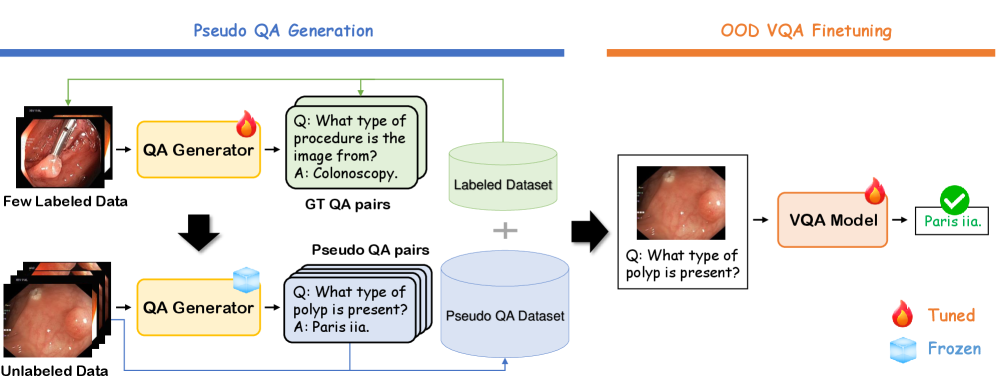
技术框架:LEAML框架包含以下几个主要模块:1) QA生成器:用于生成伪问答对,以扩充训练数据。2) Caption Distillation模块:通过caption信息来正则化QA生成器,保证生成的问题与图像内容相关。3) 选择性神经元更新模块:只更新与问答任务相关的神经元,避免无关信息的干扰,提高训练效率。整体流程是:首先利用少量标注数据初始化模型,然后利用caption distillation模块生成伪问答对,最后通过选择性神经元更新的方式,在伪问答对上进行训练。
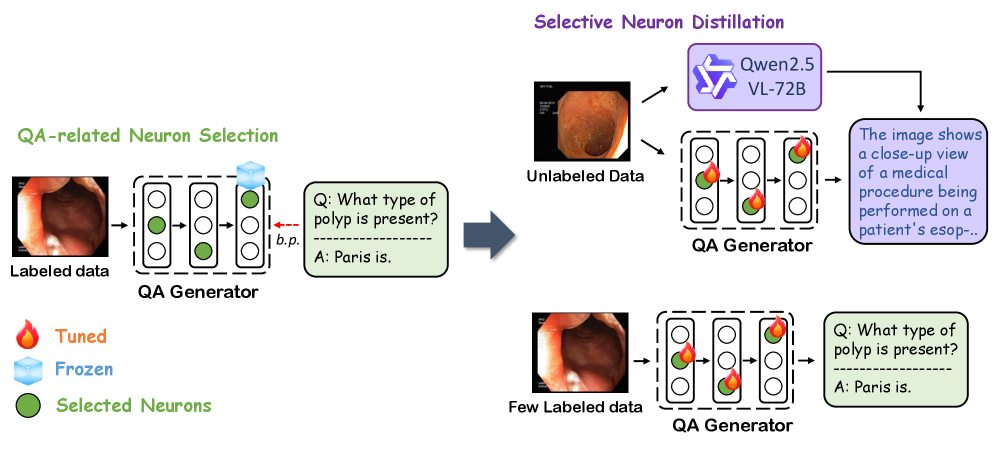
关键创新:LEAML的关键创新在于:1) 标签高效性:仅需少量标注数据即可实现良好的领域适应效果。2) 选择性神经元更新:通过只更新与问答任务相关的神经元,显著提高了训练效率和模型泛化能力。3) Caption Distillation正则化:利用图像的caption信息来指导QA生成器,保证生成的问题与图像内容相关,提高了伪标签的质量。
关键设计:在caption distillation模块中,使用了交叉熵损失函数来衡量生成的问题与图像caption之间的相似度。在选择性神经元更新模块中,使用了一个二元掩码来选择需要更新的神经元。该掩码是基于神经元对问答任务的贡献度计算得到的。具体来说,通过计算每个神经元在问答任务中的梯度,并设置一个阈值,来确定哪些神经元需要更新。阈值的选择是一个关键参数,需要根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
LEAML在胃肠内窥镜VQA和体育VQA数据集上进行了实验,结果表明,在少量标注数据的情况下,LEAML显著优于标准微调方法。例如,在胃肠内窥镜VQA数据集上,LEAML的准确率比标准微调方法提高了超过10%。实验结果验证了LEAML框架的有效性和标签高效性。
🎯 应用场景
LEAML框架可应用于各种需要领域自适应的视觉问答场景,例如医学影像诊断、体育赛事分析、工业质检等。该方法能够有效利用未标注数据,降低对标注数据的依赖,从而降低模型部署成本,加速模型在特定领域的应用。未来,LEAML可以扩展到其他多模态任务,例如视觉对话、图像描述等。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have achieved strong performance on general visual benchmarks but struggle with out-of-distribution (OOD) tasks in specialized domains such as medical imaging, where labeled data is limited and expensive. We introduce LEAML, a label-efficient adaptation framework that leverages both scarce labeled VQA samples and abundant unlabeled images. Our approach generates domain-relevant pseudo question-answer pairs for unlabeled data using a QA generator regularized by caption distillation. Importantly, we selectively update only those neurons most relevant to question-answering, enabling the QA Generator to efficiently acquire domain-specific knowledge during distillation. Experiments on gastrointestinal endoscopy and sports VQA demonstrate that LEAML consistently outperforms standard fine-tuning under minimal supervision, highlighting the effectiveness of our proposed LEAML framework.