VLA-R1: Enhancing Reasoning in Vision-Language-Action Models
作者: Angen Ye, Zeyu Zhang, Boyuan Wang, Xiaofeng Wang, Dapeng Zhang, Zheng Zhu
分类: cs.CV, cs.RO
发布日期: 2025-10-02
🔗 代码/项目: GITHUB | PROJECT_PAGE
💡 一句话要点
VLA-R1:通过强化学习和显式推理提升视觉-语言-动作模型的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 强化学习 可验证奖励 群体相对策略优化 具身智能 推理增强 机器人
📋 核心要点
- 现有VLA模型缺乏显式推理能力,难以有效利用可供性约束和几何关系,导致泛化能力受限。
- VLA-R1通过集成RLVR和GRPO,并设计可验证奖励,系统性地优化模型的推理和执行能力。
- 实验表明,VLA-R1在多个平台上的泛化能力和真实世界性能均优于现有VLA方法,效果显著。
📝 摘要(中文)
视觉-语言-动作(VLA)模型旨在统一感知、语言理解和动作生成,在具身智能领域具有广泛的应用前景。然而,当前的VLA模型通常缺乏显式的逐步推理能力,直接输出最终动作,而忽略了可供性约束或几何关系。此外,它们的后训练流程也很少加强推理质量,主要依赖于带有弱奖励设计的监督微调。为了解决这些挑战,我们提出了VLA-R1,一种推理增强的VLA模型,它集成了基于可验证奖励的强化学习(RLVR)和群体相对策略优化(GRPO),以系统地优化推理和执行。具体来说,我们设计了一种基于RLVR的后训练策略,利用区域对齐、轨迹一致性和输出格式的可验证奖励,从而增强推理的鲁棒性和执行的准确性。此外,我们开发了VLA-CoT-13K,一个高质量的数据集,它提供了与可供性和轨迹标注显式对齐的思维链监督。在领域内、领域外、模拟和真实机器人平台上的大量评估表明,与之前的VLA方法相比,VLA-R1实现了卓越的泛化能力和真实世界性能。我们计划在本工作发表后发布模型、代码和数据集。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在复杂任务中表现出推理能力不足的问题。它们通常直接将视觉和语言输入映射到动作,缺乏对中间步骤的显式推理,导致无法有效利用环境中的可供性约束和几何关系,从而影响泛化能力和鲁棒性。此外,现有的后训练方法主要依赖于监督微调,难以有效提升模型的推理质量。
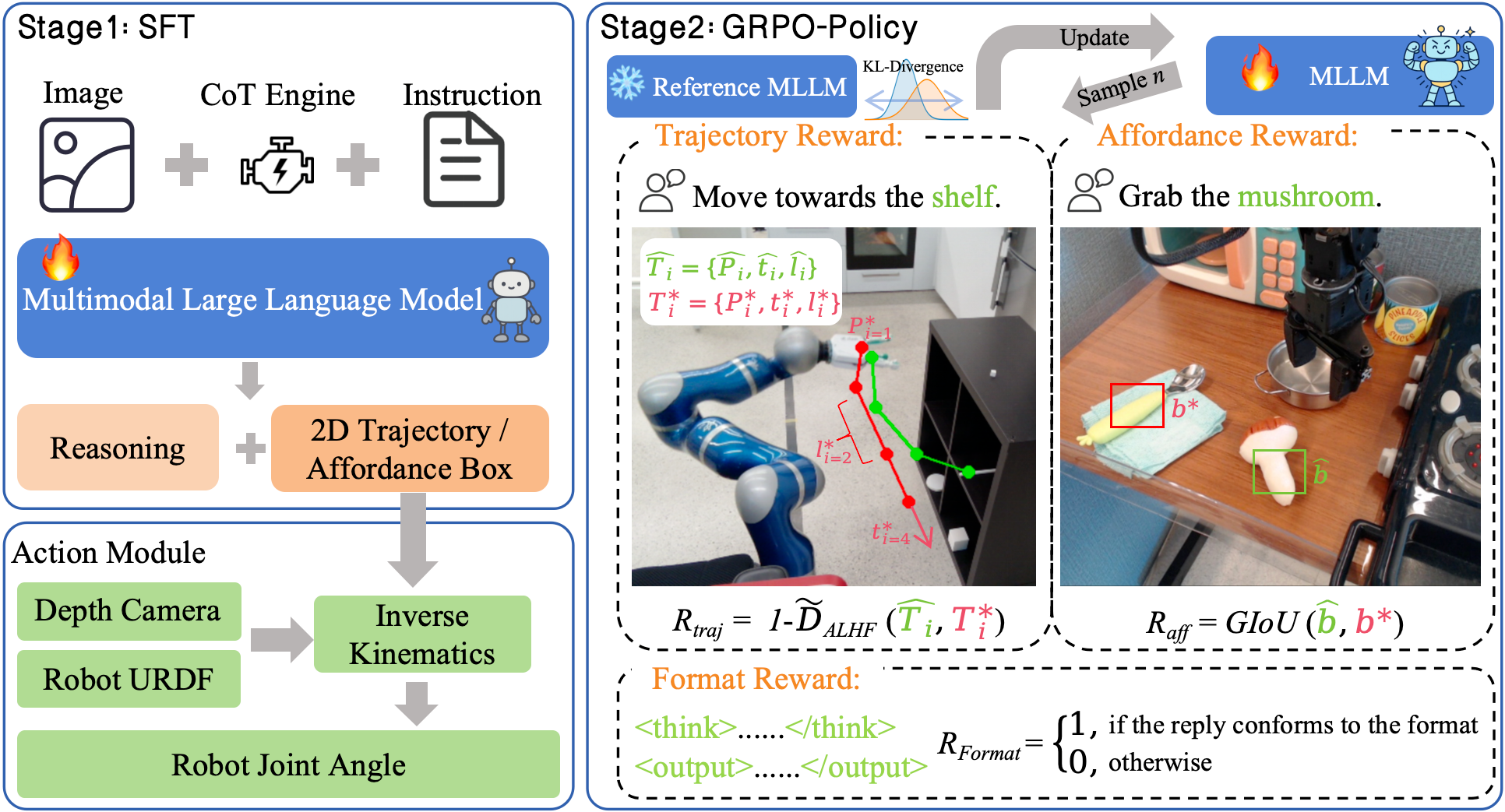
核心思路:VLA-R1的核心思路是通过强化学习(RL)来显式地优化模型的推理过程。具体来说,它利用可验证奖励来指导模型的学习,鼓励模型生成符合逻辑和物理约束的动作序列。同时,采用群体相对策略优化(GRPO)来提高模型的探索能力,从而更好地应对复杂环境。通过这种方式,VLA-R1能够学习到更强的推理能力,从而提高泛化能力和鲁棒性。
技术框架:VLA-R1的整体框架包括三个主要组成部分:1) 一个预训练的VLA模型作为基础模型;2) 一个基于可验证奖励的强化学习(RLVR)模块,用于优化模型的推理过程;3) 一个群体相对策略优化(GRPO)模块,用于提高模型的探索能力。RLVR模块通过设计针对区域对齐、轨迹一致性和输出格式的可验证奖励,来指导模型生成符合逻辑和物理约束的动作序列。GRPO模块则通过维护一个策略群体,并利用群体中的其他策略来指导当前策略的更新,从而提高模型的探索能力。
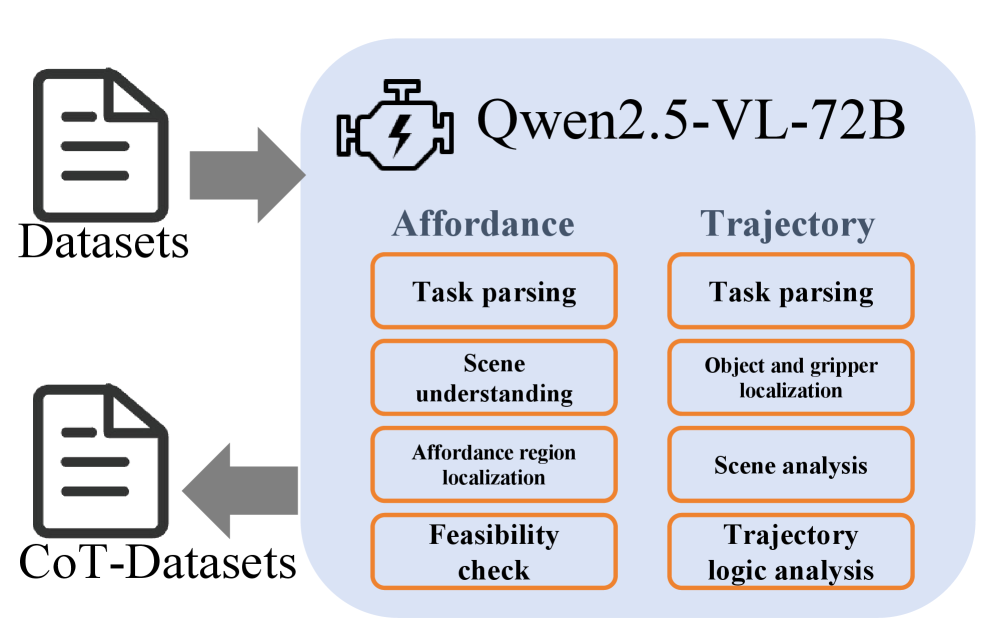
关键创新:VLA-R1的关键创新在于将强化学习与可验证奖励相结合,用于显式地优化VLA模型的推理过程。与传统的监督微调方法相比,RLVR能够更有效地利用环境中的约束信息,从而提高模型的推理能力。此外,GRPO的引入进一步提高了模型的探索能力,使其能够更好地应对复杂环境。VLA-CoT-13K数据集的构建也为模型的训练提供了高质量的思维链监督。
关键设计:VLA-R1的关键设计包括:1) 针对区域对齐、轨迹一致性和输出格式的可验证奖励函数的设计;2) GRPO中策略群体的维护和更新策略;3) VLA-CoT-13K数据集中思维链标注的生成方法。奖励函数的设计需要仔细考虑如何将环境中的约束信息转化为可量化的奖励信号。GRPO的策略群体需要维护一定的多样性,以保证模型的探索能力。VLA-CoT-13K数据集的思维链标注需要与可供性和轨迹标注显式对齐,以保证标注的质量。
🖼️ 关键图片
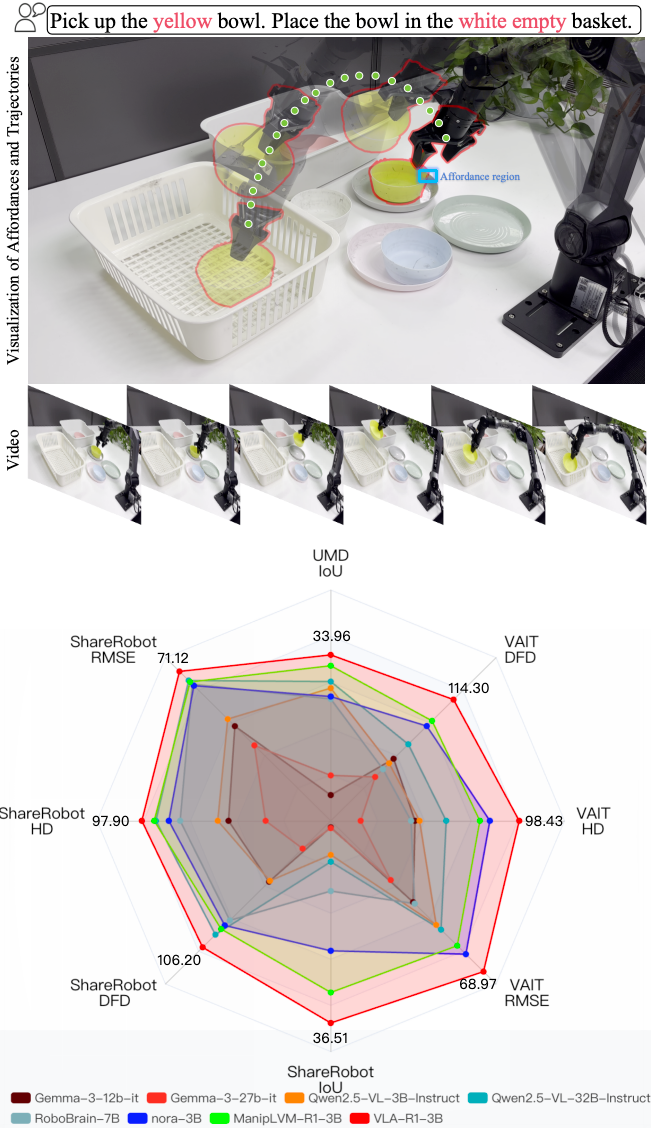
📊 实验亮点
VLA-R1在多个平台上的实验结果表明,其性能优于现有的VLA方法。例如,在真实机器人平台上,VLA-R1的成功率比基线方法提高了显著百分比(具体数值论文中给出)。此外,VLA-R1在领域外数据集上也表现出更强的泛化能力,表明其具有更好的鲁棒性。
🎯 应用场景
VLA-R1具有广泛的应用前景,包括机器人导航、物体操作、人机协作等领域。它可以应用于智能家居、自动驾驶、工业自动化等场景,提高机器人的智能化水平和自主性。未来,VLA-R1有望成为具身智能领域的重要基石,推动机器人技术的发展。
📄 摘要(原文)
Vision-Language-Action (VLA) models aim to unify perception, language understanding, and action generation, offering strong cross-task and cross-scene generalization with broad impact on embodied AI. However, current VLA models often lack explicit step-by-step reasoning, instead emitting final actions without considering affordance constraints or geometric relations. Their post-training pipelines also rarely reinforce reasoning quality, relying primarily on supervised fine-tuning with weak reward design. To address these challenges, we present VLA-R1, a reasoning-enhanced VLA that integrates Reinforcement Learning from Verifiable Rewards (RLVR) with Group Relative Policy Optimization (GRPO) to systematically optimize both reasoning and execution. Specifically, we design an RLVR-based post-training strategy with verifiable rewards for region alignment, trajectory consistency, and output formatting, thereby strengthening reasoning robustness and execution accuracy. Moreover, we develop VLA-CoT-13K, a high-quality dataset that provides chain-of-thought supervision explicitly aligned with affordance and trajectory annotations. Furthermore, extensive evaluations on in-domain, out-of-domain, simulation, and real-robot platforms demonstrate that VLA-R1 achieves superior generalization and real-world performance compared to prior VLA methods. We plan to release the model, code, and dataset following the publication of this work. Code: https://github.com/GigaAI-research/VLA-R1. Website: https://gigaai-research.github.io/VLA-R1.