KeySG: Hierarchical Keyframe-Based 3D Scene Graphs
作者: Abdelrhman Werby, Dennis Rotondi, Fabio Scaparro, Kai O. Arras
分类: cs.CV, cs.RO
发布日期: 2025-10-01
💡 一句话要点
KeySG:提出基于关键帧的分层3D场景图,提升语义丰富性和可扩展性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景图 关键帧 分层图 视觉语言模型 机器人导航 场景理解 检索增强生成
📋 核心要点
- 现有3D场景图方法在语义上受限于预定义的关系集合,且大型环境中的序列化容易超出LLM的上下文窗口。
- KeySG通过分层图结构和关键帧多模态信息增强节点,利用VLM提取场景信息,避免显式关系建模,实现通用推理。
- KeySG在3D对象分割和复杂查询检索等任务上优于现有方法,验证了其语义丰富性和效率。
📝 摘要(中文)
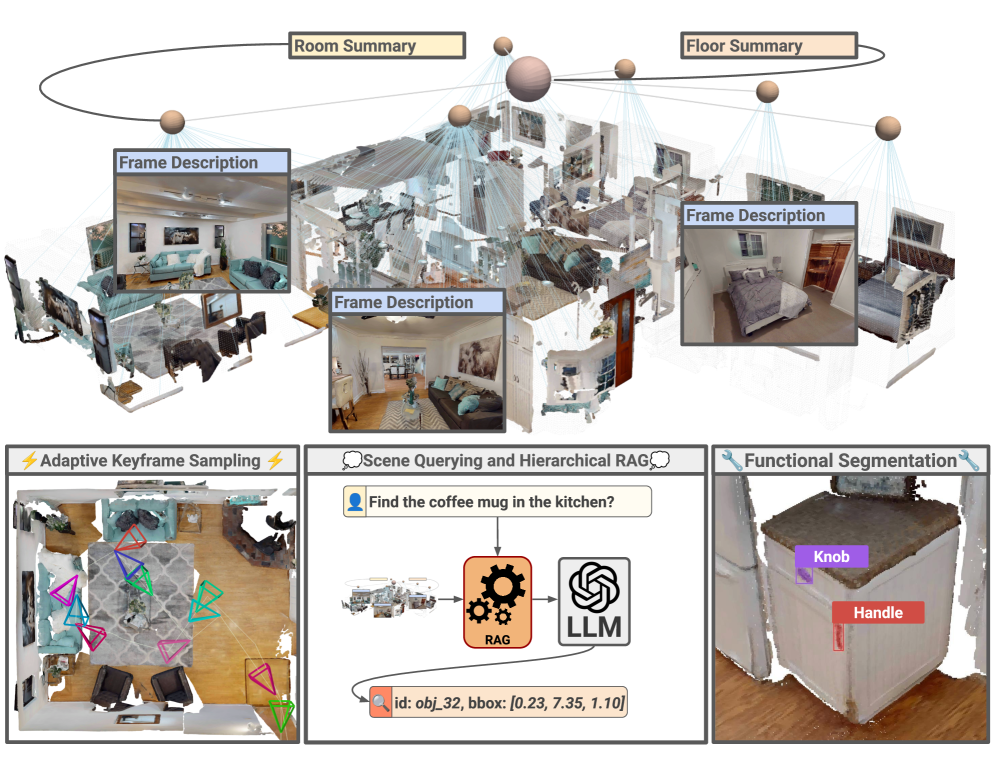
本文提出KeySG框架,用于构建分层3D场景图,该图由楼层、房间、物体和功能元素组成。节点通过从关键帧中提取的多模态信息进行增强,关键帧的选择旨在优化几何和视觉覆盖率。关键帧的使用使得能够高效地利用视觉语言模型(VLM)提取场景信息,避免了显式建模对象之间的关系,从而实现更通用、与任务无关的推理和规划。通过分层检索增强生成(RAG)流程从图中提取相关上下文,缓解了大型场景图的可扩展性问题。在四个不同的基准测试(包括3D对象分割和复杂查询检索)中,KeySG在大多数指标上优于现有方法,证明了其卓越的语义丰富性和效率。
🔬 方法详解
问题定义:现有3D场景图构建方法存在两个主要痛点:一是语义表达能力有限,只能表示预定义的关系;二是可扩展性差,难以处理大型复杂环境,序列化后的图容易超出大型语言模型的上下文窗口。这限制了3D场景图在复杂推理和规划任务中的应用。
核心思路:KeySG的核心思路是利用分层图结构和关键帧来增强场景图的语义表达能力和可扩展性。通过分层结构,将场景分解为楼层、房间、物体等不同层次,从而降低了图的复杂度。关键帧则用于提取多模态信息,并利用视觉语言模型(VLM)进行语义理解,避免了显式建模对象之间的关系。
技术框架:KeySG框架包含以下主要模块:1) 关键帧选择模块:选择能够优化几何和视觉覆盖率的关键帧;2) 多模态信息提取模块:从关键帧中提取视觉和语义信息;3) 分层图构建模块:构建包含楼层、房间、物体等层次的场景图;4) 检索增强生成(RAG)模块:从图中检索相关上下文,并生成答案。
关键创新:KeySG的关键创新在于:1) 提出了基于关键帧的场景图构建方法,利用VLM增强了语义表达能力;2) 采用了分层图结构,提高了可扩展性;3) 使用RAG流程,能够从大型场景图中提取相关上下文。与现有方法的本质区别在于,KeySG避免了显式建模对象之间的关系,从而实现了更通用、与任务无关的推理和规划。
关键设计:关键帧的选择策略旨在最大化几何和视觉覆盖率,具体实现方式未知。多模态信息提取模块利用VLM从关键帧中提取语义信息,具体使用的VLM模型未知。RAG流程中的检索策略和生成模型也未知。
🖼️ 关键图片
📊 实验亮点
KeySG在四个不同的基准测试中进行了评估,包括3D对象分割和复杂查询检索。实验结果表明,KeySG在大多数指标上优于现有方法,证明了其卓越的语义丰富性和效率。具体的性能数据和提升幅度在论文中给出,此处未知。
🎯 应用场景
KeySG在机器人导航、场景理解、人机交互等领域具有广泛的应用前景。它可以帮助机器人在复杂环境中进行推理、规划和导航,例如在家庭服务机器人、自动驾驶汽车等应用中。此外,KeySG还可以用于构建虚拟现实和增强现实环境,提供更丰富的语义信息。
📄 摘要(原文)
In recent years, 3D scene graphs have emerged as a powerful world representation, offering both geometric accuracy and semantic richness. Combining 3D scene graphs with large language models enables robots to reason, plan, and navigate in complex human-centered environments. However, current approaches for constructing 3D scene graphs are semantically limited to a predefined set of relationships, and their serialization in large environments can easily exceed an LLM's context window. We introduce KeySG, a framework that represents 3D scenes as a hierarchical graph consisting of floors, rooms, objects, and functional elements, where nodes are augmented with multi-modal information extracted from keyframes selected to optimize geometric and visual coverage. The keyframes allow us to efficiently leverage VLM to extract scene information, alleviating the need to explicitly model relationship edges between objects, enabling more general, task-agnostic reasoning and planning. Our approach can process complex and ambiguous queries while mitigating the scalability issues associated with large scene graphs by utilizing a hierarchical retrieval-augmented generation (RAG) pipeline to extract relevant context from the graph. Evaluated across four distinct benchmarks -- including 3D object segmentation and complex query retrieval -- KeySG outperforms prior approaches on most metrics, demonstrating its superior semantic richness and efficiency.