Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation
作者: Chetwin Low, Weimin Wang, Calder Katyal
分类: cs.MM, cs.CV, cs.SD, eess.AS
发布日期: 2025-09-30
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
Ovi:基于孪生骨干跨模态融合的音视频生成方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音视频生成 跨模态融合 扩散模型 DiT 孪生网络 统一生成 电影级视频 RoPE嵌入
📋 核心要点
- 现有音视频生成方法依赖复杂的多阶段架构或声音和视觉的顺序合成,缺乏统一性。
- Ovi通过孪生DiT模块的块状跨模态融合,将音频和视频建模为单一生成过程,实现自然同步。
- Ovi在大量数据上训练音频塔,使其能生成逼真音效和富含情感的语音,并生成电影级视频片段。
📝 摘要(中文)
本文提出了一种用于音视频生成的统一范式Ovi,它将两种模态建模为单一的生成过程。通过使用孪生DiT模块的块状跨模态融合,Ovi实现了自然的同步,并消除了对单独流水线或事后对齐的需求。为了促进细粒度的多模态融合建模,我们使用与强大的预训练视频模型相同的架构初始化了一个音频塔。音频塔从头开始在数十万小时的原始音频上进行训练,学习生成逼真的音效,以及传达丰富的说话人身份和情感的语音。通过在海量的视频语料库上,以块状交换时间信息(通过缩放的RoPE嵌入)和语义信息(通过双向交叉注意力)的方式联合训练相同的视频和音频塔,从而实现融合。我们的模型能够通过自然的语音和准确的、上下文匹配的音效进行电影叙事,从而生成电影级的视频片段。所有的演示、代码和模型权重都发布在https://aaxwaz.github.io/Ovi。
🔬 方法详解
问题定义:音视频生成任务旨在根据给定的输入(例如文本描述或初始帧)生成一段包含同步音频和视频的片段。现有的方法通常采用多阶段架构,分别生成音频和视频,然后进行后处理对齐,这导致流程复杂且难以保证模态间的自然同步。此外,现有方法在生成高质量、富含情感的语音和上下文匹配的音效方面仍存在挑战。
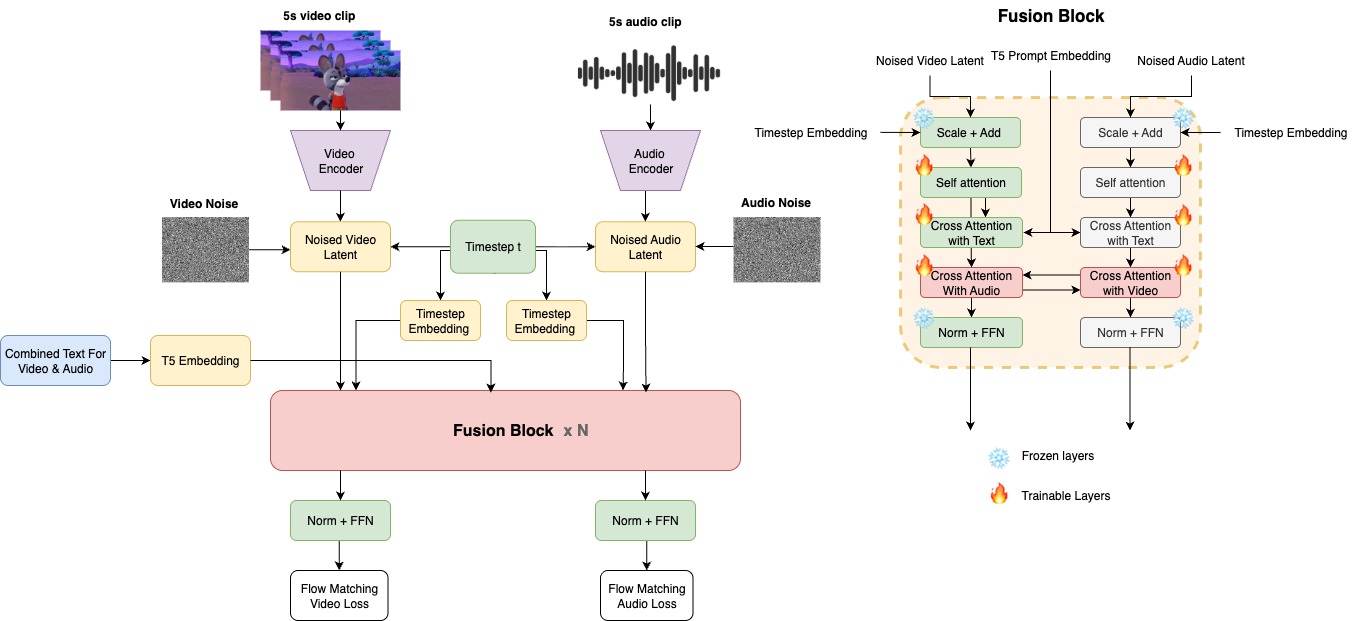
核心思路:Ovi的核心思路是将音频和视频视为一个统一的生成过程,通过共享的生成模型同时生成两种模态。为了实现这一点,Ovi采用了孪生骨干网络结构,即两个结构相同的DiT(Diffusion Transformer)模块分别处理音频和视频。通过在训练过程中进行跨模态融合,模型能够学习到音频和视频之间的内在关联,从而实现自然的同步和上下文匹配。
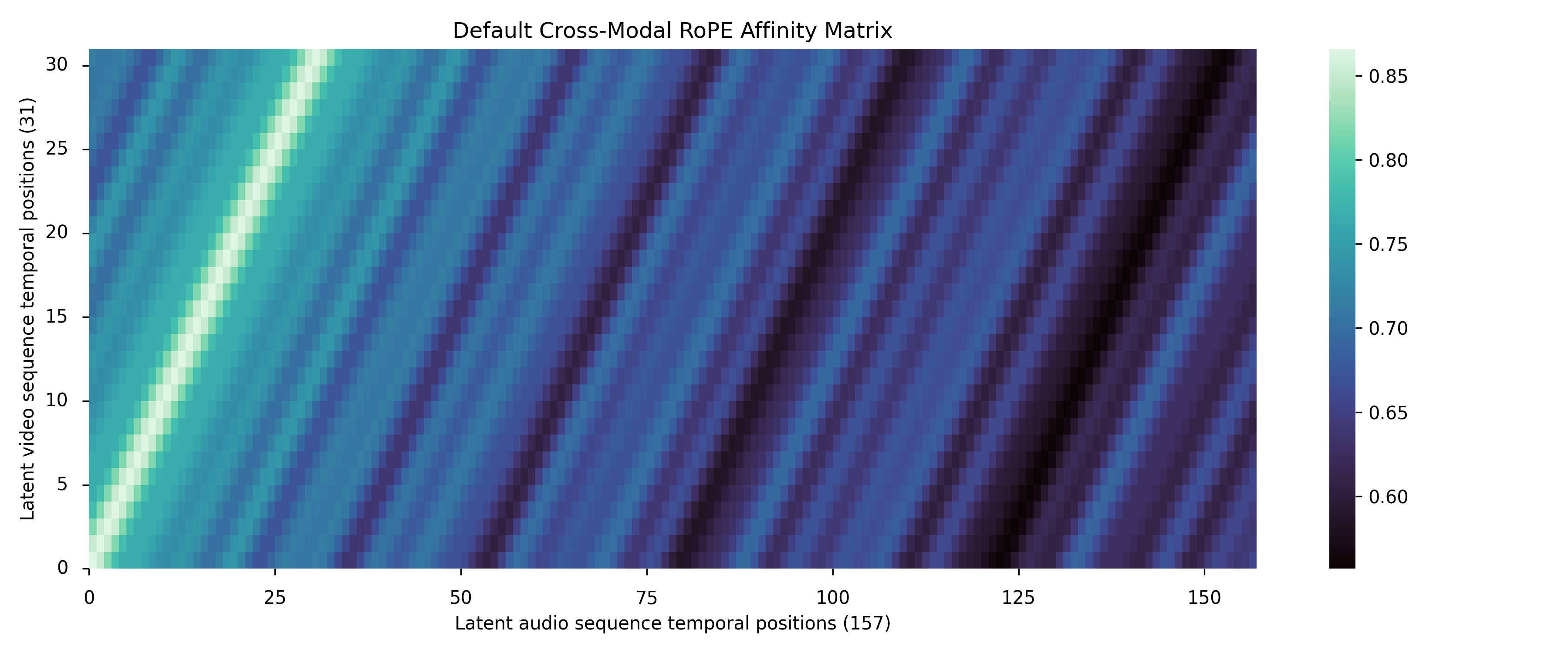
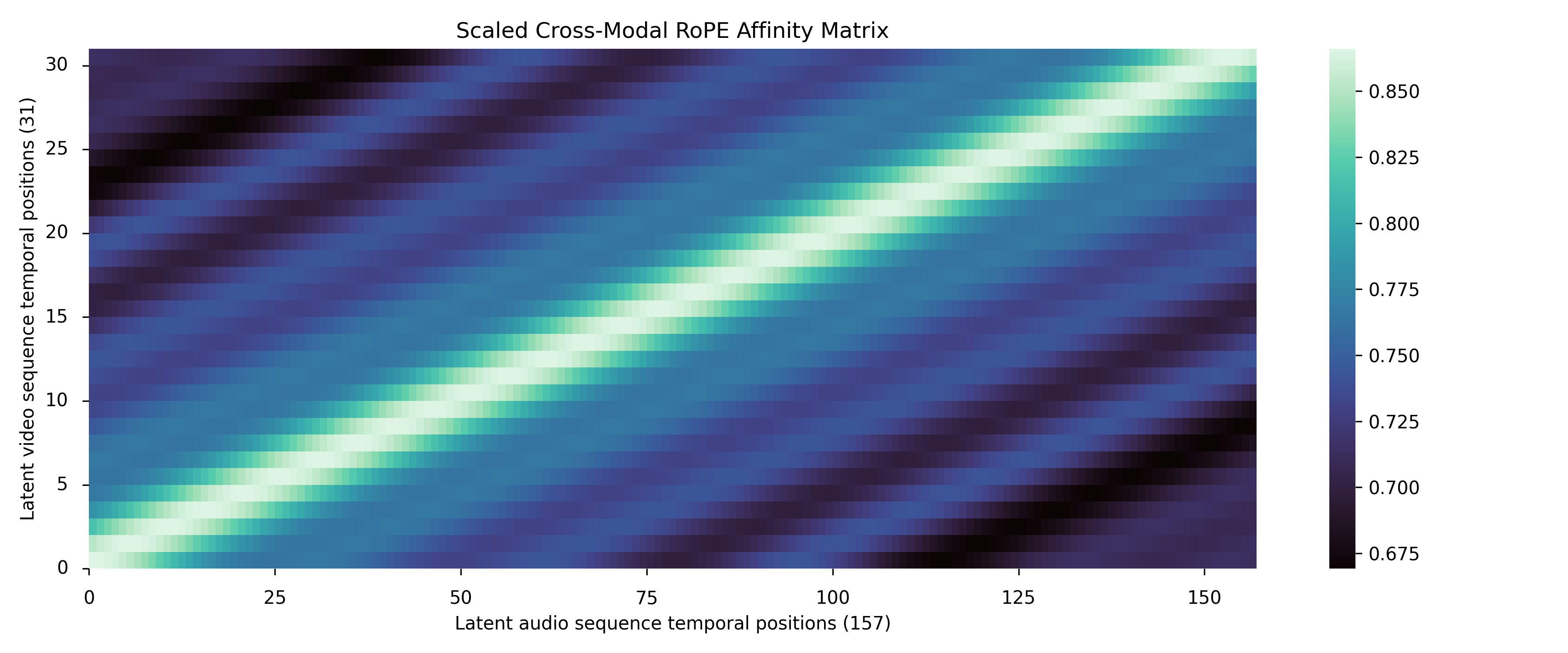
技术框架:Ovi的整体架构包括两个主要的模块:音频塔和视频塔。这两个塔都基于DiT架构,并且具有相同的结构。音频塔从头开始在大量的音频数据上进行训练,学习生成逼真的音效和语音。视频塔则利用预训练的视频模型进行初始化,从而加速训练过程。在训练过程中,音频塔和视频塔通过块状跨模态融合进行交互。具体来说,模型在每个块中交换时间信息(通过缩放的RoPE嵌入)和语义信息(通过双向交叉注意力),从而实现模态间的信息共享和融合。
关键创新:Ovi的关键创新在于其统一的生成范式和块状跨模态融合机制。与传统的多阶段方法相比,Ovi能够直接生成同步的音频和视频,避免了后处理对齐的需要。此外,通过在孪生DiT模块中进行跨模态融合,Ovi能够更好地捕捉音频和视频之间的内在关联,从而生成更自然、更逼真的音视频片段。
关键设计:Ovi的关键设计包括以下几个方面:1) 孪生DiT模块:使用结构相同的DiT模块处理音频和视频,方便进行跨模态融合。2) 块状跨模态融合:在每个块中交换时间信息和语义信息,实现模态间的信息共享和融合。3) 缩放的RoPE嵌入:用于编码时间信息,并允许模型处理不同长度的序列。4) 双向交叉注意力:用于捕捉音频和视频之间的语义关联。
🖼️ 关键图片
📊 实验亮点
Ovi在音视频生成任务上取得了显著的成果。通过在大量数据上进行训练,Ovi能够生成逼真的音效、富含情感的语音和上下文匹配的视频片段。与现有的方法相比,Ovi生成的音视频片段具有更高的同步性和自然度,能够更好地满足用户的需求。项目主页提供了丰富的演示视频,展示了Ovi在不同场景下的生成效果。
🎯 应用场景
Ovi具有广泛的应用前景,包括电影制作、游戏开发、虚拟现实、教育娱乐等领域。它可以用于生成电影级的视频片段,为游戏角色配音,创建沉浸式的虚拟现实体验,以及制作生动有趣的教育内容。Ovi的统一生成范式和跨模态融合机制为音视频生成领域带来了新的可能性,有望推动相关技术的发展。
📄 摘要(原文)
Audio-video generation has often relied on complex multi-stage architectures or sequential synthesis of sound and visuals. We introduce Ovi, a unified paradigm for audio-video generation that models the two modalities as a single generative process. By using blockwise cross-modal fusion of twin-DiT modules, Ovi achieves natural synchronization and removes the need for separate pipelines or post hoc alignment. To facilitate fine-grained multimodal fusion modeling, we initialize an audio tower with an architecture identical to that of a strong pretrained video model. Trained from scratch on hundreds of thousands of hours of raw audio, the audio tower learns to generate realistic sound effects, as well as speech that conveys rich speaker identity and emotion. Fusion is obtained by jointly training the identical video and audio towers via blockwise exchange of timing (via scaled-RoPE embeddings) and semantics (through bidirectional cross-attention) on a vast video corpus. Our model enables cinematic storytelling with natural speech and accurate, context-matched sound effects, producing movie-grade video clips. All the demos, code and model weights are published at https://aaxwaz.github.io/Ovi