Stitch: Training-Free Position Control in Multimodal Diffusion Transformers
作者: Jessica Bader, Mateusz Pach, Maria A. Bravo, Serge Belongie, Zeynep Akata
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-09-30
备注: Preprint
🔗 代码/项目: GITHUB
💡 一句话要点
Stitch:一种免训练的多模态扩散Transformer位置控制方法
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到图像生成 位置控制 多模态扩散Transformer 免训练方法 图像拼接 空间关系 注意力机制
📋 核心要点
- 现有T2I模型难以准确捕捉空间关系,且早期位置控制方法与现代模型不兼容。
- Stitch通过自动生成边界框,在MMDiT中实现免训练的位置控制,提升空间准确性。
- 实验表明,Stitch在多个模型上显著提升了位置控制性能,并在PosEval基准上取得了SOTA结果。
📝 摘要(中文)
近年来,文本到图像(T2I)生成模型发展迅速,但准确捕捉空间关系(如“上方”或“右侧”)仍然是一个挑战。早期方法通过外部位置控制来改善空间关系。然而,随着架构发展以提高图像质量,这些技术与现代模型变得不兼容。我们提出Stitch,一种免训练的方法,通过自动生成的边界框将外部位置控制整合到多模态扩散Transformer(MMDiT)中。Stitch通过在指定的边界框内生成单个对象并将它们无缝拼接在一起,从而生成空间上准确且视觉上吸引人的图像。我们发现,目标注意力头捕获了必要的信息,可以在生成过程中隔离和切出单个对象,而无需完全完成图像。我们在PosEval(我们用于基于位置的T2I生成的基准)上评估Stitch。PosEval包含五个新任务,扩展了位置的概念,超越了基本的GenEval任务,表明即使是顶级模型在基于位置的生成方面仍有很大的改进空间。在Qwen-Image、FLUX和SD3.5上测试,Stitch始终增强了基础模型,甚至在GenEval的位置任务上将FLUX提高了218%,在PosEval上提高了206%。Stitch在PosEval上使用Qwen-Image实现了最先进的结果,比以前的模型提高了54%,所有这些都是在免训练的情况下将位置控制集成到领先模型中实现的。
🔬 方法详解
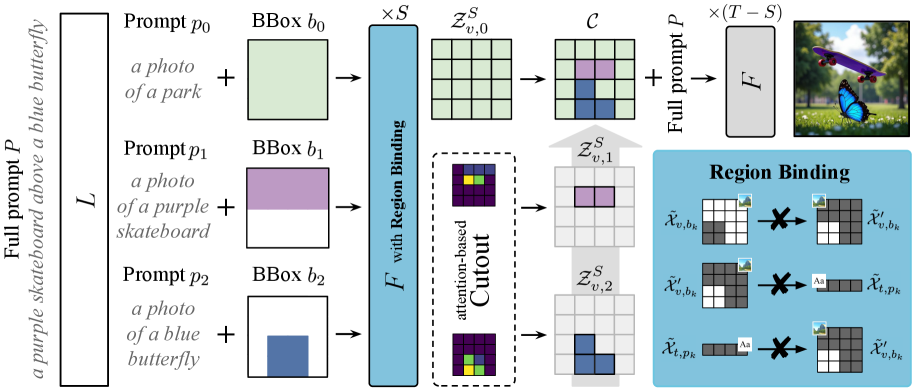
问题定义:论文旨在解决文本到图像生成模型中难以准确控制物体空间位置关系的问题。现有方法,特别是早期依赖外部位置控制的方法,与现代图像生成模型(如MMDiT)的架构不兼容,无法有效提升图像质量和空间布局的准确性。
核心思路:Stitch的核心思路是在图像生成过程中,利用自动生成的边界框来引导每个物体的生成位置,然后将这些物体无缝拼接在一起。这种方法无需对模型进行额外训练,即可实现对物体位置的精确控制。
技术框架:Stitch方法主要包含以下几个阶段:1) 文本输入和边界框生成:根据文本描述,自动生成每个物体的边界框。2) 对象生成:利用扩散模型在各自的边界框内生成单个对象。3) 图像拼接:将生成的对象无缝拼接在一起,形成完整的图像。整个过程利用了MMDiT架构,并针对位置控制进行了优化。
关键创新:Stitch的关键创新在于其免训练的特性,以及利用目标注意力头在生成过程中隔离和切出单个对象的能力。通过这种方式,Stitch避免了对模型进行重新训练的需要,同时实现了对物体位置的精确控制。
关键设计:Stitch的关键设计包括:1) 自动边界框生成算法,用于根据文本描述确定物体的位置和大小。2) 利用MMDiT架构中的注意力机制,在生成过程中对每个物体进行独立控制。3) 无缝拼接算法,用于将生成的对象平滑地融合在一起,避免出现明显的边界。
🖼️ 关键图片


📊 实验亮点
Stitch在PosEval基准测试中表现出色,显著提升了现有模型的性能。例如,在GenEval的位置任务上,Stitch将FLUX模型的性能提高了218%,在PosEval上提高了206%。使用Qwen-Image时,Stitch在PosEval上实现了最先进的结果,比以前的模型提高了54%。这些结果表明,Stitch是一种有效且通用的位置控制方法。
🎯 应用场景
Stitch技术可应用于图像编辑、虚拟现实、游戏开发等领域。例如,用户可以通过文本指令精确控制图像中物体的位置,实现个性化的图像创作。该技术还可以用于生成具有特定空间布局的虚拟场景,提升VR/AR体验。此外,在游戏开发中,Stitch可以帮助开发者快速生成具有复杂空间关系的场景和角色。
📄 摘要(原文)
Text-to-Image (T2I) generation models have advanced rapidly in recent years, but accurately capturing spatial relationships like "above" or "to the right of" poses a persistent challenge. Earlier methods improved spatial relationship following with external position control. However, as architectures evolved to enhance image quality, these techniques became incompatible with modern models. We propose Stitch, a training-free method for incorporating external position control into Multi-Modal Diffusion Transformers (MMDiT) via automatically-generated bounding boxes. Stitch produces images that are both spatially accurate and visually appealing by generating individual objects within designated bounding boxes and seamlessly stitching them together. We find that targeted attention heads capture the information necessary to isolate and cut out individual objects mid-generation, without needing to fully complete the image. We evaluate Stitch on PosEval, our benchmark for position-based T2I generation. Featuring five new tasks that extend the concept of Position beyond the basic GenEval task, PosEval demonstrates that even top models still have significant room for improvement in position-based generation. Tested on Qwen-Image, FLUX, and SD3.5, Stitch consistently enhances base models, even improving FLUX by 218% on GenEval's Position task and by 206% on PosEval. Stitch achieves state-of-the-art results with Qwen-Image on PosEval, improving over previous models by 54%, all accomplished while integrating position control into leading models training-free. Code is available at https://github.com/ExplainableML/Stitch.