HART: Human Aligned Reconstruction Transformer
作者: Xiyi Chen, Shaofei Wang, Marko Mihajlovic, Taewon Kang, Sergey Prokudin, Ming Lin
分类: cs.CV
发布日期: 2025-09-30
备注: Project page: https://xiyichen.github.io/hart
💡 一句话要点
HART:提出一种对齐人体的重建Transformer,用于稀疏视角人体重建。
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 人体重建 服装建模 稀疏视角 Transformer网络 SMPL-X模型
📋 核心要点
- 现有服装人体重建方法难以处理宽松服装、人与物体的交互以及真实场景中的遮挡问题。
- HART通过预测逐像素的3D信息和人体对应关系,结合遮挡感知的泊松重建,恢复完整几何形状并与SMPL-X模型对齐。
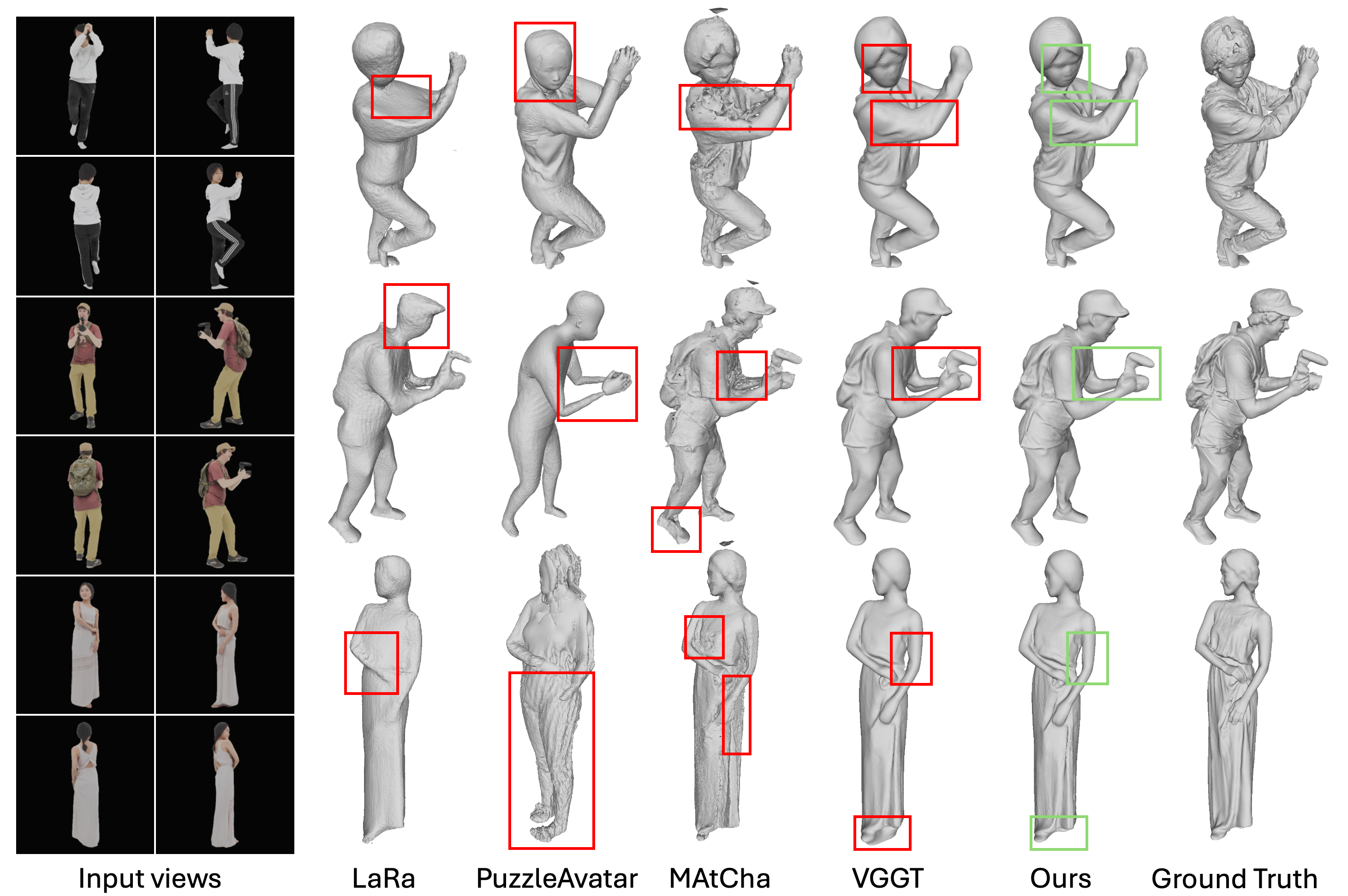
- 实验表明,HART在服装网格重建、SMPL-X估计和新视角合成方面均取得了显著的性能提升,优于现有技术。
📝 摘要(中文)
本文介绍了一种统一的稀疏视角人体重建框架HART。给定少量未校准的人体RGB图像作为输入,HART输出一个水密的服装网格、对齐的SMPL-X人体网格以及用于逼真新视角渲染的高斯溅射表示。以往的服装人体重建方法要么优化参数化模板,忽略了宽松的服装和人与物体的交互,要么在简化的相机假设下训练隐式函数,限制了在真实场景中的应用。相比之下,HART预测逐像素的3D点云图、法线和人体对应关系,并采用一种感知遮挡的泊松重建来恢复完整的几何形状,即使在自遮挡区域也能有效处理。这些预测也与参数化的SMPL-X人体模型对齐,确保重建的几何形状与人体结构保持一致,同时捕捉宽松的服装和交互。这些人体对齐的网格初始化高斯溅射,进一步实现稀疏视角渲染。尽管仅在2.3K个合成扫描数据上训练,HART实现了最先进的结果:服装网格重建的Chamfer距离提高了18-23%,SMPL-X估计的PA-V2V降低了6-27%,新视角合成的LPIPS降低了15-27%。这些结果表明,前馈Transformer可以作为一种可扩展的模型,用于在真实世界环境中进行鲁棒的人体重建。代码和模型将会开源。
🔬 方法详解
问题定义:论文旨在解决从少量未校准的RGB图像中重建具有服装细节的完整人体3D模型的问题。现有方法主要存在两个痛点:一是基于参数化模板的方法难以捕捉宽松服装和人与物体的交互;二是基于隐式函数的方法依赖于简化的相机假设,难以应用于真实场景。
核心思路:HART的核心思路是利用Transformer网络直接预测每个像素的3D信息(点云、法线)和人体对应关系,并结合遮挡感知的泊松重建方法,从而在无需简化相机假设的情况下,恢复具有服装细节的完整人体几何形状。同时,通过与SMPL-X人体模型对齐,保证重建结果与人体结构的一致性。
技术框架:HART的整体框架包含以下几个主要模块:1) 输入少量RGB图像,通过Transformer网络预测每个像素的3D点云、法线和人体对应关系;2) 利用预测的3D信息和人体对应关系,进行遮挡感知的泊松重建,得到完整的人体网格模型;3) 将重建的网格模型与SMPL-X人体模型对齐,保证重建结果与人体结构的一致性;4) 使用人体对齐的网格初始化高斯溅射,用于新视角的渲染。
关键创新:HART的关键创新在于:1) 直接预测逐像素的3D信息和人体对应关系,避免了对参数化模板或隐式函数的依赖;2) 采用遮挡感知的泊松重建方法,能够有效处理自遮挡区域,恢复完整的几何形状;3) 将重建结果与SMPL-X人体模型对齐,保证了重建结果与人体结构的一致性。
关键设计:HART的关键设计包括:1) 使用Transformer网络进行逐像素的3D信息预测,充分利用了Transformer的全局建模能力;2) 设计了遮挡感知的泊松重建方法,能够根据预测的深度信息和法线信息,推断出被遮挡区域的几何形状;3) 使用SMPL-X模型作为先验知识,约束重建结果,保证其与人体结构的一致性。
🖼️ 关键图片
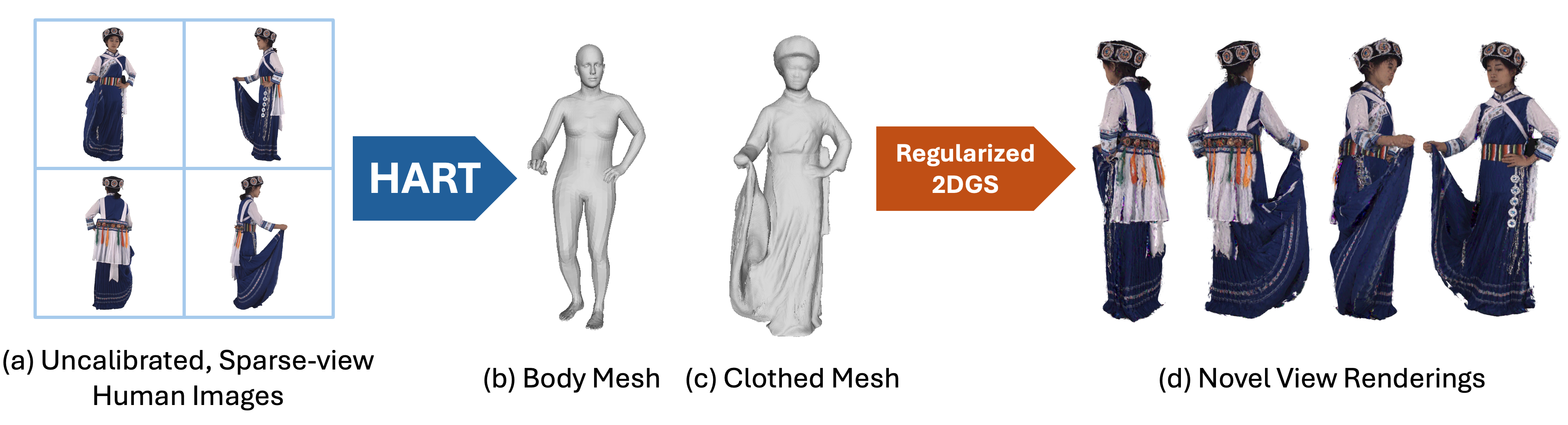

📊 实验亮点
HART在多个数据集上取得了显著的性能提升。在服装网格重建方面,Chamfer距离降低了18-23%;在SMPL-X人体姿态估计方面,PA-V2V降低了6-27%;在新视角合成方面,LPIPS降低了15-27%。这些结果表明,HART在服装人体重建方面具有显著的优势,能够生成更准确、更逼真的人体3D模型。
🎯 应用场景
HART的研究成果可广泛应用于虚拟现实、增强现实、游戏、动画制作等领域。例如,可以用于创建逼真的虚拟化身,实现沉浸式的虚拟体验;也可以用于服装设计和试穿,提高购物效率和用户满意度。此外,该技术还可以应用于运动分析、人机交互等领域,具有重要的实际价值和广阔的应用前景。
📄 摘要(原文)
We introduce HART, a unified framework for sparse-view human reconstruction. Given a small set of uncalibrated RGB images of a person as input, it outputs a watertight clothed mesh, the aligned SMPL-X body mesh, and a Gaussian-splat representation for photorealistic novel-view rendering. Prior methods for clothed human reconstruction either optimize parametric templates, which overlook loose garments and human-object interactions, or train implicit functions under simplified camera assumptions, limiting applicability in real scenes. In contrast, HART predicts per-pixel 3D point maps, normals, and body correspondences, and employs an occlusion-aware Poisson reconstruction to recover complete geometry, even in self-occluded regions. These predictions also align with a parametric SMPL-X body model, ensuring that reconstructed geometry remains consistent with human structure while capturing loose clothing and interactions. These human-aligned meshes initialize Gaussian splats to further enable sparse-view rendering. While trained on only 2.3K synthetic scans, HART achieves state-of-the-art results: Chamfer Distance improves by 18-23 percent for clothed-mesh reconstruction, PA-V2V drops by 6-27 percent for SMPL-X estimation, LPIPS decreases by 15-27 percent for novel-view synthesis on a wide range of datasets. These results suggest that feed-forward transformers can serve as a scalable model for robust human reconstruction in real-world settings. Code and models will be released.