Video Object Segmentation-Aware Audio Generation
作者: Ilpo Viertola, Vladimir Iashin, Esa Rahtu
分类: cs.CV
发布日期: 2025-09-30
备注: Preprint version. The Version of Record is published in DAGM GCPR 2025 proceedings with Springer Lecture Notes in Computer Science (LNCS). Updated results and resources are available at the project page: https://saganet.notion.site
💡 一句话要点
提出SAGANet,通过视频对象分割实现可控音频生成,提升Foley工作流效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频生成 视频对象分割 多模态学习 Foley音效 可控生成
📋 核心要点
- 现有音频生成模型缺乏对特定对象的关注,难以实现精细化控制,限制了其在专业Foley制作中的应用。
- SAGANet通过引入视频对象分割信息,结合视频和文本提示,实现了对特定对象的可控音频生成。
- 实验结果表明,SAGANet在音频生成质量和可控性方面显著优于现有方法,并提出了新的数据集Segmented Music Solos。
📝 摘要(中文)
现有的多模态音频生成模型通常缺乏精确的用户控制,限制了其在专业Foley工作流程中的应用。这些模型侧重于整个视频,无法精确地针对场景中的特定对象进行音频生成,导致产生不必要的背景声音或关注错误的对象。为了解决这个问题,我们提出了视频对象分割感知的音频生成这一新任务,该任务明确地将声音合成与对象级别的分割图联系起来。我们提出了SAGANet,一种新的多模态生成模型,它通过利用视觉分割掩码以及视频和文本提示来实现可控的音频生成。我们的模型为用户提供了对音频生成进行细粒度和视觉局部控制的能力。为了支持这项任务并进一步研究分割感知的Foley,我们提出了Segmented Music Solos,这是一个包含分割信息的乐器演奏视频基准数据集。我们的方法展示了相对于当前最先进方法的显著改进,并为可控、高保真Foley合成设定了新的标准。代码、示例和Segmented Music Solos可在https://saganet.notion.site获取。
🔬 方法详解
问题定义:论文旨在解决多模态音频生成模型缺乏精确用户控制的问题,尤其是在Foley工作流程中。现有模型通常处理整个视频场景,无法针对特定对象生成音频,导致产生不必要的背景噪音或错误的对象关联。这限制了其在需要精细控制的专业场景中的应用。
核心思路:论文的核心思路是将音频生成过程与视频中的对象分割信息相结合。通过显式地将声音合成与对象级别的分割图联系起来,模型可以根据用户指定的对象生成相应的音频,从而实现更精确和可控的音频生成。这种方法允许用户专注于特定对象,避免生成不相关的背景声音。
技术框架:SAGANet模型的整体架构包含视觉编码器、分割编码器、文本编码器和音频解码器。视觉编码器处理视频帧,分割编码器处理对象分割掩码,文本编码器处理文本描述。这些编码器的输出被融合在一起,作为音频解码器的输入,生成最终的音频。该框架允许模型利用多种模态的信息,并根据分割信息对音频生成进行精细控制。
关键创新:该论文的关键创新在于提出了视频对象分割感知的音频生成任务,并设计了SAGANet模型来解决这个问题。与现有方法相比,SAGANet能够利用视觉分割掩码来指导音频生成,从而实现对特定对象音频的精确控制。此外,论文还提出了一个新的数据集Segmented Music Solos,为该任务的研究提供了数据支持。
关键设计:SAGANet的关键设计包括:1) 使用单独的编码器处理视频、分割和文本信息,以充分利用不同模态的特征;2) 设计了一种融合机制,将不同编码器的输出融合在一起,作为音频解码器的输入;3) 使用对抗训练来提高生成音频的质量和真实感;4) 提出了Segmented Music Solos数据集,包含乐器演奏视频和对应的分割信息,为模型训练和评估提供了数据支持。具体参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片
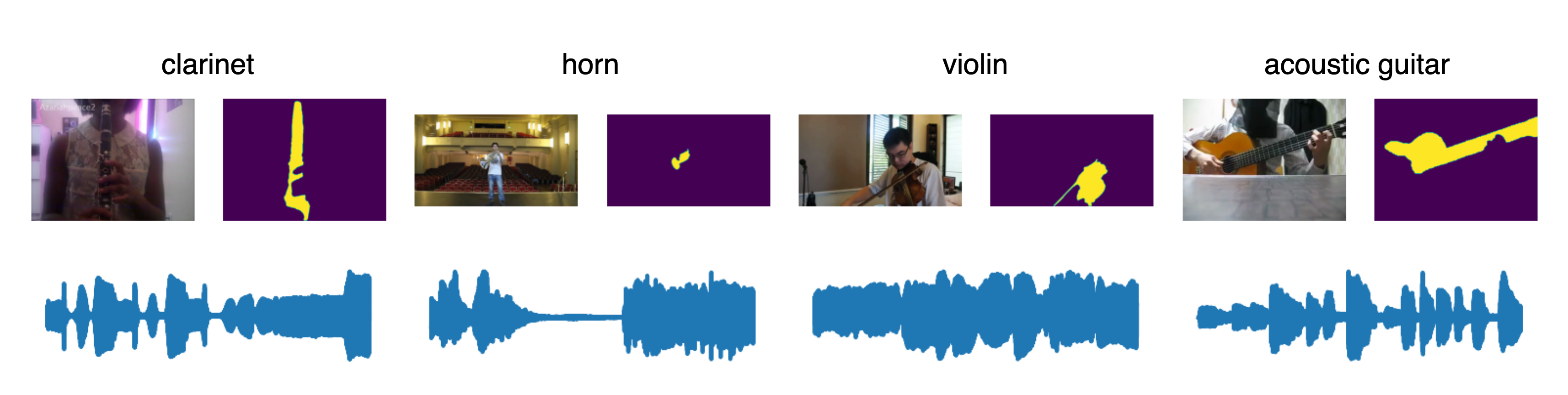
📊 实验亮点
SAGANet在Segmented Music Solos数据集上取得了显著的性能提升,相较于现有最先进的方法,在音频质量和与视频内容的匹配度方面均有明显改善。具体指标提升数据在论文中有详细展示。此外,用户研究表明,SAGANet生成的可控音频更符合用户的期望,能够更好地满足专业Foley制作的需求。
🎯 应用场景
该研究成果可应用于电影、游戏等领域的Foley音效制作,实现对特定对象音效的精确控制和快速生成,提高制作效率和质量。此外,该技术还可用于虚拟现实、增强现实等领域,为用户提供更具沉浸感和互动性的音频体验。未来,该技术有望扩展到更广泛的音频生成领域,例如根据图像或场景描述生成环境音效等。
📄 摘要(原文)
Existing multimodal audio generation models often lack precise user control, which limits their applicability in professional Foley workflows. In particular, these models focus on the entire video and do not provide precise methods for prioritizing a specific object within a scene, generating unnecessary background sounds, or focusing on the wrong objects. To address this gap, we introduce the novel task of video object segmentation-aware audio generation, which explicitly conditions sound synthesis on object-level segmentation maps. We present SAGANet, a new multimodal generative model that enables controllable audio generation by leveraging visual segmentation masks along with video and textual cues. Our model provides users with fine-grained and visually localized control over audio generation. To support this task and further research on segmentation-aware Foley, we propose Segmented Music Solos, a benchmark dataset of musical instrument performance videos with segmentation information. Our method demonstrates substantial improvements over current state-of-the-art methods and sets a new standard for controllable, high-fidelity Foley synthesis. Code, samples, and Segmented Music Solos are available at https://saganet.notion.site