Revealing the Power of Post-Training for Small Language Models via Knowledge Distillation
作者: Miao Rang, Zhenni Bi, Hang Zhou, Hanting Chen, An Xiao, Tianyu Guo, Kai Han, Xinghao Chen, Yunhe Wang
分类: cs.CV
发布日期: 2025-09-30
备注: 7
💡 一句话要点
提出基于知识蒸馏的后训练流程,提升小型语言模型在边缘设备上的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 小型语言模型 知识蒸馏 后训练 边缘计算 课程学习
📋 核心要点
- 大型语言模型计算成本高,难以在边缘设备部署,小型模型性能不足是核心问题。
- 论文提出一种后训练流程,结合课程学习的监督微调和离线知识蒸馏,提升小型模型性能。
- 实验表明,该方法在十亿参数模型中达到SOTA,并在边缘设备上保持了良好的泛化能力和精度。
📝 摘要(中文)
大型语言模型(LLMs)的快速发展显著提升了人工智能在各个领域的能力。然而,它们庞大的规模和高计算成本使其不适合直接部署在资源受限的边缘环境中。这就迫切需要能够在边缘高效运行的高性能小型模型。然而,仅经过预训练后,这些较小的模型通常无法满足复杂任务的性能要求。为了弥合这一差距,我们引入了一个系统的后训练流程,可以有效地提高小型模型的准确性。我们的后训练流程包括基于课程的监督微调(SFT)和离线on-policy知识蒸馏。由此产生的指令调优模型在十亿参数模型中实现了最先进的性能,在严格的硬件约束下表现出强大的泛化能力,同时在各种任务中保持了具有竞争力的准确性。这项工作为在昇腾边缘设备上开发高性能语言模型提供了一个实用而有效的解决方案。
🔬 方法详解
问题定义:论文旨在解决小型语言模型(小于十亿参数)在边缘设备上部署时,性能不足的问题。现有的小型模型虽然计算效率高,但经过预训练后,在复杂任务上的表现往往无法满足实际需求,需要进一步提升其性能。
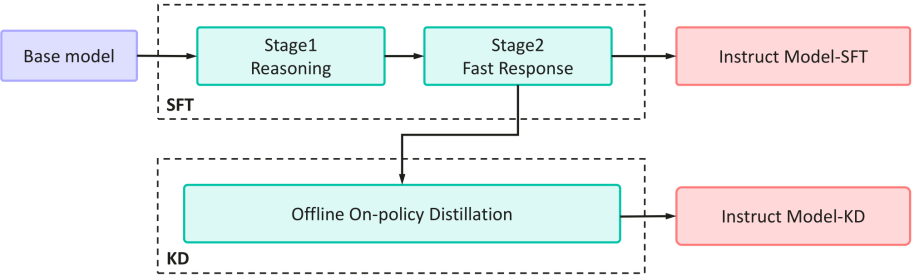
核心思路:论文的核心思路是通过后训练(Post-Training)的方式,在预训练模型的基础上,利用知识蒸馏技术,将大型模型的知识迁移到小型模型中,从而提升小型模型的性能。同时,采用课程学习(Curriculum Learning)策略,逐步增加训练难度,使模型更好地学习和泛化。
技术框架:论文提出的后训练流程主要包含两个阶段:1) 基于课程的监督微调(Curriculum-based Supervised Fine-tuning, SFT):使用精心设计的课程,逐步增加训练数据的难度,对小型模型进行微调,使其初步具备指令遵循能力。2) 离线On-Policy知识蒸馏:利用大型教师模型生成高质量的训练数据,然后使用这些数据对小型学生模型进行知识蒸馏,进一步提升其性能。整个流程是离线的,避免了在线交互带来的计算开销。
关键创新:论文的关键创新在于将课程学习和离线On-Policy知识蒸馏相结合,形成一个高效的后训练流程。课程学习能够帮助模型更好地适应不同难度的任务,而离线On-Policy知识蒸馏则能够有效地将大型模型的知识迁移到小型模型中。此外,针对边缘设备的资源约束,论文特别关注模型的效率和泛化能力。
关键设计:在课程学习阶段,论文设计了一套逐步增加难度的训练数据。在知识蒸馏阶段,采用了On-Policy的方式生成训练数据,保证了数据质量。具体的损失函数可能包括交叉熵损失、KL散度损失等,用于衡量学生模型和教师模型之间的差异。网络结构方面,可能采用Transformer结构,并针对边缘设备的特点进行优化,例如模型剪枝、量化等。
🖼️ 关键图片
📊 实验亮点
该论文提出的后训练流程在十亿参数模型中取得了SOTA性能,证明了其有效性。具体性能数据未知,但强调了在严格硬件约束下,模型仍能保持强大的泛化能力和具有竞争力的准确性。这表明该方法在边缘设备上具有很高的实用价值。
🎯 应用场景
该研究成果可广泛应用于资源受限的边缘设备上,例如智能家居、自动驾驶、智能安防等领域。通过提升小型语言模型的性能,可以使这些设备具备更强的自然语言处理能力,从而实现更智能、更高效的应用。例如,在智能家居中,可以实现更自然的语音交互;在自动驾驶中,可以实现更精准的语音控制和场景理解。
📄 摘要(原文)
The rapid advancement of large language models (LLMs) has significantly advanced the capabilities of artificial intelligence across various domains. However, their massive scale and high computational costs render them unsuitable for direct deployment in resource-constrained edge environments. This creates a critical need for high-performance small models that can operate efficiently at the edge. Yet, after pre-training alone, these smaller models often fail to meet the performance requirements of complex tasks. To bridge this gap, we introduce a systematic post-training pipeline that efficiently enhances small model accuracy. Our post training pipeline consists of curriculum-based supervised fine-tuning (SFT) and offline on-policy knowledge distillation. The resulting instruction-tuned model achieves state-of-the-art performance among billion-parameter models, demonstrating strong generalization under strict hardware constraints while maintaining competitive accuracy across a variety of tasks. This work provides a practical and efficient solution for developing high-performance language models on Ascend edge devices.