TimeScope: Towards Task-Oriented Temporal Grounding In Long Videos
作者: Xiangrui Liu, Minghao Qin, Yan Shu, Zhengyang Liang, Yang Tian, Chen Jason Zhang, Bo Zhao, Zheng Liu
分类: cs.CV, cs.AI
发布日期: 2025-09-30 (更新: 2025-12-08)
💡 一句话要点
提出TimeScope,解决长视频中面向任务的时序定位难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时序定位 长视频理解 任务驱动 渐进式推理 思维链 视频分析 深度学习
📋 核心要点
- 现有时序定位方法难以处理需要深度任务理解和细粒度定位的长视频任务。
- TimeScope通过渐进式推理实现由粗到精的定位,并利用思维链数据进行微调。
- 实验表明TimeScope在定位精度、下游任务性能和泛化能力方面均优于现有方法。
📝 摘要(中文)
本文提出了一种新的时序定位问题形式——面向任务的时序定位(ToTG),它由下游任务的需求驱动,而非显式的时间间隔描述。例如,ToTG的输入可能是“解释视频中该男子被送往医院的原因”,而传统的TG则需要“该男子被石头绊倒并摔倒在地面的时刻”这样的显式时间描述。这种新的ToTG形式对现有的TG方法提出了重大挑战,因为它需要联合执行深度任务理解和长视频中的细粒度时序定位。为了应对这些挑战,我们进行了一系列系统的研究。首先,我们构建了一个新的基准ToTG-Bench,它全面评估了不同设置下的ToTG性能。其次,我们引入了一种新的时序定位方法TimeScope,它通过渐进式推理过程执行由粗到精的定位。通过对来自各种场景的精心策划的思维链(CoT)数据进行广泛的监督微调,TimeScope可以在任务和领域之间有效地泛化。我们的评估表明,TimeScope在以下三个方面优于现有的基线:(1)在定位精度方面有显著提高,(2)对下游任务有显著的好处,以及(3)在不同场景中具有很强的泛化能力。所有模型、数据集和源代码将完全开源,以支持该领域未来的研究。
🔬 方法详解
问题定义:论文旨在解决长视频中面向任务的时序定位(ToTG)问题。现有方法主要依赖于显式的时间描述,无法处理需要深度任务理解和细粒度定位的复杂场景。这些方法在理解任务需求和将任务需求与视频内容关联方面存在不足,导致定位精度较低。
核心思路:TimeScope的核心思路是通过渐进式推理实现由粗到精的时序定位。它首先进行粗粒度的时序范围确定,然后逐步细化定位结果。这种方法允许模型在全局范围内理解视频内容,并逐步聚焦到与任务相关的关键时间段。此外,论文还利用思维链(CoT)数据进行微调,以提高模型的推理能力和泛化能力。
技术框架:TimeScope的整体架构包含以下几个主要阶段:1) 任务理解模块:用于理解输入任务的需求;2) 粗粒度定位模块:用于确定包含相关事件的粗略时间范围;3) 细粒度定位模块:用于在粗略时间范围内精确定位目标时间段;4) 推理模块:利用思维链数据进行推理,提高定位的准确性和可靠性。这些模块协同工作,实现面向任务的时序定位。
关键创新:TimeScope最重要的技术创新点在于其渐进式推理和思维链微调。渐进式推理允许模型从全局到局部逐步定位,避免了直接进行细粒度定位的困难。思维链微调则通过引入中间推理步骤,提高了模型的理解能力和推理能力,使其能够更好地理解任务需求和视频内容之间的关系。
关键设计:TimeScope的关键设计包括:1) 粗粒度定位模块采用基于Transformer的模型,用于捕捉视频中的长程依赖关系;2) 细粒度定位模块采用卷积神经网络,用于提取局部时序特征;3) 损失函数包括定位损失和推理损失,用于优化模型的定位精度和推理能力;4) 思维链数据通过人工标注或自动生成的方式获得,用于微调模型的推理能力。
🖼️ 关键图片


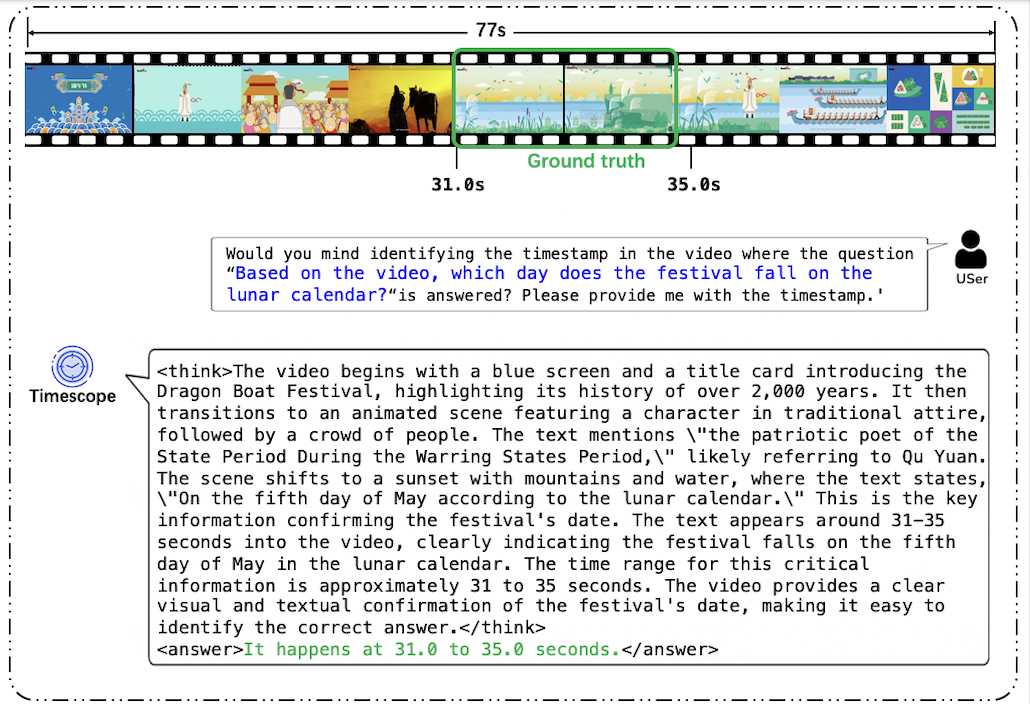
📊 实验亮点
TimeScope在ToTG-Bench基准测试中取得了显著的性能提升,在定位精度方面优于现有基线方法。实验结果表明,TimeScope不仅提高了时序定位的准确性,还对下游任务产生了积极影响。此外,TimeScope在不同场景下表现出强大的泛化能力,证明了其在实际应用中的潜力。
🎯 应用场景
TimeScope可应用于视频内容理解、智能监控、视频搜索、教育视频分析等领域。例如,在智能监控中,可以根据用户提出的任务(如“检测可疑人员”),自动定位视频中相关的时间段。在教育视频分析中,可以根据学生提出的问题,快速定位到视频中解答问题的部分,提高学习效率。该研究有助于提升机器对长视频内容的理解和利用能力。
📄 摘要(原文)
Identifying key temporal intervals within long videos, known as temporal grounding (TG), is important to video understanding and reasoning tasks. In this paper, we introduce a new form of the temporal grounding problem, \textbf{Task-oriented Temporal Grounding} (\textbf{ToTG}), which is driven by the requirements of downstream tasks rather than explicit time-interval descriptions. For example, a ToTG input may be "explain why the man in the video is sent to the hospital," whereas traditional TG would take an explicit temporal description such as "the moments when the man is tripped by a stone and falls to the ground." This new ToTG formulation presents significant challenges for existing TG methods, as it requires jointly performing deep task comprehension and fine-grained temporal localization within long videos. To address these challenges, we conduct a systematic set of studies. First, we construct \textbf{a new benchmark ToTG-Bench}, which comprehensively evaluates ToTG performance across diverse settings. Second, we introduce \textbf{a new temporal-ground method TimeScope}, which performs coarse-to-fine localization through a progressive reasoning process. Leveraging extensive supervised fine-tuning with carefully curated chain-of-thought (CoT) data from a variety of scenarios, TimeScope generalizes effectively across tasks and domains. Our evaluation demonstrates \textbf{TimeScope's empirical advantages} over existing baselines from three perspectives: (1) substantial improvements in grounding precision, (2) significant benefits to downstream tasks, and (3) strong generalizability across different scenarios. All models, datasets, and source code will be fully open-sourced to support future research in this area.