ProfVLM: A Lightweight Video-Language Model for Multi-View Proficiency Estimation
作者: Edoardo Bianchi, Jacopo Staiano, Antonio Liotta
分类: cs.CV, cs.CL
发布日期: 2025-09-30 (更新: 2026-01-14)
💡 一句话要点
ProfVLM:一种轻量级视频语言模型,用于多视角熟练度评估
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 视频语言模型 动作质量评估 技能熟练度估计 多视角学习 生成式建模
📋 核心要点
- 现有动作质量评估方法通常将其视为分类问题,缺乏可解释的推理过程,无法提供专家级的反馈。
- ProfVLM将该任务重构为生成式视觉语言建模,通过预测熟练度等级并生成自然语言反馈来实现可解释的评估。
- 实验表明,ProfVLM在性能上超越了现有方法,同时显著减少了参数量和训练时间,提升了效率。
📝 摘要(中文)
本文将动作质量评估和技能熟练度估计重新定义为生成式视觉语言建模任务,并提出了ProfVLM,一个紧凑的模型,可以联合预测熟练度等级,并从多视角视频中生成专家级的自然语言反馈。ProfVLM利用条件语言生成,提供可操作的见解以及量化评估分数。该方法的核心是一个AttentiveGatedProjector,它动态地融合来自冻结的TimeSformer骨干网络的多视角第一人称和第三人称特征,并将它们投影到为反馈生成而微调的语言模型中。在EgoExo4D数据集上,ProfVLM超越了现有方法,同时参数量减少了高达20倍,训练时间减少了高达60%。通过提供与性能水平对齐的自然语言评论,这项工作表明,生成式视觉语言建模为可解释的动作质量评估提供了一种强大而高效的范式转变。
🔬 方法详解
问题定义:现有动作质量评估和技能熟练度估计方法通常被视为分类问题,直接输出离散的标签,缺乏可解释的推理过程,无法提供专家级的自然语言反馈,难以帮助学习者改进。这些方法通常需要大量的参数和训练资源。
核心思路:ProfVLM的核心思路是将动作质量评估任务转化为一个生成式视觉语言建模问题。通过联合预测熟练度等级和生成自然语言反馈,模型不仅可以提供量化的评估分数,还可以提供可操作的建议,从而实现更具解释性和指导性的评估。这种方法利用了语言模型的生成能力,使其能够模拟专家的思维过程,并以自然语言的形式表达出来。
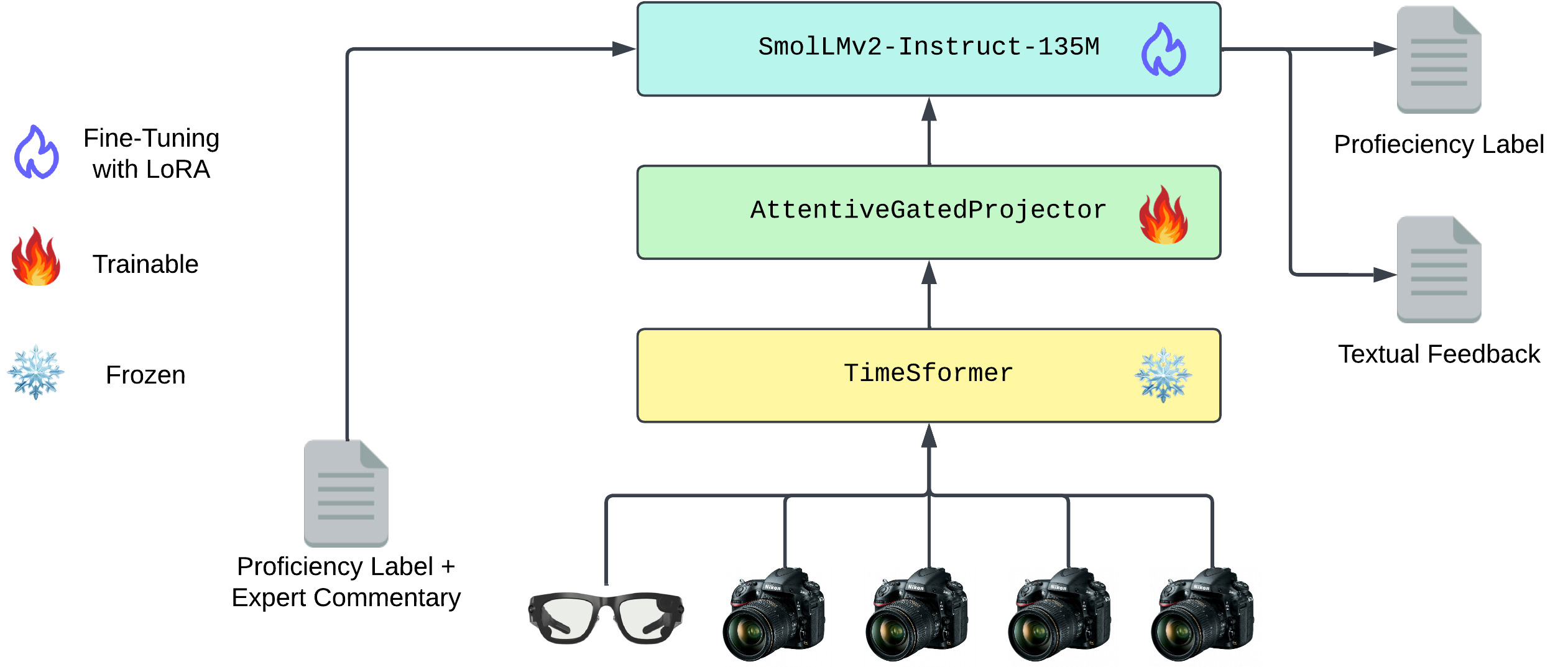
技术框架:ProfVLM的整体架构包括以下几个主要模块:1) TimeSformer骨干网络:用于提取多视角视频的视觉特征,该网络被冻结以减少训练成本。2) AttentiveGatedProjector:用于动态融合和投影来自不同视角的视觉特征,并将其映射到语言模型的嵌入空间。3) 语言模型:用于生成熟练度等级和自然语言反馈,该模型经过微调以适应特定的评估任务。整个流程是,首先使用TimeSformer提取视频特征,然后通过AttentiveGatedProjector融合多视角特征,最后使用语言模型生成评估结果和反馈。
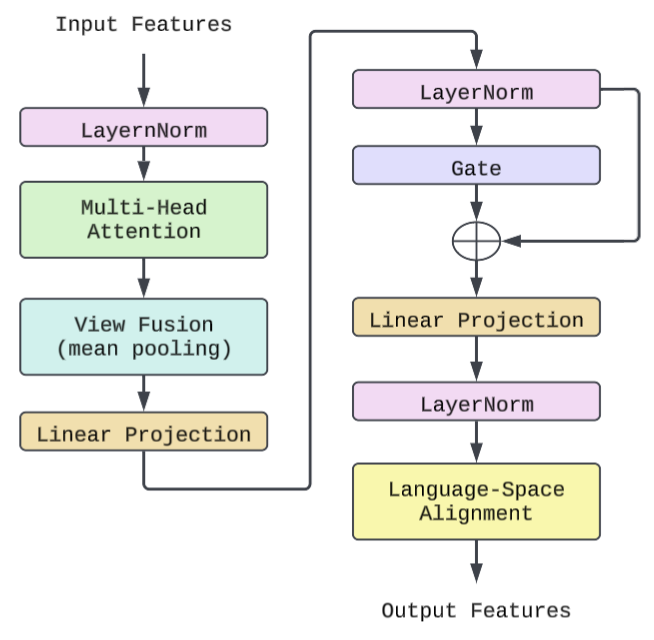
关键创新:ProfVLM最重要的技术创新点在于将动作质量评估任务转化为生成式视觉语言建模问题,并提出了AttentiveGatedProjector来动态融合多视角特征。这种方法不仅提高了评估的准确性和可解释性,还显著减少了模型的参数量和训练时间。与现有基于分类的方法相比,ProfVLM能够提供更丰富、更具指导性的评估结果。
关键设计:AttentiveGatedProjector是ProfVLM的关键组件,它使用注意力机制来动态地融合来自不同视角的视觉特征。具体来说,它首先计算每个视角的注意力权重,然后使用这些权重来加权融合不同视角的特征。此外,AttentiveGatedProjector还使用门控机制来控制信息的流动,从而提高模型的鲁棒性。损失函数包括熟练度等级预测的交叉熵损失和自然语言反馈生成的语言模型损失。
🖼️ 关键图片
📊 实验亮点
ProfVLM在EgoExo4D数据集上取得了显著的性能提升,超越了现有的state-of-the-art方法。更重要的是,ProfVLM的参数量减少了高达20倍,训练时间减少了高达60%,这使得它更易于部署和应用。实验结果表明,ProfVLM不仅能够准确地预测熟练度等级,还能够生成高质量的自然语言反馈,为学习者提供有价值的指导。
🎯 应用场景
ProfVLM可应用于各种需要动作质量评估和技能熟练度估计的领域,例如体育训练、康复治疗、手术技能评估等。通过提供量化评估和专家级反馈,它可以帮助学习者更快地掌握技能,提高训练效率。此外,ProfVLM还可以用于自动化评估系统,减少人工评估的成本和主观性。未来,该模型可以扩展到其他类型的动作和技能评估任务。
📄 摘要(原文)
Existing approaches treat action quality assessment and skill proficiency estimation as classification problems, outputting discrete labels without interpretable reasoning. We reformulate this task as generative vision language modeling, introducing ProfVLM, a compact model that jointly predicts proficiency levels and generates expert-like natural language feedback from multi-view videos. ProfVLM leverages conditional language generation to provide actionable insights along with quantitative evaluation scores. Central to our method is an AttentiveGatedProjector that dynamically fuses and projects multi-view egocentric and exocentric features from a frozen TimeSformer backbone into a language model fine-tuned for feedback generation. Trained on EgoExo4D with expert commentaries, ProfVLM surpasses state-of-the-art methods while using up to 20x fewer parameters and reducing training time by up to 60% compared to existing classification-based methods. By providing natural language critiques aligned with performance levels, this work shows that generative vision-language modeling offers a powerful and efficient paradigm shift for interpretable action quality assessment.