PRPO: Paragraph-level Policy Optimization for Vision-Language Deepfake Detection
作者: Tuan Nguyen, Naseem Khan, Khang Tran, NhatHai Phan, Issa Khalil
分类: cs.CV, cs.LG
发布日期: 2025-09-30 (更新: 2025-10-01)
💡 一句话要点
提出PRPO算法,通过段落级策略优化提升视觉-语言大模型在Deepfake检测中的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Deepfake检测 多模态学习 大型语言模型 强化学习 策略优化 视觉推理 段落级优化
📋 核心要点
- 现有Deepfake检测方法受限于高质量数据集的匮乏,且多模态大模型推理结果与视觉证据不一致。
- 论文提出段落级相对策略优化(PRPO)算法,通过强化学习将LLM推理与图像内容在段落级别对齐。
- 实验结果表明,PRPO显著提升了Deepfake检测的准确率和推理分数,优于现有方法。
📝 摘要(中文)
合成媒体的快速发展使得Deepfake检测成为在线安全和信任的关键挑战。然而,高质量大型数据集的稀缺限制了该领域的进展。尽管多模态大型语言模型(LLM)展现出强大的推理能力,但它们在Deepfake检测方面的表现较差,常常产生与视觉证据不符或虚假的解释。为了解决这一局限性,我们引入了一个用于Deepfake检测的推理标注数据集,并提出了一种段落级相对策略优化(PRPO)的强化学习算法,该算法在段落级别将LLM推理与图像内容对齐。实验表明,PRPO显著提高了检测准确率,并实现了4.55/5.0的最高推理分数。消融研究进一步表明,PRPO在测试时条件下明显优于GRPO。这些结果强调了将多模态推理扎根于视觉证据的重要性,从而实现更可靠和可解释的Deepfake检测。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(LLM)在Deepfake检测中表现不佳的问题。现有方法的痛点在于,LLM的推理结果常常与视觉证据不符,甚至产生幻觉,导致检测准确率低,可解释性差。缺乏高质量的、带有推理标注的Deepfake数据集也限制了模型性能的提升。
核心思路:论文的核心思路是通过强化学习,对LLM的推理过程进行优化,使其更好地与视觉证据对齐。具体而言,论文提出了一种段落级相对策略优化(PRPO)算法,该算法在段落级别对LLM的推理过程进行奖励或惩罚,从而引导LLM生成更符合视觉证据的推理结果。这种段落级别的优化能够更精细地控制LLM的推理过程,避免产生与视觉证据不符的结论。
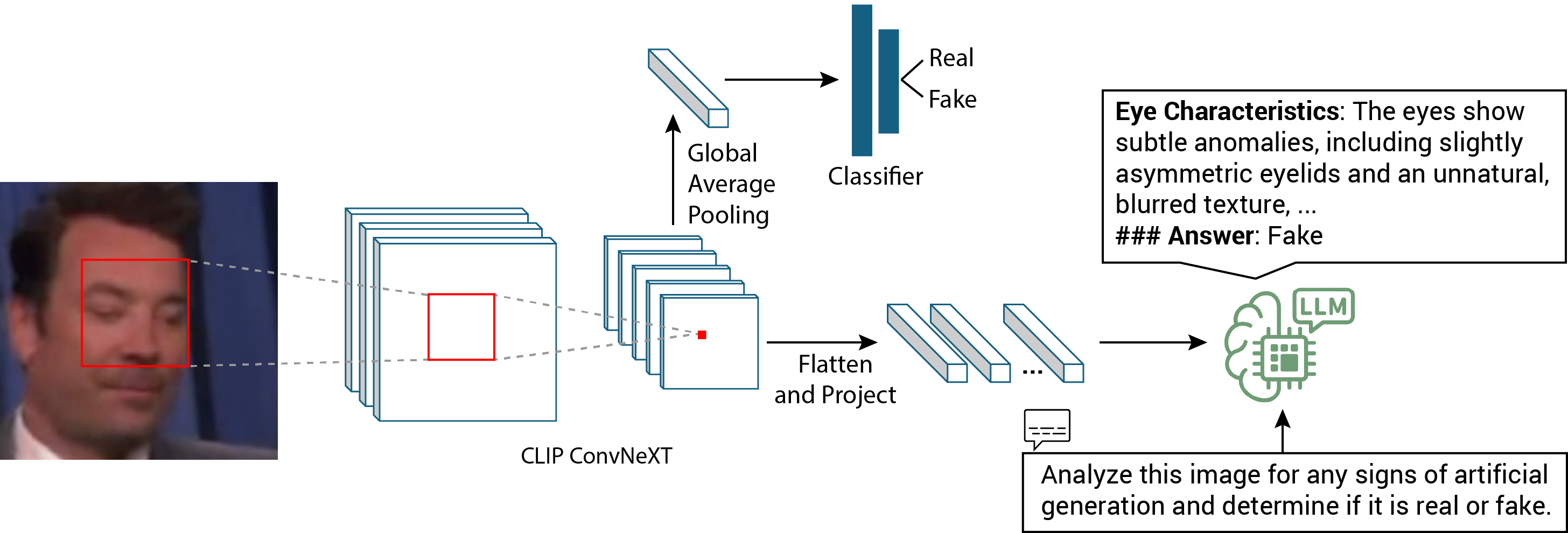
技术框架:PRPO算法的技术框架主要包括以下几个模块:1) 一个多模态LLM,用于生成Deepfake检测的推理过程;2) 一个奖励模型,用于评估LLM生成的推理过程与视觉证据的对齐程度;3) 一个强化学习算法,用于优化LLM的推理策略,使其生成更符合视觉证据的推理结果。整个流程是,首先LLM根据输入的图像和文本生成一段推理过程,然后奖励模型对该推理过程的每个段落进行评估,给出奖励或惩罚,最后强化学习算法根据奖励模型的反馈,调整LLM的推理策略。
关键创新:论文最重要的技术创新点在于提出了段落级相对策略优化(PRPO)算法。与传统的策略优化算法相比,PRPO算法能够更精细地控制LLM的推理过程,避免产生与视觉证据不符的结论。此外,论文还构建了一个用于Deepfake检测的推理标注数据集,为训练和评估PRPO算法提供了数据支持。
关键设计:PRPO算法的关键设计包括:1) 使用段落级别的奖励信号,对LLM的推理过程进行更精细的控制;2) 使用相对策略优化算法,避免了直接优化策略的困难;3) 设计了一个能够准确评估推理过程与视觉证据对齐程度的奖励模型。奖励模型的设计至关重要,论文可能采用了对比学习或者其他技术来训练奖励模型,使其能够区分符合视觉证据的推理和不符合视觉证据的推理。具体的损失函数和网络结构等细节在论文中应该有更详细的描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PRPO算法在Deepfake检测准确率方面取得了显著提升,并实现了4.55/5.0的最高推理分数。消融研究表明,PRPO在测试时条件下明显优于GRPO,证明了段落级策略优化的有效性。这些结果表明,将多模态推理扎根于视觉证据对于提高Deepfake检测的可靠性和可解释性至关重要。
🎯 应用场景
该研究成果可应用于在线社交媒体平台、新闻媒体机构等,用于自动检测和识别Deepfake内容,从而维护网络安全和信息真实性。未来,该技术可进一步扩展到其他多模态内容真实性检测领域,例如音频和视频篡改检测,具有重要的社会价值。
📄 摘要(原文)
The rapid rise of synthetic media has made deepfake detection a critical challenge for online safety and trust. Progress remains constrained by the scarcity of large, high-quality datasets. Although multimodal large language models (LLMs) exhibit strong reasoning capabilities, their performance on deepfake detection is poor, often producing explanations that are misaligned with visual evidence or hallucinatory. To address this limitation, we introduce a reasoning-annotated dataset for deepfake detection and propose Paragraph-level Relative Policy Optimization (PRPO), a reinforcement learning algorithm that aligns LLM reasoning with image content at the paragraph level. Experiments show that PRPO improves detection accuracy by a wide margin and achieves the highest reasoning score of 4.55/5.0. Ablation studies further demonstrate that PRPO significantly outperforms GRPO under test-time conditions. These results underscore the importance of grounding multimodal reasoning in visual evidence to enable more reliable and interpretable deepfake detection.