An Experimental Study on Generating Plausible Textual Explanations for Video Summarization
作者: Thomas Eleftheriadis, Evlampios Apostolidis, Vasileios Mezaris
分类: cs.CV, cs.AI
发布日期: 2025-09-30
备注: IEEE CBMI 2025. This is the authors' accepted version. The final publication is available at https://ieeexplore.ieee.org/
💡 一句话要点
提出一种基于大模型和语义重叠的视频摘要可信解释生成与评估方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频摘要 可解释AI 多模态学习 合理性评估 语义重叠
📋 核心要点
- 现有视频摘要解释方法缺乏对解释合理性的有效评估,难以保证与人类认知对齐。
- 利用大型多模态模型生成视觉解释的文本描述,并通过语义重叠度量评估合理性。
- 实验表明,该方法可有效评估视频摘要解释的合理性,并为生成更合理的解释提供指导。
📝 摘要(中文)
本文提出了一项关于为视频摘要结果生成合理文本解释的实验研究。为了满足这项研究的需求,我们扩展了一个现有的视频摘要多粒度解释框架,通过集成一个最先进的大型多模态模型(LLaVA-OneVision),并提示它生成对所获得的视觉解释的自然语言描述。 接下来,我们专注于可解释AI最期望的特征之一,即所获得的解释的合理性,这与它们与人类的推理和期望的一致性有关。 使用扩展的框架,我们提出了一种通过量化其文本描述与相应视频摘要的文本描述之间的语义重叠来评估视觉解释合理性的方法,借助两种用于创建句子嵌入的方法(SBERT,SimCSE)。 基于扩展的框架和提出的合理性评估方法,我们使用一种最先进的方法(CA-SUM)和两个用于视频摘要的数据集(SumMe,TVSum)进行了一项实验研究,以检验更忠实的解释是否也是更合理的解释,并确定用于为视频摘要生成合理文本解释的最合适方法。
🔬 方法详解
问题定义:视频摘要旨在从长视频中提取关键帧或片段,生成简洁的视频概要。然而,现有的视频摘要方法通常缺乏透明性,难以解释其决策过程。因此,为视频摘要生成合理且可信的解释至关重要,这有助于用户理解和信任摘要结果。现有方法在评估解释的合理性方面存在不足,缺乏与人类认知对齐的有效度量。
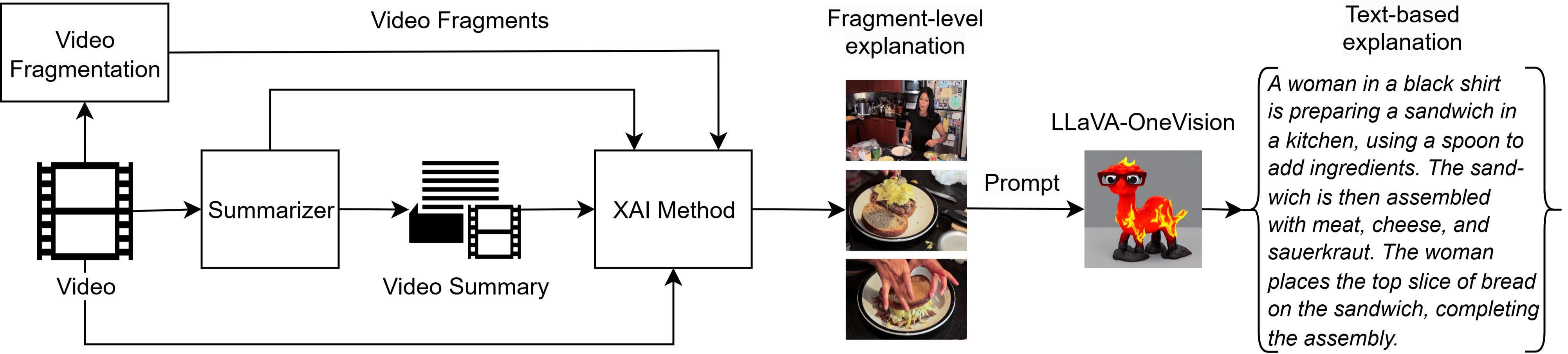
核心思路:本文的核心思路是利用大型多模态模型(LLaVA-OneVision)生成视频摘要视觉解释的文本描述,然后通过计算这些文本描述与视频摘要本身的文本描述之间的语义重叠度来评估解释的合理性。这种方法基于一个假设:如果一个解释与视频摘要的内容高度相关,那么它就更可能被认为是合理的。
技术框架:该框架主要包含以下几个步骤:1) 使用现有的视频摘要方法(如CA-SUM)生成视频摘要;2) 利用多粒度解释框架生成视觉解释;3) 使用LLaVA-OneVision模型将视觉解释转换为自然语言描述;4) 使用SBERT或SimCSE等句子嵌入模型将解释的文本描述和视频摘要的文本描述转换为向量表示;5) 计算两个向量之间的余弦相似度,作为语义重叠度的度量,从而评估解释的合理性。
关键创新:该方法的主要创新在于:1) 将大型多模态模型应用于视频摘要解释的生成,利用其强大的视觉理解和文本生成能力;2) 提出了一种基于语义重叠度的合理性评估方法,该方法能够量化解释与视频摘要内容的相关性,从而更客观地评估解释的质量;3) 将合理性评估与忠实性评估相结合,探讨了两者之间的关系,为生成更合理且忠实的视频摘要解释提供了指导。
关键设计:在实验中,使用了CA-SUM作为视频摘要方法,SumMe和TVSum作为数据集。LLaVA-OneVision模型用于生成视觉解释的文本描述。SBERT和SimCSE两种句子嵌入模型用于计算语义重叠度。余弦相似度被用作语义重叠度的度量。实验中还比较了不同解释生成方法和不同句子嵌入模型对合理性评估结果的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,基于语义重叠度的合理性评估方法能够有效区分不同解释的质量。更忠实的解释通常也更合理,但两者之间并非完全一致。使用SBERT进行句子嵌入通常能够获得更好的合理性评估结果。该研究为视频摘要解释的生成和评估提供了一种新的思路。
🎯 应用场景
该研究成果可应用于视频监控、新闻报道、教育视频等领域,提升视频摘要的可解释性和用户信任度。通过提供合理的解释,用户可以更好地理解视频摘要的内容和生成过程,从而更有效地利用视频信息。未来,该方法可进一步扩展到其他视频分析任务,如视频分类、视频检索等。
📄 摘要(原文)
In this paper, we present our experimental study on generating plausible textual explanations for the outcomes of video summarization. For the needs of this study, we extend an existing framework for multigranular explanation of video summarization by integrating a SOTA Large Multimodal Model (LLaVA-OneVision) and prompting it to produce natural language descriptions of the obtained visual explanations. Following, we focus on one of the most desired characteristics for explainable AI, the plausibility of the obtained explanations that relates with their alignment with the humans' reasoning and expectations. Using the extended framework, we propose an approach for evaluating the plausibility of visual explanations by quantifying the semantic overlap between their textual descriptions and the textual descriptions of the corresponding video summaries, with the help of two methods for creating sentence embeddings (SBERT, SimCSE). Based on the extended framework and the proposed plausibility evaluation approach, we conduct an experimental study using a SOTA method (CA-SUM) and two datasets (SumMe, TVSum) for video summarization, to examine whether the more faithful explanations are also the more plausible ones, and identify the most appropriate approach for generating plausible textual explanations for video summarization.