SETR: A Two-Stage Semantic-Enhanced Framework for Zero-Shot Composed Image Retrieval
作者: Yuqi Xiao, Yingying Zhu
分类: cs.CV
发布日期: 2025-09-30
💡 一句话要点
提出SETR:一种语义增强的两阶段框架,用于零样本组合图像检索
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 组合图像检索 多模态学习 语义增强 两阶段检索
📋 核心要点
- 现有零样本组合图像检索方法依赖联合特征融合,易受无关背景干扰,影响检索精度。
- SETR采用交集驱动策略进行粗检索,过滤干扰信息,并使用多模态LLM进行细粒度重排序。
- 实验表明,SETR在多个数据集上取得了SOTA性能,CIRR数据集Recall@1提升高达15.15%。
📝 摘要(中文)
零样本组合图像检索(ZS-CIR)旨在给定参考图像和相关文本的情况下检索目标图像,而无需昂贵的三元组标注。现有的基于CLIP的方法面临两个核心挑战:(1)基于联合的特征融合无差别地聚合所有视觉线索,携带了不相关的背景细节,从而稀释了预期的修改;(2)来自CLIP嵌入的全局余弦相似性缺乏解决细粒度语义关系的能力。为了解决这些问题,我们提出了SETR(语义增强的两阶段检索)。在粗检索阶段,SETR引入了一种交集驱动策略,仅保留参考图像和相关文本之间的重叠语义,从而过滤掉联合融合固有的干扰因素,并产生更清晰、高精度的候选集。在细粒度重排序阶段,我们采用具有低秩自适应的预训练多模态LLM来进行二元语义相关性判断(“是/否”),通过显式验证关系和属性级别的连贯性,超越了CLIP的全局特征匹配。这两个阶段共同形成了一个互补的流程:粗检索以高召回率缩小候选池,而重排序确保与细微的文本修改精确对齐。在CIRR、Fashion-IQ和CIRCO上的实验表明,SETR实现了新的最先进性能,在CIRR上将Recall@1提高了高达15.15个百分点。我们的结果确立了两阶段推理作为鲁棒且可移植的ZS-CIR的通用范例。
🔬 方法详解
问题定义:零样本组合图像检索(ZS-CIR)旨在根据给定的参考图像和文本描述,检索经过文本描述修改后的目标图像。现有方法,特别是基于CLIP的方法,主要存在两个痛点:一是直接融合参考图像和文本的特征,导致无关背景信息的干扰;二是依赖全局余弦相似度进行匹配,无法捕捉细粒度的语义关系。
核心思路:SETR的核心思路是将检索过程分解为两个阶段:粗检索和细粒度重排序。粗检索阶段旨在快速过滤掉大部分不相关的图像,保留具有较高召回率的候选集;细粒度重排序阶段则对候选集进行更精确的语义匹配,提高检索精度。这种两阶段的设计旨在兼顾检索效率和准确性。
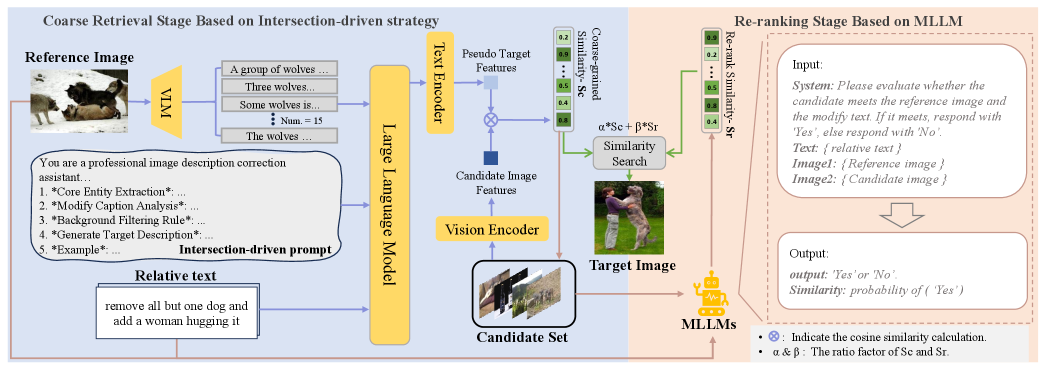
技术框架:SETR框架包含两个主要阶段:1) 粗检索阶段:使用交集驱动策略,提取参考图像和文本描述的共享语义信息,生成候选图像集合。2) 细粒度重排序阶段:利用预训练的多模态LLM,对候选图像进行二元语义相关性判断(是/否),根据判断结果对候选图像进行排序。
关键创新:SETR的关键创新在于:1) 提出了交集驱动的特征提取方法,有效过滤了无关背景信息,提高了粗检索的精度。2) 引入了预训练的多模态LLM进行细粒度语义匹配,能够捕捉更复杂的关系和属性级别的语义信息,超越了传统的全局特征匹配方法。3) 将检索过程分解为粗检索和细粒度重排序两个阶段,形成了一个互补的流程,兼顾了检索效率和准确性。
关键设计:在粗检索阶段,具体实现细节未知,但强调了“交集驱动”策略,即提取参考图像和文本描述的共享语义信息。在细粒度重排序阶段,使用了预训练的多模态LLM,并通过Low-Rank Adaptation (LoRA) 进行微调,以适应特定的检索任务。损失函数和网络结构的具体细节未知。
🖼️ 关键图片


📊 实验亮点
SETR在CIRR、Fashion-IQ和CIRCO三个数据集上均取得了显著的性能提升。在CIRR数据集上,SETR的Recall@1指标提升了高达15.15个百分点,表明其在处理复杂组合图像检索任务方面的优越性。实验结果证明了两阶段推理是解决零样本组合图像检索问题的有效范例。
🎯 应用场景
SETR在电商、时尚、室内设计等领域具有广泛的应用前景。例如,用户可以通过上传一张家具图片并描述修改需求(如“颜色改为蓝色”),快速检索到符合要求的商品。该研究有助于提升图像检索的准确性和用户体验,并为零样本学习在实际场景中的应用提供了新的思路。
📄 摘要(原文)
Zero-shot Composed Image Retrieval (ZS-CIR) aims to retrieve a target image given a reference image and a relative text, without relying on costly triplet annotations. Existing CLIP-based methods face two core challenges: (1) union-based feature fusion indiscriminately aggregates all visual cues, carrying over irrelevant background details that dilute the intended modification, and (2) global cosine similarity from CLIP embeddings lacks the ability to resolve fine-grained semantic relations. To address these issues, we propose SETR (Semantic-enhanced Two-Stage Retrieval). In the coarse retrieval stage, SETR introduces an intersection-driven strategy that retains only the overlapping semantics between the reference image and relative text, thereby filtering out distractors inherent to union-based fusion and producing a cleaner, high-precision candidate set. In the fine-grained re-ranking stage, we adapt a pretrained multimodal LLM with Low-Rank Adaptation to conduct binary semantic relevance judgments ("Yes/No"), which goes beyond CLIP's global feature matching by explicitly verifying relational and attribute-level consistency. Together, these two stages form a complementary pipeline: coarse retrieval narrows the candidate pool with high recall, while re-ranking ensures precise alignment with nuanced textual modifications. Experiments on CIRR, Fashion-IQ, and CIRCO show that SETR achieves new state-of-the-art performance, improving Recall@1 on CIRR by up to 15.15 points. Our results establish two-stage reasoning as a general paradigm for robust and portable ZS-CIR.