Learning Egocentric In-Hand Object Segmentation through Weak Supervision from Human Narrations
作者: Nicola Messina, Rosario Leonardi, Luca Ciampi, Fabio Carrara, Giovanni Maria Farinella, Fabrizio Falchi, Antonino Furnari
分类: cs.CV, cs.AI
发布日期: 2025-09-30 (更新: 2025-12-02)
备注: Under consideration at Pattern Recognition Letters
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于人类叙述弱监督的单目手持物体分割方法NS-iHOS
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱五:交互与反应 (Interaction & Reaction) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 手持物体分割 弱监督学习 人类叙述 第一人称视角 视觉语言模型
📋 核心要点
- 现有手持物体分割方法依赖大量人工标注数据,成本高昂,限制了该领域发展。
- 利用人类叙述中关于操作物体的线索,以弱监督方式学习手持物体分割,无需测试时使用叙述。
- 提出的WISH模型在EPIC-Kitchens和Ego4D数据集上优于现有基线,性能接近全监督方法。
📝 摘要(中文)
本文提出了一种新的任务:基于叙述监督的手持物体分割(NS-iHOS),旨在利用自然语言叙述(即相机佩戴者执行动作时对所操作物体的描述)学习分割手持物体。由于现有方法依赖于昂贵的手动标注,该领域的发展受到数据集稀缺的限制。为此,本文提出WISH模型,该模型从叙述中提取知识,学习合理的手-物体关联,从而实现手持物体的分割,且在测试时不使用叙述。在EPIC-Kitchens和Ego4D数据集上的实验表明,WISH超越了所有基于开放词汇物体检测器和视觉-语言模型的基线方法,在不使用精细像素级标注的情况下,恢复了超过50%的全监督方法性能。
🔬 方法详解
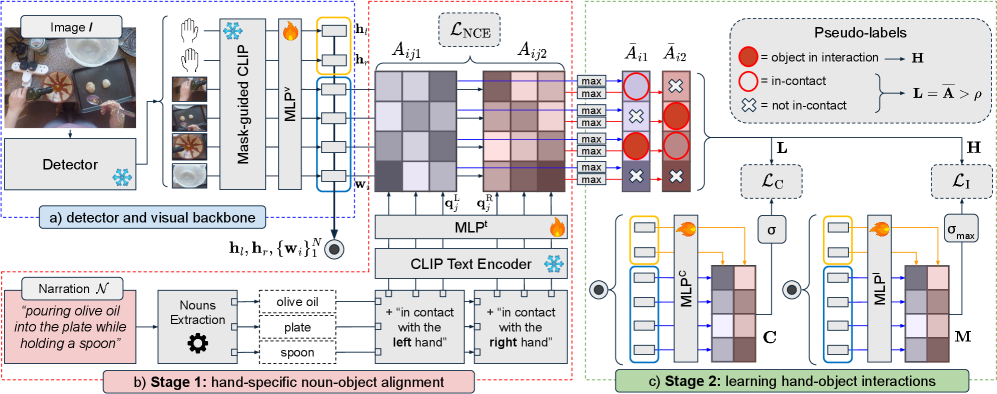
问题定义:论文旨在解决从第一人称视角图像中分割用户手持物体的问题。现有方法主要依赖于大量人工标注的像素级数据,标注成本高昂,限制了模型在实际场景中的应用和泛化能力。因此,如何利用弱监督信息,减少对人工标注的依赖,是该研究要解决的核心问题。
核心思路:论文的核心思路是利用人类对自身行为的自然语言描述(即叙述)作为弱监督信号,来指导模型学习手持物体的分割。叙述中包含了关于手和物体之间交互的信息,模型可以通过学习这些信息来推断图像中手持物体的位置和形状。在训练阶段使用叙述,而在推理阶段则不需要,从而保证了模型的实用性。
技术框架:整体框架包含以下几个主要模块:1) 视觉特征提取模块,用于提取第一人称视角图像的视觉特征;2) 语言特征提取模块,用于提取人类叙述的语言特征;3) 多模态融合模块,将视觉特征和语言特征进行融合,学习手-物体之间的关联;4) 分割模块,根据融合后的特征,预测图像中手持物体的像素级分割结果。整个框架采用端到端的方式进行训练。
关键创新:最重要的技术创新点在于利用人类叙述作为弱监督信号,来学习手持物体的分割。与传统的监督学习方法相比,该方法大大减少了对人工标注数据的需求。此外,该方法还提出了一种新的任务:基于叙述监督的手持物体分割(NS-iHOS),为该领域的研究提供了一个新的方向。
关键设计:论文中WISH模型利用预训练的视觉和语言模型提取特征,例如使用ResNet提取图像特征,使用BERT提取文本特征。多模态融合模块可能使用了注意力机制或者其他融合策略,以更好地学习视觉和语言之间的关联。损失函数的设计可能包括分割损失(例如交叉熵损失)以及一些正则化项,以保证模型的泛化能力。具体的网络结构和参数设置在论文中应该有详细描述,但摘要中未提及。
🖼️ 关键图片


📊 实验亮点
WISH模型在EPIC-Kitchens和Ego4D数据集上进行了评估,实验结果表明,WISH模型在不使用像素级标注的情况下,性能优于基于开放词汇物体检测器和视觉-语言模型的基线方法,并且恢复了超过50%的全监督方法性能。这表明利用人类叙述作为弱监督信号,可以有效地学习手持物体的分割。
🎯 应用场景
该研究成果可应用于辅助技术、工业安全和活动监控等领域。例如,可以帮助视力障碍者识别手持物体,提高生活质量;在工业环境中,可以监测工人是否正确操作工具,保障生产安全;在活动监控中,可以识别用户正在进行的活动,提供个性化服务。未来,该技术有望与机器人技术结合,实现更智能的人机交互。
📄 摘要(原文)
Pixel-level recognition of objects manipulated by the user from egocentric images enables key applications spanning assistive technologies, industrial safety, and activity monitoring. However, progress in this area is currently hindered by the scarcity of annotated datasets, as existing approaches rely on costly manual labels. In this paper, we propose to learn human-object interaction detection leveraging narrations $\unicode{x2013}$ natural language descriptions of the actions performed by the camera wearer which contain clues about manipulated objects. We introduce Narration-Supervised in-Hand Object Segmentation (NS-iHOS), a novel task where models have to learn to segment in-hand objects by learning from natural-language narrations in a weakly-supervised regime. Narrations are then not employed at inference time. We showcase the potential of the task by proposing Weakly-Supervised In-hand Object Segmentation from Human Narrations (WISH), an end-to-end model distilling knowledge from narrations to learn plausible hand-object associations and enable in-hand object segmentation without using narrations at test time. We benchmark WISH against different baselines based on open-vocabulary object detectors and vision-language models. Experiments on EPIC-Kitchens and Ego4D show that WISH surpasses all baselines, recovering more than 50% of the performance of fully supervised methods, without employing fine-grained pixel-wise annotations. Code and data can be found at https://fpv-iplab.github.io/WISH.