Self-Supervised Anatomical Consistency Learning for Vision-Grounded Medical Report Generation
作者: Longzhen Yang, Zhangkai Ni, Ying Wen, Yihang Liu, Lianghua He, Heng Tao Shen
分类: cs.CV
发布日期: 2025-09-30
💡 一句话要点
提出自监督解剖一致性学习框架,用于视觉引导的医学报告生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学报告生成 自监督学习 解剖一致性学习 视觉定位 医学影像 对比学习 Transformer
📋 核心要点
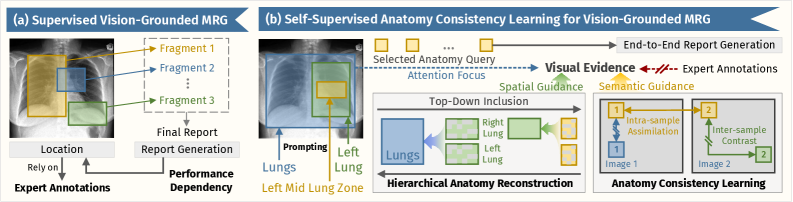
- 现有医学报告生成方法依赖大量专家标注的检测模块,成本高且泛化性受限。
- 提出自监督解剖一致性学习框架,利用文本提示对齐报告与解剖区域,无需标注。
- 实验表明,该方法在词汇准确率和临床有效性上显著优于现有方法,并在视觉任务上表现出色。
📝 摘要(中文)
本文提出了一种自监督解剖一致性学习(SS-ACL)框架,用于视觉引导的医学报告生成,旨在生成临床上准确的医学图像描述,并锚定于明确的视觉证据,以提高可解释性并促进集成到临床工作流程中。现有方法通常依赖于单独训练的检测模块,需要大量的专家标注,导致标注成本高昂,并因数据集之间的病理分布偏差而限制了泛化能力。SS-ACL利用简单的文本提示将生成的报告与相应的解剖区域对齐,无需专家标注。该方法构建了一个受人类解剖结构不变的自上而下包含结构启发的层次解剖图,按空间位置组织实体,并递归地重建细粒度的解剖区域,以加强样本内空间对齐,从而引导注意力图关注文本提示的视觉相关区域。为了进一步增强用于异常识别的样本间语义对齐,SS-ACL引入了基于解剖一致性的区域级对比学习。这些对齐的嵌入作为报告生成的先验,使注意力图能够提供可解释的视觉证据。大量实验表明,SS-ACL在不依赖专家标注的情况下,(i)生成准确且视觉基础良好的报告——在词汇准确率方面优于最先进的方法10%,在临床有效性方面优于25%,并且(ii)在各种下游视觉任务上实现了具有竞争力的性能,在零样本视觉定位方面超过了当前领先的视觉基础模型8%。
🔬 方法详解
问题定义:现有视觉引导的医学报告生成方法依赖于预训练的检测模块,这些模块需要大量的专家标注,导致标注成本高昂,并且由于不同数据集之间的病理分布存在偏差,模型的泛化能力受到限制。因此,如何在无需大量人工标注的情况下,生成准确且具有临床意义的医学报告是一个关键问题。
核心思路:本文的核心思路是利用自监督学习的方式,通过解剖一致性学习,将生成的报告与医学图像中的解剖区域对齐。通过构建层次化的解剖图,并利用文本提示引导模型关注相关的视觉区域,从而实现无需人工标注的报告生成。这种方法能够提高模型的可解释性,并减少对大量标注数据的依赖。
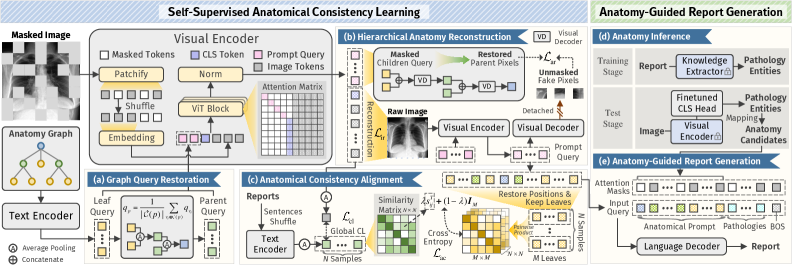
技术框架:SS-ACL框架主要包含以下几个模块:1) 层次解剖图构建:构建一个层次化的解剖图,该图反映了解剖结构之间的空间关系。2) 递归区域重建:递归地重建细粒度的解剖区域,以强制执行样本内的空间对齐。3) 区域级对比学习:引入基于解剖一致性的区域级对比学习,以增强样本间的语义对齐。4) 报告生成:利用对齐的嵌入作为先验知识,生成医学报告。
关键创新:该方法最重要的创新点在于提出了自监督的解剖一致性学习框架,该框架无需人工标注,即可将生成的报告与医学图像中的解剖区域对齐。通过构建层次化的解剖图和利用文本提示,模型能够自动学习解剖结构之间的关系,并生成准确且具有临床意义的报告。此外,区域级对比学习进一步增强了模型对异常的识别能力。
关键设计:在层次解剖图构建中,使用了基于人类解剖结构不变的自上而下包含结构。在区域级对比学习中,使用了InfoNCE损失函数来最大化正样本之间的相似性,并最小化负样本之间的相似性。报告生成模块使用了Transformer架构,并将对齐的嵌入作为先验知识输入到解码器中。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SS-ACL在词汇准确率方面优于最先进的方法10%,在临床有效性方面优于25%。在零样本视觉定位任务中,SS-ACL超过了当前领先的视觉基础模型8%。这些结果表明,该方法在医学报告生成和视觉定位方面具有显著的优势。
🎯 应用场景
该研究成果可应用于辅助医生进行医学影像诊断,提高诊断效率和准确性。通过生成可解释的医学报告,有助于医生理解模型的决策过程,增强信任度。此外,该技术还可用于医学教育和培训,帮助学生学习和理解医学影像。
📄 摘要(原文)
Vision-grounded medical report generation aims to produce clinically accurate descriptions of medical images, anchored in explicit visual evidence to improve interpretability and facilitate integration into clinical workflows. However, existing methods often rely on separately trained detection modules that require extensive expert annotations, introducing high labeling costs and limiting generalizability due to pathology distribution bias across datasets. To address these challenges, we propose Self-Supervised Anatomical Consistency Learning (SS-ACL) -- a novel and annotation-free framework that aligns generated reports with corresponding anatomical regions using simple textual prompts. SS-ACL constructs a hierarchical anatomical graph inspired by the invariant top-down inclusion structure of human anatomy, organizing entities by spatial location. It recursively reconstructs fine-grained anatomical regions to enforce intra-sample spatial alignment, inherently guiding attention maps toward visually relevant areas prompted by text. To further enhance inter-sample semantic alignment for abnormality recognition, SS-ACL introduces a region-level contrastive learning based on anatomical consistency. These aligned embeddings serve as priors for report generation, enabling attention maps to provide interpretable visual evidence. Extensive experiments demonstrate that SS-ACL, without relying on expert annotations, (i) generates accurate and visually grounded reports -- outperforming state-of-the-art methods by 10\% in lexical accuracy and 25\% in clinical efficacy, and (ii) achieves competitive performance on various downstream visual tasks, surpassing current leading visual foundation models by 8\% in zero-shot visual grounding.