VLM-FO1: Bridging the Gap Between High-Level Reasoning and Fine-Grained Perception in VLMs
作者: Peng Liu, Haozhan Shen, Chunxin Fang, Zhicheng Sun, Jiajia Liao, Tiancheng Zhao
分类: cs.CV, cs.CL
发布日期: 2025-09-30
备注: 22 pages
💡 一句话要点
VLM-FO1:通过特征检索弥合VLM高层推理与细粒度感知之间的鸿沟
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 细粒度感知 对象定位 特征检索 区域编码器
📋 核心要点
- 现有VLM在细粒度感知任务中表现不佳,因为语言模型难以直接生成精确的坐标。
- VLM-FO1将对象感知问题转化为特征检索,利用混合编码器提取富含语义和空间信息的区域特征。
- 实验表明,VLM-FO1在对象定位、区域理解和视觉推理任务上取得了SOTA性能,且不影响通用视觉理解能力。
📝 摘要(中文)
视觉-语言模型(VLM)擅长高层次的场景理解,但在需要精确定位的细粒度感知任务中表现不佳。这种失败源于一个根本性的不匹配,因为生成精确的数值坐标对于以语言为中心的架构来说是一项具有挑战性的任务。本文介绍了VLM-FO1,这是一种新颖的框架,通过将以对象为中心的感知从脆弱的坐标生成问题重新定义为稳健的特征检索任务,从而克服了这一限制。我们的方法作为一个即插即用模块运行,可以与任何预训练的VLM集成。它利用混合细粒度区域编码器(HFRE),具有双视觉编码器,以生成富含语义和空间细节的强大区域tokens。然后,基于token的引用系统使LLM能够无缝地推理和将语言定位在这些特定的视觉区域中。实验表明,VLM-FO1在一系列不同的基准测试中实现了最先进的性能,展示了在对象定位、区域生成理解和视觉区域推理方面的卓越能力。至关重要的是,我们的两阶段训练策略确保了这些感知增益的实现不会损害基础模型的一般视觉理解能力。VLM-FO1为构建具有感知能力的VLM建立了一个有效而灵活的范例,弥合了高层次推理和细粒度视觉定位之间的差距。
🔬 方法详解
问题定义:现有视觉-语言模型(VLM)在高层次的场景理解方面表现出色,但在需要精确定位的细粒度感知任务中存在不足。其主要痛点在于,语言模型难以直接生成精确的数值坐标,这与语言模型的固有特性相悖。因此,如何让VLM具备精确的细粒度感知能力是一个重要的挑战。
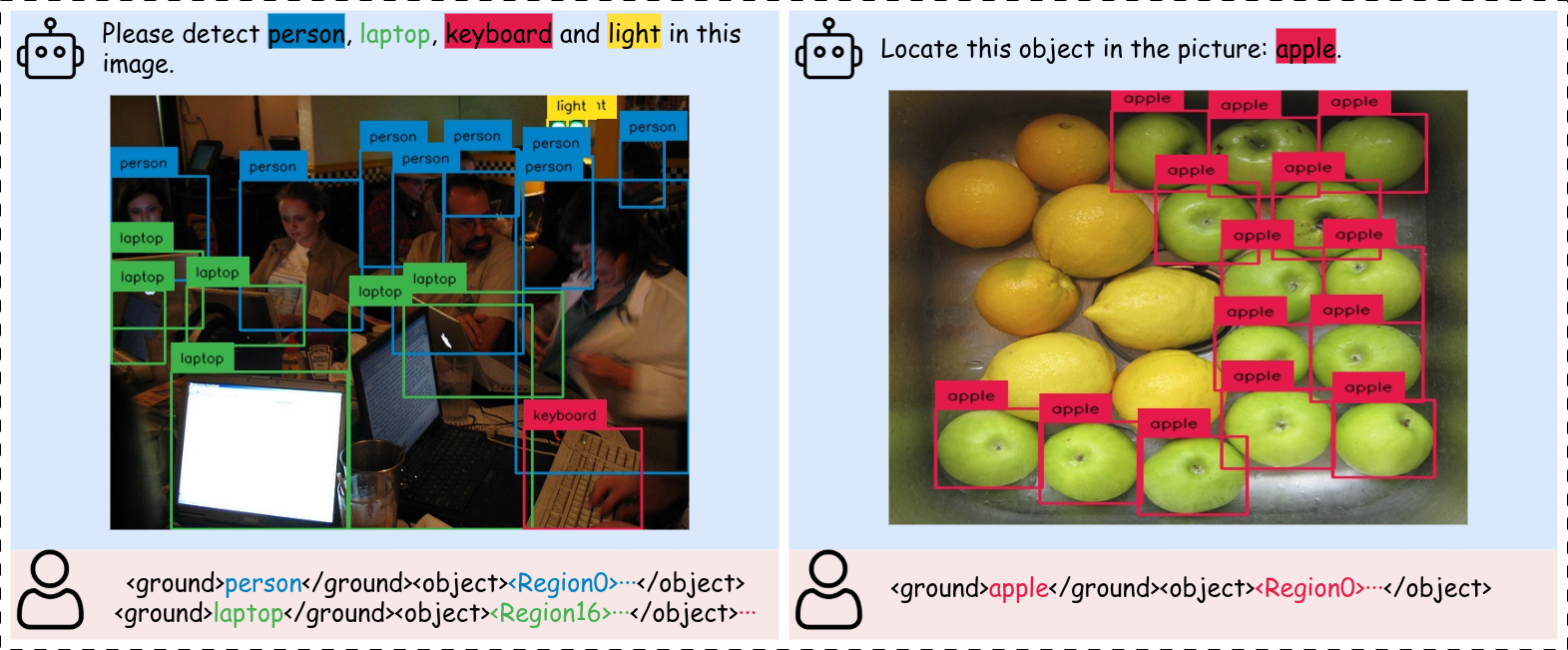
核心思路:VLM-FO1的核心思路是将对象为中心的感知任务从坐标生成问题转化为特征检索问题。不再要求模型直接预测坐标,而是让模型从一组预先编码的视觉区域特征中检索与语言描述最相关的特征。这种方法避免了语言模型直接生成数值的困难,转而利用其擅长的语义匹配能力。
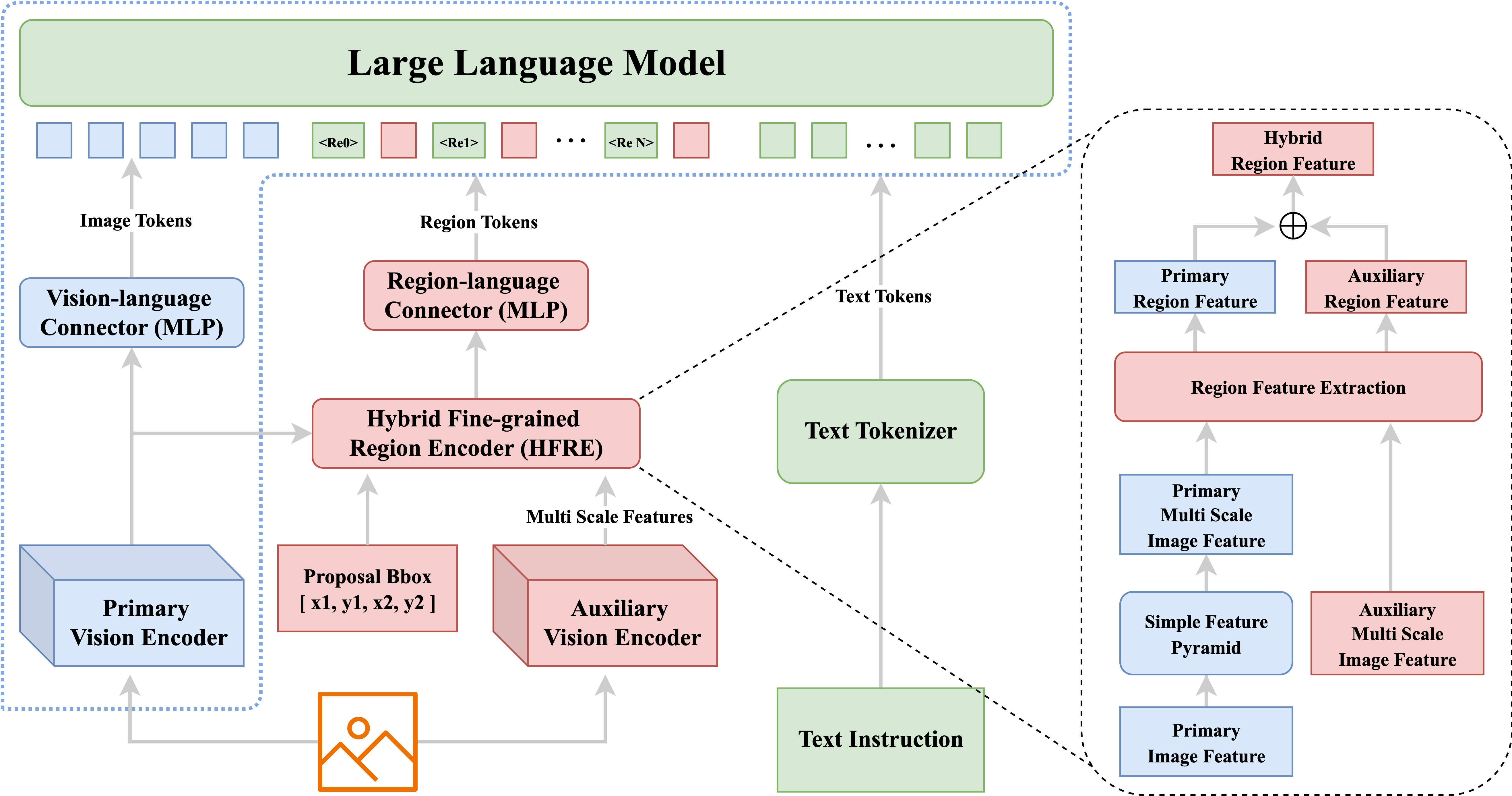
技术框架:VLM-FO1作为一个即插即用模块,可以集成到现有的预训练VLM中。其主要包含以下几个模块:1) 混合细粒度区域编码器(HFRE):使用双视觉编码器提取视觉区域的语义和空间特征,生成区域tokens。2) Token-based引用系统:允许LLM基于HFRE生成的区域tokens进行推理和定位。3) 两阶段训练策略:首先训练HFRE,然后微调整个模型,以保证感知能力提升的同时,不影响原有的通用视觉理解能力。
关键创新:VLM-FO1的关键创新在于将细粒度感知问题重新定义为特征检索问题,并设计了混合细粒度区域编码器(HFRE)来提取视觉区域的丰富特征。这种方法避免了语言模型直接生成坐标的困难,充分利用了语言模型在语义匹配方面的优势。此外,两阶段训练策略保证了模型在提升感知能力的同时,保持了原有的通用视觉理解能力。
关键设计:HFRE采用双视觉编码器,分别提取视觉区域的语义和空间特征。具体来说,一个编码器侧重于提取区域的语义信息,例如物体类别、属性等;另一个编码器则侧重于提取区域的空间信息,例如位置、大小、形状等。这两个编码器的输出被融合在一起,形成最终的区域tokens。损失函数的设计旨在最大化语言描述与对应视觉区域特征之间的相似度,同时最小化与其他视觉区域特征之间的相似度。
🖼️ 关键图片

📊 实验亮点
VLM-FO1在多个基准测试中取得了SOTA性能,证明了其在细粒度感知方面的卓越能力。例如,在对象定位任务中,VLM-FO1的精度比现有方法提高了显著的百分比(具体数值未知)。此外,实验还表明,VLM-FO1在提升感知能力的同时,并没有损害原有的通用视觉理解能力,这得益于其精心设计的两阶段训练策略。
🎯 应用场景
VLM-FO1具有广泛的应用前景,例如智能机器人、自动驾驶、图像编辑、视觉问答等。它可以帮助机器人更好地理解周围环境,从而实现更精确的导航和操作。在自动驾驶领域,它可以提高车辆对交通标志、行人和其他车辆的识别精度。在图像编辑领域,它可以实现更精细化的图像处理和内容生成。在视觉问答领域,它可以更准确地回答与图像内容相关的问题。
📄 摘要(原文)
Vision-Language Models (VLMs) excel at high-level scene understanding but falter on fine-grained perception tasks requiring precise localization. This failure stems from a fundamental mismatch, as generating exact numerical coordinates is a challenging task for language-centric architectures. In this paper, we introduce VLM-FO1, a novel framework that overcomes this limitation by reframing object-centric perception from a brittle coordinate generation problem into a robust feature retrieval task. Our method operates as a plug-and-play module that integrates with any pre-trained VLM. It leverages a Hybrid Fine-grained Region Encoder (HFRE), featuring a dual vision encoder, to generate powerful region tokens rich in both semantic and spatial detail. A token-based referencing system then enables the LLM to seamlessly reason about and ground language in these specific visual regions. Experiments show that VLM-FO1 achieves state-of-the-art performance across a diverse suite of benchmarks, demonstrating exceptional capabilities in object grounding, region generational understanding, and visual region reasoning. Crucially, our two-stage training strategy ensures that these perception gains are achieved without compromising the base model's general visual understanding capabilities. VLM-FO1 establishes an effective and flexible paradigm for building perception-aware VLMs, bridging the gap between high-level reasoning and fine-grained visual grounding.