A Multimodal LLM Approach for Visual Question Answering on Multiparametric 3D Brain MRI
作者: Arvind Murari Vepa, Yannan Yu, Jingru Gan, Anthony Cuturrufo, Weikai Li, Wei Wang, Fabien Scalzo, Yizhou Sun
分类: cs.CV, cs.CL
发布日期: 2025-09-30 (更新: 2025-10-01)
备注: 23 pages, 3 figures
💡 一句话要点
提出mpLLM,用于多参数3D脑部MRI的视觉问答任务,并构建了临床验证数据集。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉问答 医学影像 混合专家模型 3D脑部MRI 大型语言模型 合成数据增强
📋 核心要点
- 现有医学图像VQA方法缺乏对多参数3D脑部MRI的有效处理,且训练数据不足。
- mpLLM利用提示条件分层混合专家架构,融合多模态3D MRI数据,并采用合成VQA数据增强训练。
- 实验表明,mpLLM在多个mpMRI数据集上优于现有医学VLM基线,平均提升5.3%。
📝 摘要(中文)
本文提出了一种名为mpLLM的提示条件分层混合专家(MoE)架构,用于多参数3D脑部MRI(mpMRI)的视觉问答。mpLLM通过模态级别和token级别的投影专家进行路由,融合多个相互关联的3D模态,从而实现高效训练,无需图像-报告预训练。为了解决有限的图像-文本配对监督问题,mpLLM集成了一种合成视觉问答(VQA)协议,该协议从分割注释生成医学相关的VQA,并与医学专家合作进行临床验证。在多个mpMRI数据集上,mpLLM的性能平均优于强大的医学VLM基线5.3%。本研究的主要贡献包括:(1)首个经过临床验证的3D脑部mpMRI的VQA数据集,(2)一种处理多个相互关联的3D模态的新型多模态LLM,以及(3)强大的实证结果,证明了该方法的医学实用性。消融实验突出了模态级别和token级别专家以及提示条件路由的重要性。
🔬 方法详解
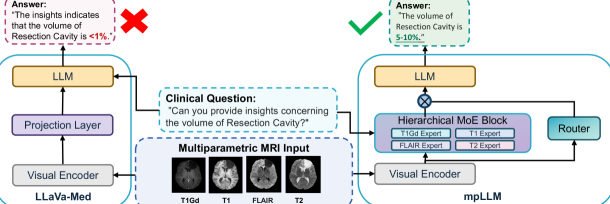
问题定义:论文旨在解决多参数3D脑部MRI图像的视觉问答(VQA)问题。现有方法难以有效融合多种模态的3D MRI数据,并且缺乏足够的图像-文本配对数据进行训练,限制了其在临床上的应用。
核心思路:论文的核心思路是利用一个多模态大型语言模型(LLM),通过混合专家(MoE)架构,学习不同模态和token之间的关系,从而实现对多参数3D MRI数据的有效融合和理解。同时,利用合成数据增强技术,缓解数据不足的问题。
技术框架:mpLLM的整体架构是一个提示条件的分层混合专家(MoE)模型。它包含以下主要模块:(1) 多模态输入编码器,用于提取不同模态MRI数据的特征;(2) 模态级别专家,用于学习不同模态之间的关系;(3) Token级别专家,用于学习图像token之间的关系;(4) LLM解码器,用于生成答案。整个流程是,首先将多模态MRI数据输入编码器,然后通过模态级别和token级别的专家进行特征融合,最后由LLM解码器生成答案。
关键创新:论文的关键创新点在于提出了一个专门针对多参数3D MRI数据的多模态LLM架构,该架构能够有效地融合多种模态的信息,并利用混合专家机制提高模型的表达能力和训练效率。此外,论文还提出了一个合成VQA数据生成方法,缓解了医学图像数据不足的问题。
关键设计:mpLLM的关键设计包括:(1) 使用混合专家(MoE)架构,提高模型的容量和表达能力;(2) 采用提示条件路由,根据输入问题动态选择合适的专家;(3) 设计合成VQA数据生成方法,利用分割注释生成医学相关的VQA数据;(4) 与医学专家合作进行临床验证,确保模型的实用性。
🖼️ 关键图片


📊 实验亮点
mpLLM在多个mpMRI数据集上取得了显著的性能提升,平均优于现有医学VLM基线5.3%。消融实验表明,模态级别和token级别专家以及提示条件路由对模型性能至关重要。此外,该研究还构建了首个经过临床验证的3D脑部mpMRI的VQA数据集。
🎯 应用场景
该研究成果可应用于辅助医生进行脑部疾病的诊断和治疗。通过对多参数MRI图像进行视觉问答,可以帮助医生快速获取关键信息,提高诊断效率和准确性。未来,该技术有望扩展到其他医学影像领域,为临床决策提供更全面的支持。
📄 摘要(原文)
We introduce mpLLM, a prompt-conditioned hierarchical mixture-of-experts (MoE) architecture for visual question answering over multi-parametric 3D brain MRI (mpMRI). mpLLM routes across modality-level and token-level projection experts to fuse multiple interrelated 3D modalities, enabling efficient training without image-report pretraining. To address limited image-text paired supervision, mpLLM integrates a synthetic visual question answering (VQA) protocol that generates medically relevant VQA from segmentation annotations, and we collaborate with medical experts for clinical validation. mpLLM outperforms strong medical VLM baselines by 5.3% on average across multiple mpMRI datasets. Our study features three main contributions: (1) the first clinically validated VQA dataset for 3D brain mpMRI, (2) a novel multimodal LLM that handles multiple interrelated 3D modalities, and (3) strong empirical results that demonstrate the medical utility of our methodology. Ablations highlight the importance of modality-level and token-level experts and prompt-conditioned routing.