DeepSketcher: Internalizing Visual Manipulation for Multimodal Reasoning
作者: Chi Zhang, Haibo Qiu, Qiming Zhang, Zhixiong Zeng, Lin Ma, Jing Zhang
分类: cs.CV
发布日期: 2025-09-30
💡 一句话要点
DeepSketcher:通过内部视觉操作实现多模态推理
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推理 视觉语言模型 图像思考 视觉嵌入空间 思维链 图像-文本交错 视觉操作
📋 核心要点
- 现有视觉语言模型在多模态推理中依赖文本主导的思维链,缺乏对图像的深入理解和交互。
- DeepSketcher通过在视觉嵌入空间中直接操作,原生生成“视觉思想”,无需外部工具和重复编码。
- 实验表明,DeepSketcher在多模态推理基准上表现出色,验证了数据集的有效性和模型设计的优越性。
📝 摘要(中文)
“图像思考”范式代表了视觉语言模型(VLM)推理的一个关键转变,它从以文本为主的思维链转向图像交互推理。通过调用视觉工具或生成中间视觉表示,VLM可以迭代地关注细粒度区域,从而实现更深入的图像理解和更真实的多模态推理。然而,作为一个新兴的范式,它在数据构建准确性、结构设计和更广泛的应用场景方面仍有很大的探索空间,这为推进多模态推理提供了丰富的机会。为了进一步推进这项工作,我们提出了DeepSketcher,这是一个综合套件,包括一个图像-文本交错数据集和一个独立的模型。该数据集包含31k个思维链(CoT)推理轨迹,具有不同的工具调用和生成的编辑图像,涵盖了各种数据类型和具有高注释准确性的操作指令。在此基础上,我们设计了一个模型,该模型执行交错的图像-文本推理,并通过直接在视觉嵌入空间中操作来原生生成“视觉思想”,而不是调用外部工具并重复重新编码生成的图像。这种设计实现了免工具和更灵活的“图像思考”。在多模态推理基准上的大量实验证明了强大的性能,验证了数据集的效用和模型设计的有效性。
🔬 方法详解
问题定义:现有视觉语言模型在进行多模态推理时,主要依赖于文本信息,对图像的理解不够深入,并且需要频繁调用外部视觉工具,导致效率低下。现有方法的痛点在于无法有效地利用图像本身的信息进行推理,并且依赖外部工具增加了计算负担和复杂性。
核心思路:DeepSketcher的核心思路是通过在视觉嵌入空间中直接进行操作,生成中间的“视觉思想”,从而实现更高效和深入的图像理解。这种方法避免了对外部工具的依赖,并且能够更好地利用图像的内在信息进行推理。
技术框架:DeepSketcher包含一个图像-文本交错数据集和一个自包含的模型。数据集用于训练模型进行思维链推理,模型则负责执行交错的图像-文本推理,并在视觉嵌入空间中生成“视觉思想”。整体流程包括:输入图像和文本描述,模型在视觉嵌入空间中进行操作生成中间视觉表示,然后结合文本信息进行推理,最终输出结果。
关键创新:DeepSketcher最重要的技术创新点在于它能够在视觉嵌入空间中直接进行操作,生成“视觉思想”,而无需依赖外部视觉工具。这与现有方法形成了本质区别,现有方法通常需要调用外部工具并重复重新编码生成的图像。
关键设计:论文中没有明确给出关键的参数设置、损失函数、网络结构等技术细节,这部分信息未知。但可以推测,视觉嵌入空间的构建和操作方式,以及如何将视觉“思想”与文本信息有效融合,是关键的设计考量。
🖼️ 关键图片
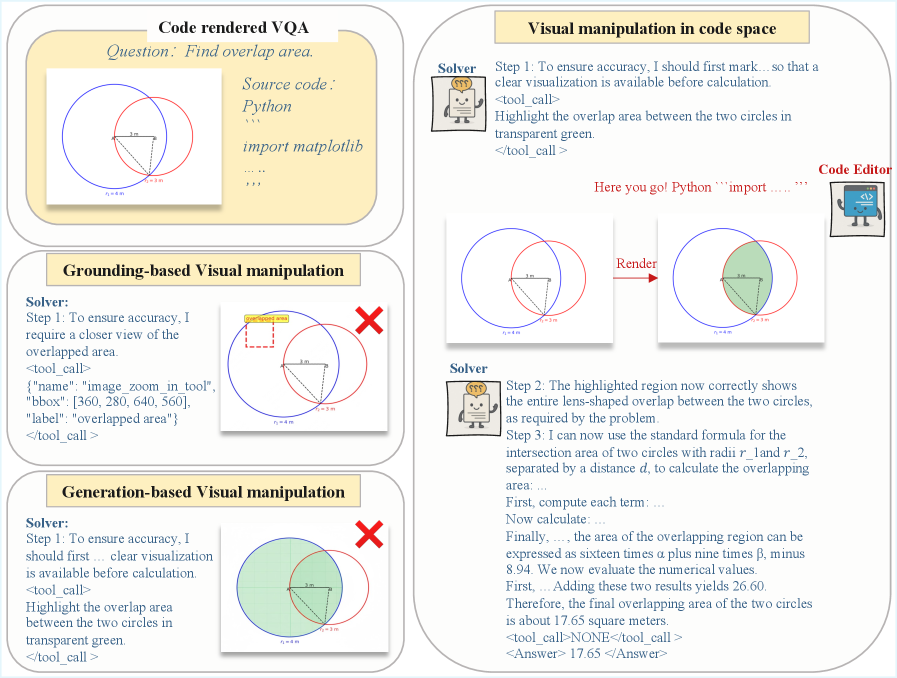

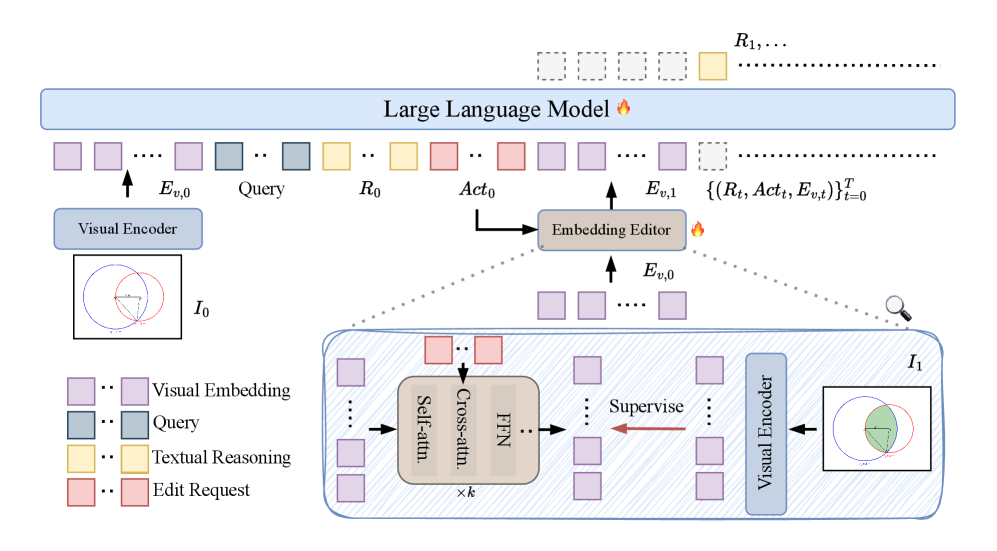
📊 实验亮点
DeepSketcher在多模态推理基准上表现出强大的性能,验证了数据集的效用和模型设计的有效性。虽然论文中没有给出具体的性能数据和对比基线,但强调了该模型在免工具和更灵活的“图像思考”方面的优势。
🎯 应用场景
DeepSketcher具有广泛的应用前景,例如智能图像编辑、视觉问答、机器人导航和人机交互等领域。通过赋予机器更强的图像理解和推理能力,可以实现更智能化的应用,例如自动生成图像描述、辅助诊断医学影像、以及在复杂环境中进行自主导航。
📄 摘要(原文)
The "thinking with images" paradigm represents a pivotal shift in the reasoning of Vision Language Models (VLMs), moving from text-dominant chain-of-thought to image-interactive reasoning. By invoking visual tools or generating intermediate visual representations, VLMs can iteratively attend to fine-grained regions, enabling deeper image understanding and more faithful multimodal reasoning. As an emerging paradigm, however, it still leaves substantial room for exploration in data construction accuracy, structural design, and broader application scenarios, which offer rich opportunities for advancing multimodal reasoning. To further advance this line of work, we present DeepSketcher, a comprehensive suite comprising both an image-text interleaved dataset and a self-contained model. The dataset contains 31k chain-of-thought (CoT) reasoning trajectories with diverse tool calls and resulting edited images, covering a wide range of data types and manipulation instructions with high annotation accuracy. Building on this resource, we design a model that performs interleaved image-text reasoning and natively generates "visual thoughts" by operating directly in the visual embedding space, rather than invoking external tools and repeatedly re-encoding generated images. This design enables tool-free and more flexible "thinking with images". Extensive experiments on multimodal reasoning benchmarks demonstrate strong performance, validating both the utility of the dataset and the effectiveness of the model design.