LMOD+: A Comprehensive Multimodal Dataset and Benchmark for Developing and Evaluating Multimodal Large Language Models in Ophthalmology
作者: Zhenyue Qin, Yang Liu, Yu Yin, Jinyu Ding, Haoran Zhang, Anran Li, Dylan Campbell, Xuansheng Wu, Ke Zou, Tiarnan D. L. Keenan, Emily Y. Chew, Zhiyong Lu, Yih-Chung Tham, Ninghao Liu, Xiuzhen Zhang, Qingyu Chen
分类: cs.CV
发布日期: 2025-09-30
💡 一句话要点
提出LMOD+以解决眼科多模态大语言模型评估问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 眼科疾病 大语言模型 数据集构建 模型评估
📋 核心要点
- 现有方法在眼科领域缺乏全面的基准数据集,限制了多模态大语言模型的评估和应用。
- 本文提出了LMOD+数据集,扩展了数据规模并增加了任务覆盖,包括疾病诊断和人口统计预测。
- 实验结果显示,最佳模型在疾病筛查中取得了约58%的准确率,但在疾病分期等复杂任务中表现仍不理想。
📝 摘要(中文)
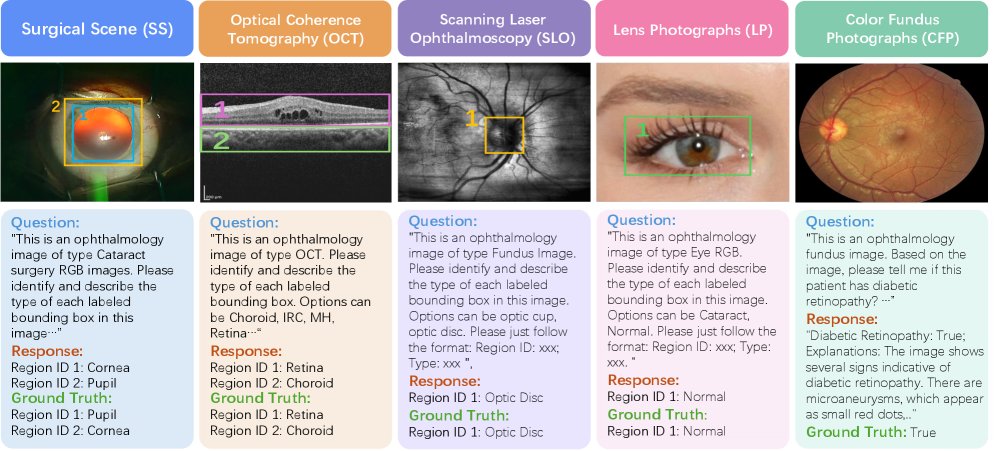
眼科疾病的及时诊断受到人力资源短缺和专业护理获取限制的影响。尽管多模态大语言模型(MLLMs)在医学图像解读中展现出潜力,但缺乏全面的基准数据集限制了其在眼科的进展。本文提出了一个大规模的多模态眼科基准数据集,包含32,633个实例,涵盖12种常见眼科疾病和5种成像模式,集成了成像、解剖结构、人口统计信息和自由文本注释,支持解剖结构识别、疾病筛查、疾病分期和人口统计预测。我们对24种最先进的MLLMs进行了系统评估,结果显示在零样本设置下,最佳模型在疾病筛查中的准确率约为58%。
🔬 方法详解
问题定义:本文旨在解决眼科领域缺乏全面基准数据集的问题,现有方法在评估多模态大语言模型时存在局限性,尤其是在疾病筛查和分期方面。
核心思路:通过构建一个包含32,633个实例的大规模多模态数据集,集成多种成像模式和注释类型,来支持眼科疾病的多维度评估。这样的设计旨在提升模型的泛化能力和评估的全面性。
技术框架:整体架构包括数据收集、标注、模型训练和评估四个主要阶段。数据收集涵盖多种成像模式,标注则涉及解剖结构和疾病状态的多层次注释。模型训练使用多模态学习技术,评估则通过与24种最先进的MLLMs进行对比。
关键创新:最重要的创新在于数据集的规模和多样性,几乎扩展了50%的数据量,并增加了任务的覆盖范围,包括国际分级标准的疾病严重性分类。
关键设计:在数据集构建中,采用了多种成像技术和详细的注释标准,确保数据的高质量和多样性。同时,评估过程中使用了标准化的性能指标,以便于不同模型之间的比较。
🖼️ 关键图片

📊 实验亮点
实验结果显示,最佳模型在零样本设置下的疾病筛查准确率达到了约58%。尽管在一些复杂任务(如疾病分期)中表现不佳,但整体评估揭示了当前多模态大语言模型在眼科应用中的潜力和局限性。
🎯 应用场景
该研究的潜在应用领域包括眼科疾病的早期筛查和诊断,能够帮助医生更快地识别和处理视力威胁性疾病。通过提供公开的数据集和评估基准,未来可能推动眼科人工智能应用的发展,从而减轻全球眼科疾病的负担。
📄 摘要(原文)
Vision-threatening eye diseases pose a major global health burden, with timely diagnosis limited by workforce shortages and restricted access to specialized care. While multimodal large language models (MLLMs) show promise for medical image interpretation, advancing MLLMs for ophthalmology is hindered by the lack of comprehensive benchmark datasets suitable for evaluating generative models. We present a large-scale multimodal ophthalmology benchmark comprising 32,633 instances with multi-granular annotations across 12 common ophthalmic conditions and 5 imaging modalities. The dataset integrates imaging, anatomical structures, demographics, and free-text annotations, supporting anatomical structure recognition, disease screening, disease staging, and demographic prediction for bias evaluation. This work extends our preliminary LMOD benchmark with three major enhancements: (1) nearly 50% dataset expansion with substantial enlargement of color fundus photography; (2) broadened task coverage including binary disease diagnosis, multi-class diagnosis, severity classification with international grading standards, and demographic prediction; and (3) systematic evaluation of 24 state-of-the-art MLLMs. Our evaluations reveal both promise and limitations. Top-performing models achieved ~58% accuracy in disease screening under zero-shot settings, and performance remained suboptimal for challenging tasks like disease staging. We will publicly release the dataset, curation pipeline, and leaderboard to potentially advance ophthalmic AI applications and reduce the global burden of vision-threatening diseases.