OIG-Bench: A Multi-Agent Annotated Benchmark for Multimodal One-Image Guides Understanding
作者: Jiancong Xie, Wenjin Wang, Zhuomeng Zhang, Zihan Liu, Qi Liu, Ke Feng, Zixun Sun, Yuedong Yang
分类: cs.CV
发布日期: 2025-09-29
🔗 代码/项目: GITHUB
💡 一句话要点
OIG-Bench:提出多智能体标注的多模态单图指南理解评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 单图指南理解 评测基准 多智能体标注 半自动标注 视觉文本关系 语义理解 逻辑推理
📋 核心要点
- 现有MLLM在单图指南理解方面能力评估不足,单图指南蕴含人类感知和理解特性。
- 提出半自动标注流程,多智能体协作生成图像描述,辅助人工构建图像-文本对。
- OIG-Bench评测显示,Qwen2.5-VL-72B表现最佳,但模型在语义理解和逻辑推理方面仍有不足。
📝 摘要(中文)
本文提出OIG-Bench,一个综合性的评测基准,专注于多模态大语言模型(MLLMs)在单图指南理解方面的能力。单图指南是一种结合文本、图像和符号的视觉形式,旨在以重组和结构化的信息呈现方式,方便人类理解,体现了人类感知和理解的特性。为了降低手动标注的成本,本文开发了一种半自动标注流程,其中多个智能体协同生成初步的图像描述,辅助人工构建图像-文本对。利用OIG-Bench,对29个最先进的MLLMs(包括专有和开源模型)进行了全面评估。结果表明,Qwen2.5-VL-72B在评估模型中表现最佳,总体准确率达到77%。然而,所有模型在语义理解和逻辑推理方面都表现出明显的不足,表明当前的MLLMs在准确解释复杂的视觉-文本关系方面仍然存在困难。此外,本文还证明了所提出的多智能体标注系统在图像描述方面优于所有MLLMs,突显了其作为高质量图像描述生成器和未来数据集构建工具的潜力。数据集可在https://github.com/XiejcSYSU/OIG-Bench获取。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLMs)在理解单图指南方面的能力评估不足的问题。现有的评估方法可能无法充分捕捉单图指南中复杂的视觉-文本关系,以及人类感知和理解的特性。因此,需要一个专门的评测基准来更全面地评估MLLMs在这一领域的表现。
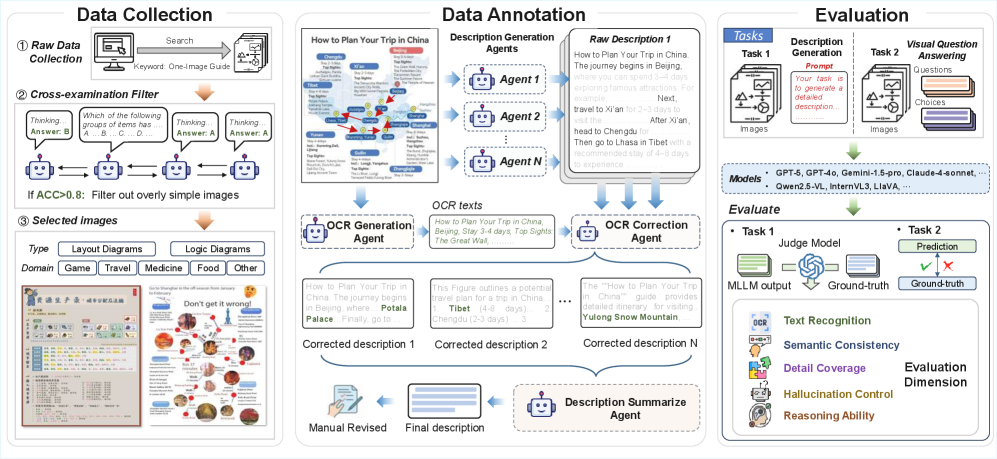
核心思路:论文的核心思路是构建一个高质量的、多样化的单图指南数据集,并设计相应的评估指标,以全面评估MLLMs的理解能力。为了降低人工标注成本,采用了多智能体协作的半自动标注流程,利用智能体生成初步的图像描述,辅助人工进行标注。
技术框架:OIG-Bench的构建主要包含以下几个阶段:1) 数据收集:收集来自不同领域的单图指南图像。2) 半自动标注:利用多个智能体生成图像描述,人工进行校对和完善,构建图像-文本对。3) 模型评估:使用构建好的数据集和评估指标,对MLLMs进行评估。4) 结果分析:分析评估结果,找出MLLMs在单图指南理解方面的优势和不足。
关键创新:论文的关键创新在于提出了一个多智能体协作的半自动标注流程,该流程能够有效地降低人工标注成本,并生成高质量的图像描述。此外,OIG-Bench数据集本身也是一个重要的贡献,它为研究人员提供了一个专门用于评估MLLMs在单图指南理解方面能力的评测基准。与现有方法相比,该方法更注重模拟人类的感知和理解方式。
关键设计:多智能体标注系统的具体实现细节未知,论文中没有详细描述智能体的选择、协作方式以及图像描述生成的具体算法。评估指标的选择也未详细说明,需要参考论文原文或补充材料。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Qwen2.5-VL-72B在OIG-Bench上表现最佳,总体准确率达到77%。然而,所有被评估的模型在语义理解和逻辑推理方面都存在明显的不足,表明当前的多模态大语言模型在准确理解复杂的视觉-文本关系方面仍有很大的提升空间。此外,多智能体标注系统在图像描述生成方面优于所有MLLMs。
🎯 应用场景
该研究成果可应用于提升多模态大语言模型在信息检索、教育、辅助设计等领域的应用能力。通过更准确地理解单图指南,模型可以更好地辅助用户理解复杂信息,例如在教学场景中解释图表,或在设计流程中理解设计规范。未来,该研究可以推动开发更智能、更人性化的多模态交互系统。
📄 摘要(原文)
Recent advances in Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities. However, evaluating their capacity for human-like understanding in One-Image Guides remains insufficiently explored. One-Image Guides are a visual format combining text, imagery, and symbols to present reorganized and structured information for easier comprehension, which are specifically designed for human viewing and inherently embody the characteristics of human perception and understanding. Here, we present OIG-Bench, a comprehensive benchmark focused on One-Image Guide understanding across diverse domains. To reduce the cost of manual annotation, we developed a semi-automated annotation pipeline in which multiple intelligent agents collaborate to generate preliminary image descriptions, assisting humans in constructing image-text pairs. With OIG-Bench, we have conducted a comprehensive evaluation of 29 state-of-the-art MLLMs, including both proprietary and open-source models. The results show that Qwen2.5-VL-72B performs the best among the evaluated models, with an overall accuracy of 77%. Nevertheless, all models exhibit notable weaknesses in semantic understanding and logical reasoning, indicating that current MLLMs still struggle to accurately interpret complex visual-text relationships. In addition, we also demonstrate that the proposed multi-agent annotation system outperforms all MLLMs in image captioning, highlighting its potential as both a high-quality image description generator and a valuable tool for future dataset construction. Datasets are available at https://github.com/XiejcSYSU/OIG-Bench.