LUMA: Low-Dimension Unified Motion Alignment with Dual-Path Anchoring for Text-to-Motion Diffusion Model
作者: Haozhe Jia, Wenshuo Chen, Yuqi Lin, Yang Yang, Lei Wang, Mang Ning, Bowen Tian, Songning Lai, Nanqian Jia, Yifan Chen, Yutao Yue
分类: cs.CV
发布日期: 2025-09-29
💡 一句话要点
LUMA:基于双路锚定的低维统一运动对齐文本到动作扩散模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 文本到动作生成 扩散模型 运动对齐 双路锚定 对比学习 时域锚定 频域锚定
📋 核心要点
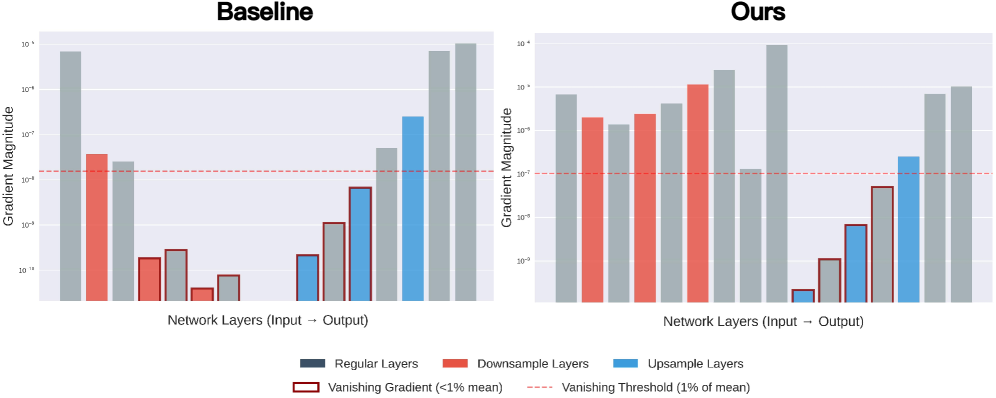
- 现有文本到动作生成模型存在语义不对齐和运动伪影问题,深层网络梯度衰减导致高层特征学习不足。
- LUMA模型通过双路锚定增强语义对齐,分别在时域和频域引入语义监督信号。
- 实验表明,LUMA在HumanML3D和KIT-ML数据集上取得了SOTA性能,并加速了收敛。
📝 摘要(中文)
本文提出LUMA(低维统一运动对齐),一种文本到动作的扩散模型,旨在解决现有基于U-Net架构的模型在文本到动作生成任务中存在的语义不对齐和运动伪影问题。通过分析发现,网络深层的梯度衰减是导致高层特征学习不足的关键瓶颈。LUMA通过引入双路锚定来增强语义对齐。第一条路径采用轻量级的MoCLIP模型,通过对比学习进行训练,无需外部数据,提供时域上的语义监督。第二条路径引入频域中的互补对齐信号,从低频DCT分量中提取,这些分量以其丰富的语义内容而闻名。这两个锚点通过时间调制机制自适应融合,使模型能够在整个去噪过程中从粗略对齐逐步过渡到精细的语义细化。在HumanML3D和KIT-ML上的实验结果表明,LUMA实现了最先进的性能,FID分数分别为0.035和0.123。此外,LUMA与基线相比,收敛速度提高了1.4倍,使其成为高保真文本到动作生成的高效且可扩展的解决方案。
🔬 方法详解
问题定义:现有基于扩散模型的文本到动作生成方法,特别是基于U-Net架构的模型,在生成高质量动作时面临语义不对齐和运动伪影的挑战。这些问题源于网络深层的梯度衰减,导致模型无法充分学习和利用高层语义特征,从而影响生成动作的真实性和与文本描述的一致性。
核心思路:LUMA的核心思路是通过引入双路锚定机制,在时域和频域上提供互补的语义监督信号,从而增强模型对高层语义特征的学习能力,并缓解梯度衰减问题。这种双路锚定机制旨在引导模型在去噪过程中逐步从粗略的语义对齐过渡到精细的语义细化,最终生成高质量的动作。
技术框架:LUMA模型包含一个标准的扩散模型框架,并在此基础上增加了双路锚定模块。第一条路径是时域锚定,使用一个轻量级的MoCLIP模型,通过对比学习提供语义监督。第二条路径是频域锚定,从低频DCT分量中提取语义信息。这两个锚点通过一个时间调制机制进行自适应融合,并将其注入到扩散模型的U-Net结构中。整体流程包括:文本编码、噪声添加、双路锚定、U-Net去噪和动作生成。
关键创新:LUMA的关键创新在于双路锚定机制,它结合了时域和频域的语义信息,并使用时间调制机制进行自适应融合。这种方法能够有效地缓解梯度衰减问题,并增强模型对高层语义特征的学习能力。此外,使用轻量级的MoCLIP模型进行时域锚定,避免了对外部数据的依赖,提高了模型的效率和可扩展性。
关键设计:MoCLIP模型采用对比学习,无需额外数据即可学习文本和动作之间的对应关系。频域锚定使用低频DCT分量,因为这些分量包含丰富的语义信息。时间调制机制允许模型在不同的去噪阶段自适应地调整时域和频域锚点的权重。损失函数包括扩散模型的标准损失函数以及对比学习损失函数。
🖼️ 关键图片


📊 实验亮点
LUMA在HumanML3D和KIT-ML数据集上取得了显著的性能提升,FID分数分别达到了0.035和0.123,超越了现有的SOTA模型。此外,LUMA的收敛速度比基线模型提高了1.4倍,表明其具有更高的训练效率。这些实验结果充分证明了LUMA模型的有效性和优越性。
🎯 应用场景
LUMA模型在人机交互、虚拟现实、游戏开发等领域具有广泛的应用前景。它可以用于生成逼真且符合文本描述的虚拟人物动作,从而提升用户体验。此外,该模型还可以用于动作捕捉数据的修复和增强,以及生成各种风格的舞蹈动作等。未来,LUMA有望成为一个强大的动作生成工具,为各行各业带来创新。
📄 摘要(原文)
While current diffusion-based models, typically built on U-Net architectures, have shown promising results on the text-to-motion generation task, they still suffer from semantic misalignment and kinematic artifacts. Through analysis, we identify severe gradient attenuation in the deep layers of the network as a key bottleneck, leading to insufficient learning of high-level features. To address this issue, we propose \textbf{LUMA} (\textit{\textbf{L}ow-dimension \textbf{U}nified \textbf{M}otion \textbf{A}lignment}), a text-to-motion diffusion model that incorporates dual-path anchoring to enhance semantic alignment. The first path incorporates a lightweight MoCLIP model trained via contrastive learning without relying on external data, offering semantic supervision in the temporal domain. The second path introduces complementary alignment signals in the frequency domain, extracted from low-frequency DCT components known for their rich semantic content. These two anchors are adaptively fused through a temporal modulation mechanism, allowing the model to progressively transition from coarse alignment to fine-grained semantic refinement throughout the denoising process. Experimental results on HumanML3D and KIT-ML demonstrate that LUMA achieves state-of-the-art performance, with FID scores of 0.035 and 0.123, respectively. Furthermore, LUMA accelerates convergence by 1.4$\times$ compared to the baseline, making it an efficient and scalable solution for high-fidelity text-to-motion generation.