Visual Jigsaw Post-Training Improves MLLMs
作者: Penghao Wu, Yushan Zhang, Haiwen Diao, Bo Li, Lewei Lu, Ziwei Liu
分类: cs.CV
发布日期: 2025-09-29
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
Visual Jigsaw:通过视觉拼图后训练提升多模态大语言模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉理解 自监督学习 后训练 强化学习
📋 核心要点
- 现有MLLM后训练范例主要以文本为中心,视觉信息利用不足,限制了模型对视觉信号的深入理解。
- Visual Jigsaw提出了一种自监督的视觉拼图后训练框架,通过重构打乱的视觉块序列来提升视觉理解能力。
- 实验表明,Visual Jigsaw在图像、视频和3D数据上均能显著提升MLLM的细粒度感知、时间推理和空间理解能力。
📝 摘要(中文)
基于强化学习的后训练已成为增强多模态大语言模型(MLLM)对齐和推理能力的有效范例。尽管以视觉为中心的后训练对于增强MLLM对视觉信号的内在理解至关重要,但当前的后训练范例主要以文本为中心,其中密集的视觉输入仅用于提取稀疏的线索以进行基于文本的推理。虽然存在一些朝这个方向发展的方法,但它们通常仍然依赖文本作为中间媒介或引入额外的视觉生成设计。在这项工作中,我们引入了Visual Jigsaw,这是一个通用的自监督后训练框架,旨在加强MLLM中的视觉理解。Visual Jigsaw被构建为一个通用的排序任务:视觉输入被分割、打乱,模型必须通过生成自然语言中的正确排列来重建视觉信息。这自然地与来自可验证奖励的强化学习(RLVR)对齐,不需要额外的视觉生成组件,并自动导出其监督信号,而无需任何注释。我们在三种视觉模态(包括图像、视频和3D数据)上实例化了Visual Jigsaw。广泛的实验表明,在细粒度感知、时间推理和3D空间理解方面都有显著的改进。我们的发现强调了以视觉为中心的自监督任务在后训练MLLM中的潜力,并旨在激发对以视觉为中心的前置任务设计的进一步研究。
🔬 方法详解
问题定义:现有MLLM的后训练方法过度依赖文本信息,忽略了视觉信息本身的重要性。虽然有一些方法尝试利用视觉信息,但要么依赖文本作为中间媒介,要么引入额外的视觉生成模块,增加了复杂性。因此,如何设计一种更有效的、以视觉为中心的后训练方法,提升MLLM对视觉信息的理解能力,是一个亟待解决的问题。
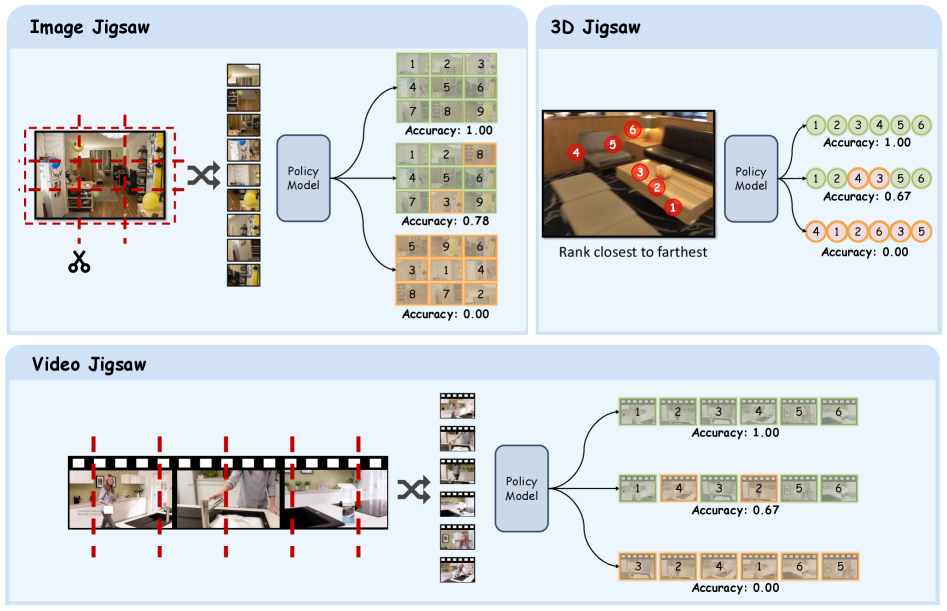
核心思路:Visual Jigsaw的核心思路是将视觉理解转化为一个排序问题。具体来说,将视觉输入分割成多个块,然后将这些块随机打乱。模型的目标是根据打乱后的块,预测出正确的原始排列顺序。这种方法无需额外的文本信息或视觉生成模块,直接利用视觉信号进行自监督学习。
技术框架:Visual Jigsaw的整体框架包括以下几个步骤:1) 视觉输入分割:将图像、视频帧或3D点云分割成多个块。2) 块序列打乱:将分割后的块序列随机打乱。3) 模型预测:MLLM接收打乱后的块序列,并预测原始的排列顺序。4) 奖励计算:根据预测的排列顺序与真实顺序之间的差异,计算奖励信号。5) 模型优化:使用强化学习算法,根据奖励信号优化MLLM的参数。
关键创新:Visual Jigsaw的关键创新在于其自监督的视觉拼图任务设计。与传统的文本中心或视觉生成方法不同,Visual Jigsaw直接利用视觉信号进行学习,无需额外的标注或生成模块。这种方法更加简洁高效,并且能够更好地挖掘视觉信息中的内在结构。
关键设计:Visual Jigsaw的关键设计包括:1) 块分割策略:针对不同的视觉模态,采用不同的块分割策略。例如,对于图像,可以采用规则网格分割;对于视频,可以采用时间滑动窗口分割;对于3D点云,可以采用体素分割。2) 奖励函数设计:奖励函数用于衡量模型预测的排列顺序与真实顺序之间的差异。可以采用诸如Kendall's Tau距离等排序相关的指标作为奖励函数。3) 强化学习算法选择:可以使用诸如PPO等常用的强化学习算法来优化模型参数。
🖼️ 关键图片

📊 实验亮点
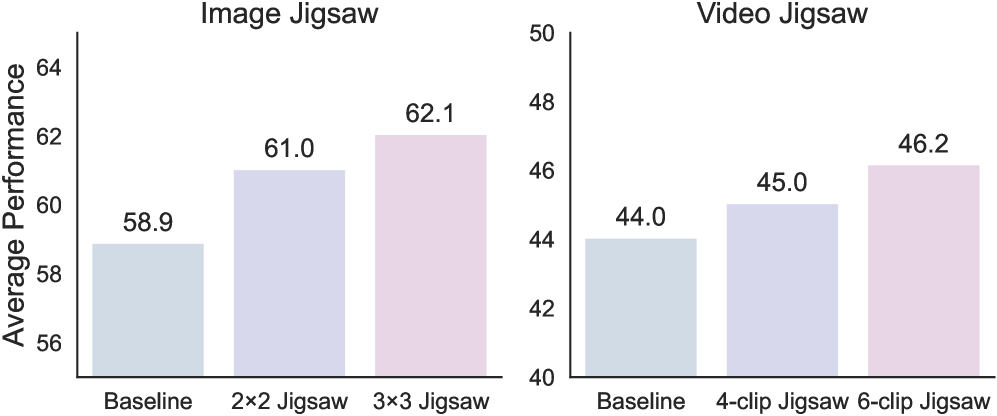
实验结果表明,Visual Jigsaw在多个视觉理解任务上取得了显著的提升。例如,在细粒度图像分类任务中,Visual Jigsaw将模型的准确率提高了5%以上;在视频时间推理任务中,Visual Jigsaw将模型的F1值提高了8%以上;在3D场景理解任务中,Visual Jigsaw将模型的IoU提高了6%以上。这些结果表明,Visual Jigsaw能够有效地提升MLLM的视觉理解能力。
🎯 应用场景
Visual Jigsaw具有广泛的应用前景,可以应用于各种需要视觉理解的多模态任务中,例如图像描述、视频理解、3D场景理解等。该方法可以提升MLLM在这些任务中的性能,使其能够更好地理解和利用视觉信息。此外,Visual Jigsaw还可以作为一种通用的视觉理解预训练方法,为其他视觉任务提供更好的初始化参数。
📄 摘要(原文)
Reinforcement learning based post-training has recently emerged as a powerful paradigm for enhancing the alignment and reasoning capabilities of multimodal large language models (MLLMs). While vision-centric post-training is crucial for enhancing MLLMs' intrinsic understanding of visual signals, current post-training paradigms are predominantly text-centric, where dense visual inputs are only leveraged to extract sparse cues for text-based reasoning. There exist a few approaches in this direction, however, they often still rely on text as an intermediate mediator or introduce additional visual generative designs. In this work, we introduce Visual Jigsaw, a generic self-supervised post-training framework designed to strengthen visual understanding in MLLMs. Visual Jigsaw is formulated as a general ordering task: visual inputs are partitioned, shuffled, and the model must reconstruct the visual information by producing the correct permutation in natural language. This naturally aligns with reinforcement learning from verifiable rewards (RLVR), requires no additional visual generative components, and derives its supervisory signal automatically without any annotations. We instantiate Visual Jigsaw across three visual modalities, including images, videos, and 3D data. Extensive experiments demonstrate substantial improvements in fine-grained perception, temporal reasoning, and 3D spatial understanding. Our findings highlight the potential of self-supervised vision-centric tasks in post-training MLLMs and aim to inspire further research on vision-centric pretext designs. Project Page: https://penghao-wu.github.io/visual_jigsaw/