PAD3R: Pose-Aware Dynamic 3D Reconstruction from Casual Videos
作者: Ting-Hsuan Liao, Haowen Liu, Yiran Xu, Songwei Ge, Gengshan Yang, Jia-Bin Huang
分类: cs.CV
发布日期: 2025-09-29
备注: SIGGRAPH Asia 2025. Project page:https://pad3r.github.io/
💡 一句话要点
PAD3R:从单目视频中进行姿态感知的动态3D重建
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 动态3D重建 单目视频 姿态估计 可变形对象 3D高斯表示
📋 核心要点
- 现有方法难以处理长视频中对象的大幅度形变和相机的大范围运动,以及视角覆盖不足的情况。
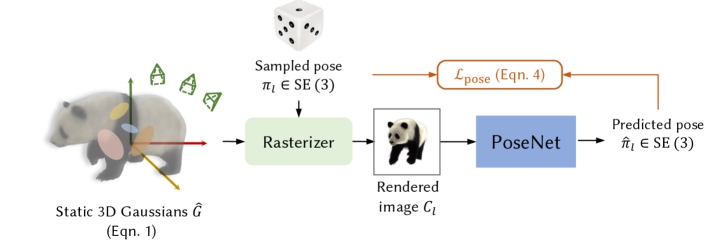
- PAD3R 训练一个以对象为中心的姿态估计器,并利用预训练的图像到 3D 模型进行监督,从而指导可变形 3D 高斯表示的优化。
- 实验结果表明,PAD3R 在具有挑战性的场景中表现出良好的鲁棒性和泛化能力,能够重建高保真度的动态 3D 对象。
📝 摘要(中文)
PAD3R 是一种从随意拍摄的、无姿态单目视频中重建可变形 3D 对象的方法。与现有方法不同,PAD3R 可以处理包含显著对象变形、大规模相机运动和有限视角覆盖的长视频序列,这些通常会给传统系统带来挑战。该方法的核心是训练一个个性化的、以对象为中心的姿态估计器,并由预训练的图像到 3D 模型进行监督。这指导了可变形 3D 高斯表示的优化。优化过程还受到整个输入视频中长期 2D 点跟踪的约束。通过结合生成先验和可微渲染,PAD3R 以类别无关的方式重建对象的高保真、铰接式 3D 表示。大量的定性和定量结果表明,PAD3R 具有鲁棒性,并且可以在具有挑战性的场景中很好地泛化,突出了其在动态场景理解和 3D 内容创建方面的潜力。
🔬 方法详解
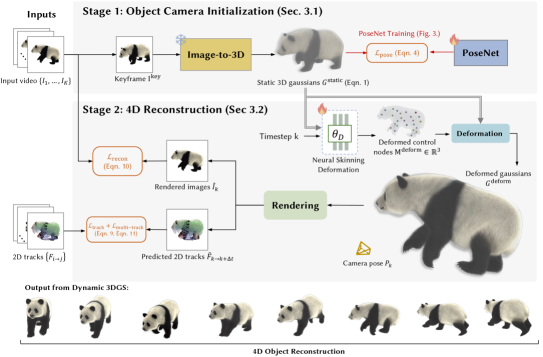
问题定义:现有方法在处理从随意拍摄的单目视频中重建可变形3D对象时,面临着长视频序列中对象大幅度形变、相机大范围运动以及视角覆盖不足等挑战。这些因素会导致重建质量下降,甚至重建失败。
核心思路:PAD3R的核心思路是利用预训练的图像到3D模型作为先验知识,并结合可微渲染和长期2D点跟踪,来优化可变形的3D高斯表示。通过姿态估计器来指导优化过程,从而更好地处理对象形变和相机运动。
技术框架:PAD3R的整体框架包括以下几个主要模块:1) 个性化姿态估计器训练:利用预训练的图像到3D模型监督训练对象中心的姿态估计器。2) 可变形3D高斯表示优化:使用姿态估计器指导3D高斯表示的优化,并结合可微渲染和长期2D点跟踪进行正则化。3) 最终3D模型重建:通过优化后的3D高斯表示重建最终的3D模型。
关键创新:PAD3R的关键创新在于:1) 提出了一种个性化的、以对象为中心的姿态估计器,能够更好地处理对象形变和相机运动。2) 将预训练的图像到3D模型作为先验知识,指导可变形3D高斯表示的优化。3) 结合长期2D点跟踪,进一步提高重建的鲁棒性和准确性。与现有方法相比,PAD3R能够处理更具挑战性的场景,并重建更高质量的3D模型。
关键设计:PAD3R的关键设计包括:1) 姿态估计器的网络结构和训练方式,使用了预训练模型的知识蒸馏。2) 3D高斯表示的参数化方式和优化算法,使用了可微渲染技术。3) 长期2D点跟踪的实现方式,使用了光流法和特征匹配。
🖼️ 关键图片

📊 实验亮点
论文通过大量的定性和定量实验验证了 PAD3R 的有效性。实验结果表明,PAD3R 在处理具有挑战性的场景时,能够重建出高质量的 3D 模型,并且具有良好的鲁棒性和泛化能力。与现有方法相比,PAD3R 在重建精度和视觉效果方面均有显著提升。具体性能数据未知,但论文强调了其在复杂场景下的优越性。
🎯 应用场景
PAD3R 的潜在应用领域包括动态场景理解、3D 内容创作、虚拟现实/增强现实等。该技术可以用于从日常视频中重建高质量的 3D 模型,从而为用户提供更逼真的交互体验。此外,PAD3R 还可以应用于机器人导航、自动驾驶等领域,帮助机器人更好地理解周围环境。
📄 摘要(原文)
We present PAD3R, a method for reconstructing deformable 3D objects from casually captured, unposed monocular videos. Unlike existing approaches, PAD3R handles long video sequences featuring substantial object deformation, large-scale camera movement, and limited view coverage that typically challenge conventional systems. At its core, our approach trains a personalized, object-centric pose estimator, supervised by a pre-trained image-to-3D model. This guides the optimization of deformable 3D Gaussian representation. The optimization is further regularized by long-term 2D point tracking over the entire input video. By combining generative priors and differentiable rendering, PAD3R reconstructs high-fidelity, articulated 3D representations of objects in a category-agnostic way. Extensive qualitative and quantitative results show that PAD3R is robust and generalizes well across challenging scenarios, highlighting its potential for dynamic scene understanding and 3D content creation.