GHOST: Hallucination-Inducing Image Generation for Multimodal LLMs
作者: Aryan Yazdan Parast, Parsa Hosseini, Hesam Asadollahzadeh, Arshia Soltani Moakhar, Basim Azam, Soheil Feizi, Naveed Akhtar
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-09-29 (更新: 2026-01-31)
💡 一句话要点
GHOST:通过诱导幻觉的图像生成方法,用于压力测试多模态LLM
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 幻觉 对抗样本生成 图像生成 安全性评估
📋 核心要点
- 多模态大语言模型易产生幻觉,即识别图像中不存在的物体,现有静态测试集难以充分暴露模型弱点。
- GHOST通过优化图像嵌入,生成视觉上自然但包含误导性线索的图像,诱导模型产生幻觉。
- 实验表明,GHOST能有效诱导多种模型产生幻觉,成功率远超现有方法,且生成的图像可用于微调以缓解幻觉。
📝 摘要(中文)
多模态大型语言模型(MLLM)中的对象幻觉是一种持续存在的失效模式,导致模型感知到图像中不存在的对象。目前,对MLLM的这种弱点的研究主要使用静态基准,这些基准具有固定的视觉场景,从而排除了发现模型特定或意外幻觉漏洞的可能性。我们引入了GHOST(通过优化隐蔽令牌生成幻觉),这是一种旨在通过主动生成诱导幻觉的图像来压力测试MLLM的方法。GHOST是完全自动化的,不需要人工监督或先验知识。它通过在图像嵌入空间中进行优化来误导模型,同时保持目标对象不存在,然后引导以嵌入为条件的扩散模型生成自然外观的图像。生成的图像在视觉上保持自然并接近原始输入,但引入了细微的误导性线索,导致模型产生幻觉。我们在一系列模型(包括推理模型如GLM-4.1V-Thinking)上评估了我们的方法,并实现了超过28%的幻觉成功率,而先前的数据驱动发现方法约为1%。我们通过定量指标和人工评估证实,生成的图像既高质量又无对象。此外,GHOST揭示了可转移的漏洞:为Qwen2.5-VL优化的图像以66.5%的速率在GPT-4o中诱导幻觉。最后,我们表明,在我们的图像上进行微调可以减轻幻觉,从而使GHOST成为构建更可靠的多模态系统的诊断和纠正工具。
🔬 方法详解
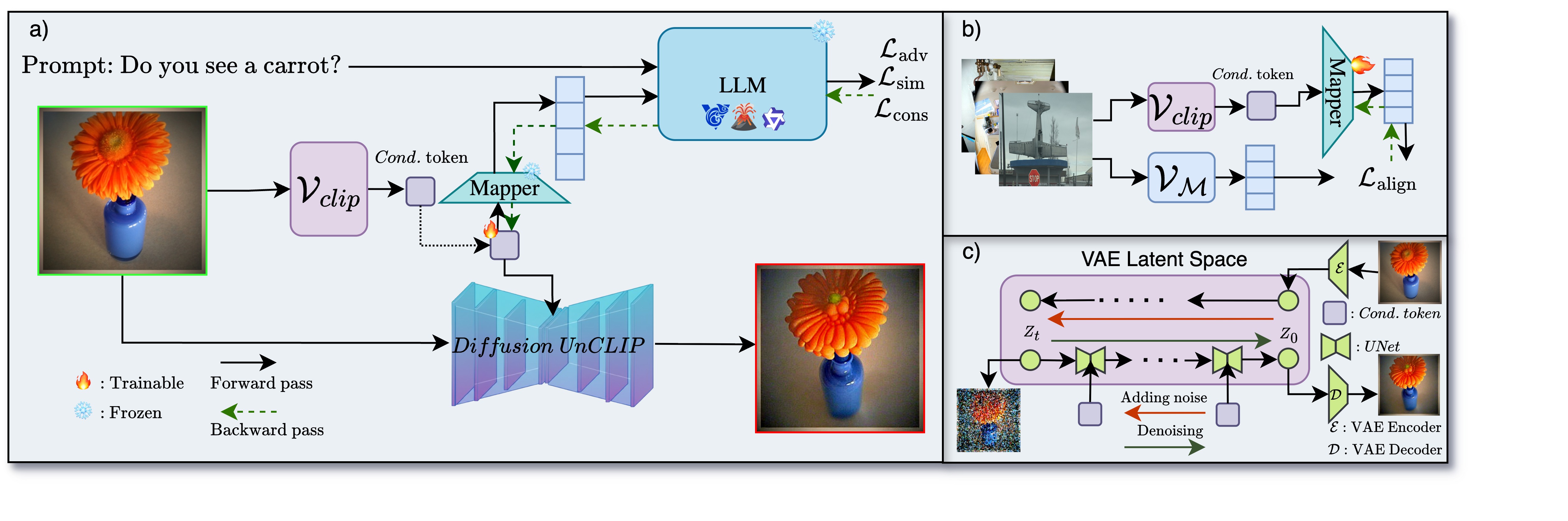
问题定义:多模态大型语言模型(MLLM)在理解图像内容时,容易产生“幻觉”,即错误地识别出图像中不存在的物体。现有的评估方法主要依赖于静态数据集,这些数据集可能无法充分暴露模型潜在的幻觉漏洞,缺乏主动探索模型弱点的能力。因此,如何设计一种方法,能够主动生成诱导MLLM产生幻觉的图像,成为了一个重要的研究问题。
核心思路:GHOST的核心思路是通过优化图像的嵌入表示,在不引入真实目标对象的前提下, subtly 地修改图像,使其包含能够误导 MLLM 的视觉线索,从而诱导模型产生幻觉。这种方法旨在主动探索 MLLM 的弱点,而不是被动地依赖于预先定义好的数据集。通过控制图像嵌入,可以生成既保持视觉自然度,又能有效诱导幻觉的图像。
技术框架:GHOST 的整体框架包含以下几个主要步骤:1) 初始化图像嵌入:选择一张初始图像,并提取其嵌入表示。2) 优化嵌入:在图像嵌入空间中进行优化,目标是最大化模型产生目标对象幻觉的概率,同时约束嵌入的修改幅度,以保持图像的视觉自然度。3) 图像生成:使用条件扩散模型,以优化后的嵌入为条件,生成最终的图像。4) 评估:使用 MLLM 评估生成的图像是否成功诱导了幻觉。
关键创新:GHOST 的关键创新在于其主动生成诱导幻觉图像的能力。与传统的被动评估方法不同,GHOST 能够根据模型的特性,针对性地生成能够暴露其弱点的图像。此外,GHOST 通过在图像嵌入空间中进行优化,实现了对图像内容的精细控制,能够在不引入真实目标对象的前提下, subtly 地修改图像,从而避免了简单地添加噪声或篡改图像内容。
关键设计:GHOST 的关键设计包括:1) 优化目标:使用交叉熵损失函数,最大化模型预测目标对象存在的概率。2) 正则化项:添加 L2 正则化项,约束嵌入的修改幅度,以保持图像的视觉自然度。3) 扩散模型:使用 Stable Diffusion 等预训练的扩散模型,以优化后的嵌入为条件,生成高质量的图像。4) 隐蔽令牌 (Stealth Tokens):通过优化图像嵌入,引入不易察觉的视觉线索,诱导模型产生幻觉。
🖼️ 关键图片


📊 实验亮点
GHOST 在多种 MLLM 上实现了显著的幻觉诱导效果,成功率超过 28%,远高于传统数据驱动方法的 1%。实验还发现,为 Qwen2.5-VL 优化的图像能够以 66.5% 的概率在 GPT-4o 中诱导幻觉,表明 GHOST 发现的漏洞具有一定的可迁移性。通过在 GHOST 生成的图像上进行微调,可以有效缓解模型的幻觉问题。
🎯 应用场景
GHOST 可用于多模态大语言模型的安全性和鲁棒性评估,帮助开发者发现模型潜在的幻觉漏洞。通过在 GHOST 生成的图像上进行微调,可以提高模型的抗幻觉能力,从而构建更可靠的多模态系统。此外,该方法还可以用于生成对抗样本,研究模型的决策边界,提升模型的泛化能力。
📄 摘要(原文)
Object hallucination in Multimodal Large Language Models (MLLMs) is a persistent failure mode that causes the model to perceive objects absent in the image. This weakness of MLLMs is currently studied using static benchmarks with fixed visual scenarios, which preempts the possibility of uncovering model-specific or unanticipated hallucination vulnerabilities. We introduce GHOST (Generating Hallucinations via Optimizing Stealth Tokens), a method designed to stress-test MLLMs by actively generating images that induce hallucination. GHOST is fully automatic and requires no human supervision or prior knowledge. It operates by optimizing in the image embedding space to mislead the model while keeping the target object absent, and then guiding a diffusion model conditioned on the embedding to generate natural-looking images. The resulting images remain visually natural and close to the original input, yet introduce subtle misleading cues that cause the model to hallucinate. We evaluate our method across a range of models, including reasoning models like GLM-4.1V-Thinking, and achieve a hallucination success rate exceeding 28%, compared to around 1% in prior data-driven discovery methods. We confirm that the generated images are both high-quality and object-free through quantitative metrics and human evaluation. Also, GHOST uncovers transferable vulnerabilities: images optimized for Qwen2.5-VL induce hallucinations in GPT-4o at a 66.5% rate. Finally, we show that fine-tuning on our images mitigates hallucination, positioning GHOST as both a diagnostic and corrective tool for building more reliable multimodal systems.