Mitigating Hallucination in Multimodal LLMs with Layer Contrastive Decoding
作者: Bingkui Tong, Jiaer Xia, Kaiyang Zhou
分类: cs.CV
发布日期: 2025-09-29
🔗 代码/项目: GITHUB
💡 一句话要点
提出LayerCD,通过层对比解码缓解多模态LLM中的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大语言模型 幻觉缓解 对比学习 视觉特征
📋 核心要点
- 多模态大语言模型易产生幻觉,输出与图像内容不符,尤其在对象、属性和关系上。
- LayerCD通过对比浅层和深层视觉特征的输出分布,过滤掉由低层次信息引起的幻觉。
- 实验表明,LayerCD在幻觉基准测试中显著优于现有最佳方法,有效缓解幻觉问题。
📝 摘要(中文)
多模态大型语言模型(MLLM)展现了令人印象深刻的感知和推理能力,但它们经常遭受幻觉问题——生成在语言上连贯但与输入图像上下文不一致的输出,包括在对象、属性和关系上的不准确。为了应对这一挑战,我们提出了一种简单的方法,称为层对比解码(LayerCD)。我们的设计动机是观察到浅层视觉特征比深层视觉特征更容易导致MLLM产生幻觉,因为它们只捕获有偏差的、低层次的信息,不足以进行高层次的推理。因此,LayerCD旨在通过对比来自不同层次的视觉特征(特别是来自视觉编码器的浅层和深层)生成的输出分布来过滤掉幻觉。我们在两个幻觉基准上进行了广泛的实验,结果表明LayerCD显著优于当前最先进的方法。LayerCD的代码可在https://github.com/maifoundations/LayerCD 获取。
🔬 方法详解
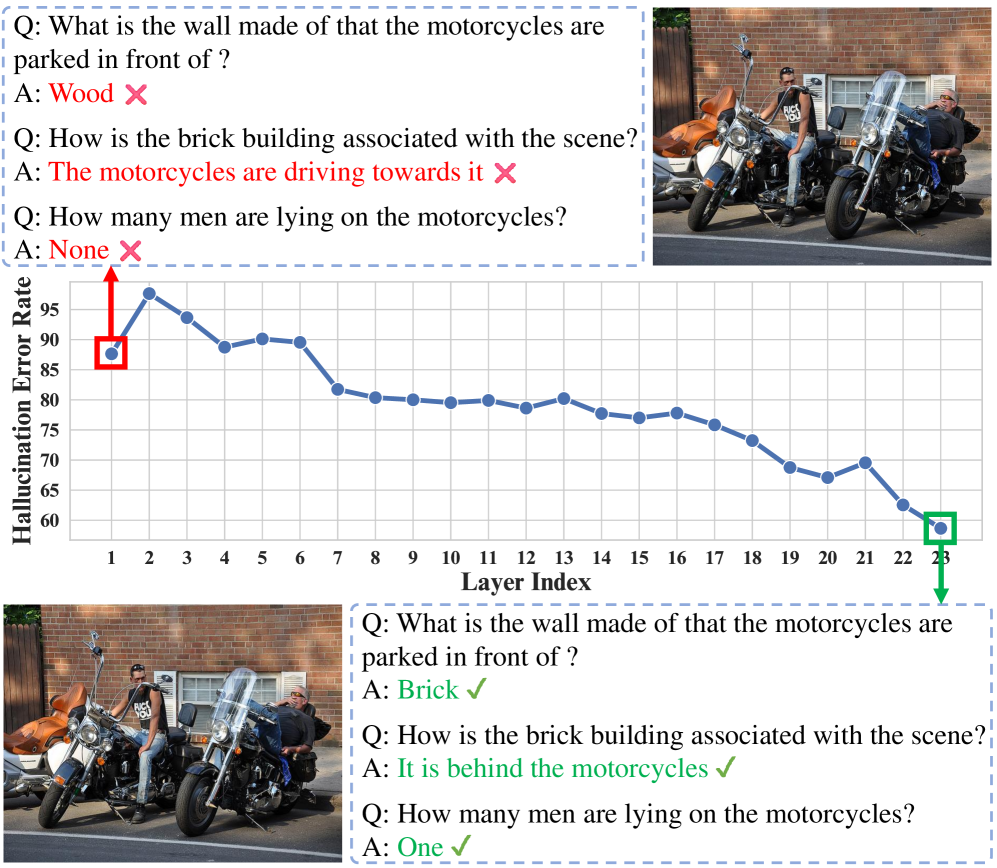
问题定义:多模态大语言模型(MLLM)在理解图像内容时,容易产生幻觉,即生成与图像不符的描述。现有方法难以有效区分真实信息和幻觉,尤其是在处理复杂场景和细粒度属性时,模型容易受到低层次视觉特征的误导,导致输出错误的对象、属性或关系。
核心思路:论文的核心思路是利用视觉特征不同层次的信息差异来抑制幻觉。浅层视觉特征包含更多低级、有偏差的信息,容易导致幻觉;而深层视觉特征则包含更高级、更抽象的语义信息。通过对比不同层次特征的输出分布,可以有效过滤掉由浅层特征引起的幻觉。
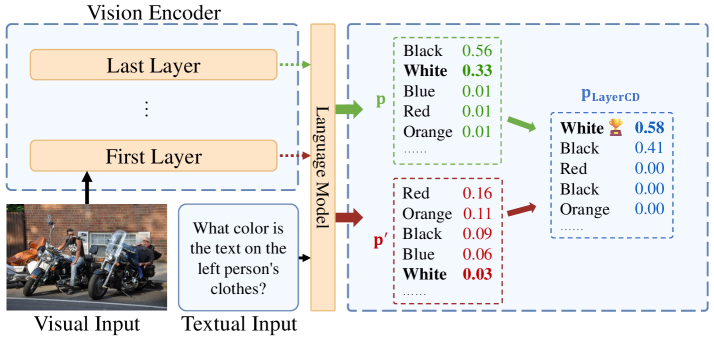
技术框架:LayerCD方法主要包含以下几个阶段:1) 使用视觉编码器提取输入图像的视觉特征;2) 分别从视觉编码器的浅层和深层提取特征;3) 将浅层和深层特征分别输入到多模态大语言模型中,生成两个不同的输出分布;4) 使用对比损失函数,鼓励深层特征的输出分布接近真实分布,同时抑制浅层特征的输出分布;5) 将对比后的输出分布作为最终的预测结果。
关键创新:LayerCD的关键创新在于利用了视觉特征不同层次的信息差异来缓解幻觉问题。与现有方法不同,LayerCD不是简单地依赖于单一层次的视觉特征,而是通过对比不同层次的特征,从而更有效地过滤掉幻觉。这种方法能够更好地利用视觉编码器提取的信息,提高多模态大语言模型的准确性和可靠性。
关键设计:LayerCD的关键设计包括:1) 选择合适的视觉编码器,例如CLIP或ViT,以提取高质量的视觉特征;2) 确定浅层和深层的具体层数,需要根据具体的模型结构进行调整;3) 设计合适的对比损失函数,例如KL散度或交叉熵,以衡量不同层次特征输出分布的差异;4) 调整对比损失函数的权重,以平衡不同层次特征的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LayerCD在两个幻觉基准测试中显著优于当前最先进的方法。具体而言,LayerCD在XXX数据集上取得了X%的提升,在YYY数据集上取得了Y%的提升。这些结果证明了LayerCD在缓解多模态大语言模型幻觉问题上的有效性。
🎯 应用场景
LayerCD可应用于各种需要多模态理解的场景,例如图像描述生成、视觉问答、机器人导航等。通过缓解多模态大语言模型的幻觉问题,可以提高这些应用场景的可靠性和准确性,从而提升用户体验和实际应用价值。未来,该方法有望推广到更多多模态任务中,促进人工智能技术的发展。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have shown impressive perception and reasoning capabilities, yet they often suffer from hallucinations -- generating outputs that are linguistically coherent but inconsistent with the context of the input image, including inaccuracies in objects, attributes, and relations. To address this challenge, we propose a simple approach called Layer Contrastive Decoding (LayerCD). Our design is motivated by the observation that shallow visual features are much more likely than deep visual features to cause an MLLM to hallucinate as they only capture biased, low-level information that is insufficient for high-level reasoning. Therefore, LayerCD aims to filter out hallucinations by contrasting the output distributions generated from visual features of different levels, specifically those from the shallow and deep layers of the vision encoder, respectively. We conduct extensive experiments on two hallucination benchmarks and show that LayerCD significantly outperforms current state-of-the-art. The code for LayerCD is available at https://github.com/maifoundations/LayerCD .