VideoAnchor: Reinforcing Subspace-Structured Visual Cues for Coherent Visual-Spatial Reasoning
作者: Zhaozhi Wang, Tong Zhang, Mingyue Guo, Yaowei Wang, Qixiang Ye
分类: cs.CV
发布日期: 2025-09-29
备注: 16 pages, 6 figures
🔗 代码/项目: GITHUB
💡 一句话要点
VideoAnchor:通过强化子空间结构视觉线索实现连贯的视觉-空间推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉空间推理 视频理解 注意力机制 子空间聚类
📋 核心要点
- 现有多模态大模型在视觉空间推理上存在不足,原因是注意力机制使得视觉token容易被语言token掩盖。
- VideoAnchor的核心思想是利用子空间聚类的自表达特性,通过子空间亲和性来增强跨帧的视觉线索。
- 实验结果表明,VideoAnchor在多个基准测试和骨干模型上均取得了显著的性能提升,且无需重新训练。
📝 摘要(中文)
多模态大型语言模型(MLLMs)在视觉-语言对齐方面取得了显著进展,但在视觉-空间推理方面仍然存在局限性。我们首先指出,这种局限性源于注意力机制:视觉token被语言token所掩盖,导致模型无法跨帧一致地识别相同的视觉线索。为了解决这个挑战,我们提出了稀疏子空间聚类中的自表达属性与Transformer中的注意力机制之间的新颖联系。基于这一洞察,我们提出VideoAnchor,这是一个即插即用模块,它利用子空间亲和力来增强跨帧的视觉线索,而无需重新训练,从而有效地将注意力锚定到共享的视觉结构上。在多个基准测试和骨干模型上的大量实验表明,性能得到了持续提升,例如,在使用InternVL2-8B和Qwen2.5VL-72B时,在VSI-Bench和Video-MME(空间相关任务)上分别提高了3.2%和4.6%,同时定性分析表明,子空间划分更加连贯,视觉基础更强。我们的代码将在https://github.com/feufhd/VideoAnchor上公开。
🔬 方法详解
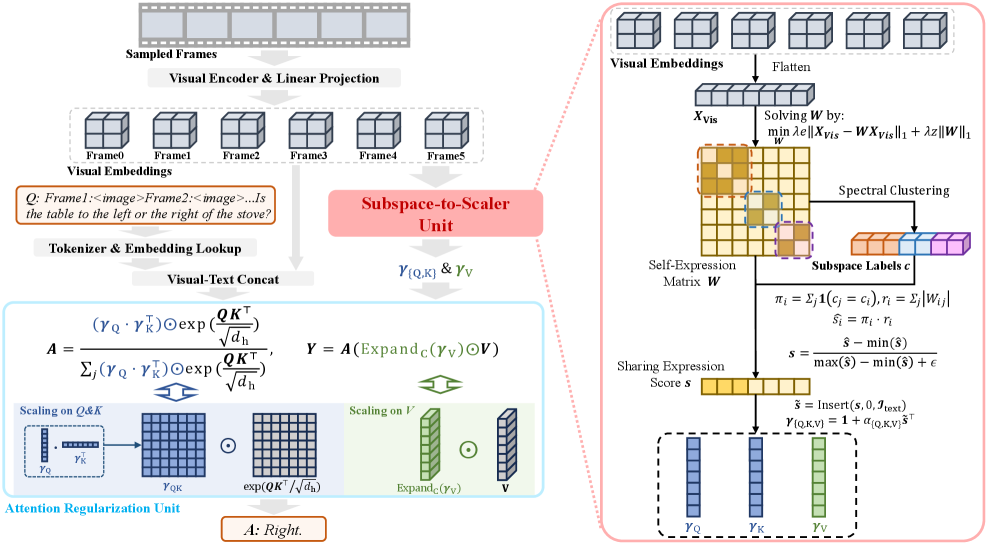
问题定义:多模态大语言模型在视觉-空间推理任务中表现不佳,尤其是在视频理解中,模型难以保持对同一视觉线索的持续关注。现有方法的痛点在于,注意力机制容易受到语言token的影响,导致视觉token的表达被削弱,从而无法有效捕捉视频中的空间关系和动态变化。
核心思路:论文的核心思路是将视频帧中的视觉token视为高维空间中的数据点,并利用子空间聚类的思想,假设相似的视觉线索位于同一个子空间中。通过计算token之间的子空间亲和性,可以增强属于同一子空间的token之间的联系,从而使模型更加关注重要的视觉线索,并抑制无关信息的干扰。这样设计的目的是为了提高模型在视频理解任务中的视觉空间推理能力。
技术框架:VideoAnchor是一个即插即用的模块,可以添加到现有的多模态大语言模型中。其主要流程如下:1. 从视频帧中提取视觉特征,得到视觉token序列。2. 计算视觉token之间的子空间亲和性矩阵,该矩阵反映了token之间属于同一子空间的概率。3. 利用子空间亲和性矩阵来调整注意力权重,增强属于同一子空间的token之间的注意力,抑制不同子空间token之间的注意力。4. 将调整后的注意力权重应用于视觉特征,得到增强后的视觉表示。
关键创新:该论文的关键创新在于将子空间聚类的思想引入到多模态大语言模型的注意力机制中,提出了一种新的视觉增强方法VideoAnchor。与现有方法相比,VideoAnchor无需重新训练模型,即可有效地提高模型在视觉-空间推理任务中的性能。此外,VideoAnchor还能够提供更连贯的子空间划分和更强的视觉基础。
关键设计:子空间亲和性矩阵的计算是VideoAnchor的关键设计之一。论文采用了稀疏子空间聚类的方法来计算子空间亲和性矩阵,该方法能够有效地处理高维数据,并提取出数据中的潜在结构。具体来说,论文使用了L1范数最小化来求解子空间表示系数,然后利用这些系数来计算子空间亲和性矩阵。此外,论文还设计了一种注意力调整机制,该机制能够根据子空间亲和性矩阵来动态地调整注意力权重,从而实现对视觉线索的增强。
🖼️ 关键图片


📊 实验亮点
实验结果表明,VideoAnchor在VSI-Bench和Video-MME等空间相关任务上取得了显著的性能提升。例如,在使用InternVL2-8B和Qwen2.5VL-72B作为骨干模型时,在VSI-Bench上分别提高了3.2%,在Video-MME上提高了4.6%。这些结果表明,VideoAnchor能够有效地增强模型对视频中视觉空间关系的理解,从而提高模型在视觉-空间推理任务中的性能。
🎯 应用场景
VideoAnchor具有广泛的应用前景,可应用于视频理解、视频问答、视频目标跟踪、视频编辑等领域。通过增强模型对视频中视觉空间关系的理解,可以提高这些应用在复杂场景下的性能和鲁棒性。该研究的成果有助于推动多模态大语言模型在视频领域的应用和发展。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have achieved impressive progress in vision-language alignment, yet they remain limited in visual-spatial reasoning. We first identify that this limitation arises from the attention mechanism: visual tokens are overshadowed by language tokens, preventing the model from consistently recognizing the same visual cues across frames. To address this challenge, we draw a novel connection between the self-expressiveness property in sparse subspace clustering and the attention mechanism in Transformers. Building on this insight, we propose VideoAnchor, a plug-and-play module that leverages subspace affinities to reinforce visual cues across frames without retraining, effectively anchoring attention to shared visual structures. Extensive experiments across benchmarks and backbone models show consistent performance gains -- $e.g.$, 3.2% and 4.6% improvements on VSI-Bench and Video-MME (spatial-related tasks) with InternVL2-8B and Qwen2.5VL-72B -- while qualitative analyses demonstrate more coherent subspace partitions and stronger visual grounding. Our codes will be made public available at https://github.com/feufhd/VideoAnchor.