Score Distillation of Flow Matching Models
作者: Mingyuan Zhou, Yi Gu, Huangjie Zheng, Liangchen Song, Guande He, Yizhe Zhang, Wenze Hu, Yinfei Yang
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-09-29 (更新: 2025-12-03)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
将Score Distillation成功应用于Flow Matching模型,实现快速高质量图像生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Flow Matching 扩散模型 Score Distillation 图像生成 模型蒸馏 文本到图像生成 DiT 生成模型加速
📋 核心要点
- 扩散模型采样速度慢,限制了其应用,而蒸馏是加速扩散模型的重要手段。
- 论文基于贝叶斯规则推导,统一了高斯扩散和Flow Matching,为蒸馏提供了理论基础。
- 实验证明Score Distillation (SiD) 可直接应用于多种 Flow Matching 模型,无需额外调整。
📝 摘要(中文)
扩散模型在图像生成方面表现出色,但受限于缓慢的迭代采样过程。蒸馏方法通过实现单步或少数步生成来缓解这一问题。Flow matching最初作为一个独立的框架被提出,但后来被证明在Gaussian假设下与扩散模型在理论上是等价的。这引发了一个问题:诸如score distillation之类的蒸馏技术是否可以直接迁移。我们提供了一个简单的推导——基于贝叶斯规则和条件期望——统一了Gaussian扩散和flow matching,而无需依赖ODE/SDE公式。在此基础上,我们将Score identity Distillation (SiD)扩展到预训练的文本到图像flow-matching模型,包括SANA、SD3-Medium、SD3.5-Medium/Large和FLUX.1-dev,所有这些模型都具有DiT骨干网络。实验表明,只需对flow-matching和DiT进行适度的调整,SiD就可以在这些模型中开箱即用,无论是在无数据还是有数据的设置中,而无需教师微调或架构更改。这首次系统地证明了score distillation广泛适用于文本到图像flow matching模型,解决了之前关于稳定性和合理性的担忧,并统一了基于扩散和基于flow的生成器的加速技术。
🔬 方法详解
问题定义:论文旨在解决扩散模型生成图像速度慢的问题,特别是针对Flow Matching模型,探索是否能像加速扩散模型一样,通过蒸馏技术加速Flow Matching模型的图像生成过程。现有方法,如直接应用扩散模型的蒸馏方法到Flow Matching模型,可能面临稳定性和有效性的问题。
核心思路:论文的核心思路是证明在特定条件下(Gaussian假设),扩散模型和Flow Matching模型在理论上是等价的,因此扩散模型的蒸馏方法(如Score Distillation)可以直接应用于Flow Matching模型。通过贝叶斯规则和条件期望,论文提供了一个统一的视角,将两种模型联系起来。
技术框架:论文的技术框架主要包括以下几个步骤:1) 从理论上推导扩散模型和Flow Matching模型的等价性;2) 将Score identity Distillation (SiD) 方法应用于预训练的文本到图像Flow Matching模型(SANA、SD3等);3) 在不同数据集和模型上进行实验,验证SiD的有效性。整个流程无需对教师模型进行微调或改变模型架构。
关键创新:论文的关键创新在于:1) 提供了一个简洁的理论框架,统一了Gaussian扩散和Flow Matching,无需依赖复杂的ODE/SDE公式;2) 首次系统地证明了Score Distillation可以广泛应用于文本到图像Flow Matching模型,解决了之前关于稳定性和合理性的担忧;3) 验证了SiD在多种Flow Matching模型上的有效性,无需复杂的模型调整。
关键设计:论文的关键设计包括:1) 使用Score identity Distillation (SiD) 作为蒸馏方法,该方法基于对score函数的学习;2) 针对不同的Flow Matching模型(如SANA、SD3),进行适度的模型调整,以保证SiD的有效性;3) 在数据辅助和无数据两种设置下进行实验,验证SiD的泛化能力;4) 使用DiT作为Flow Matching模型的骨干网络。
🖼️ 关键图片

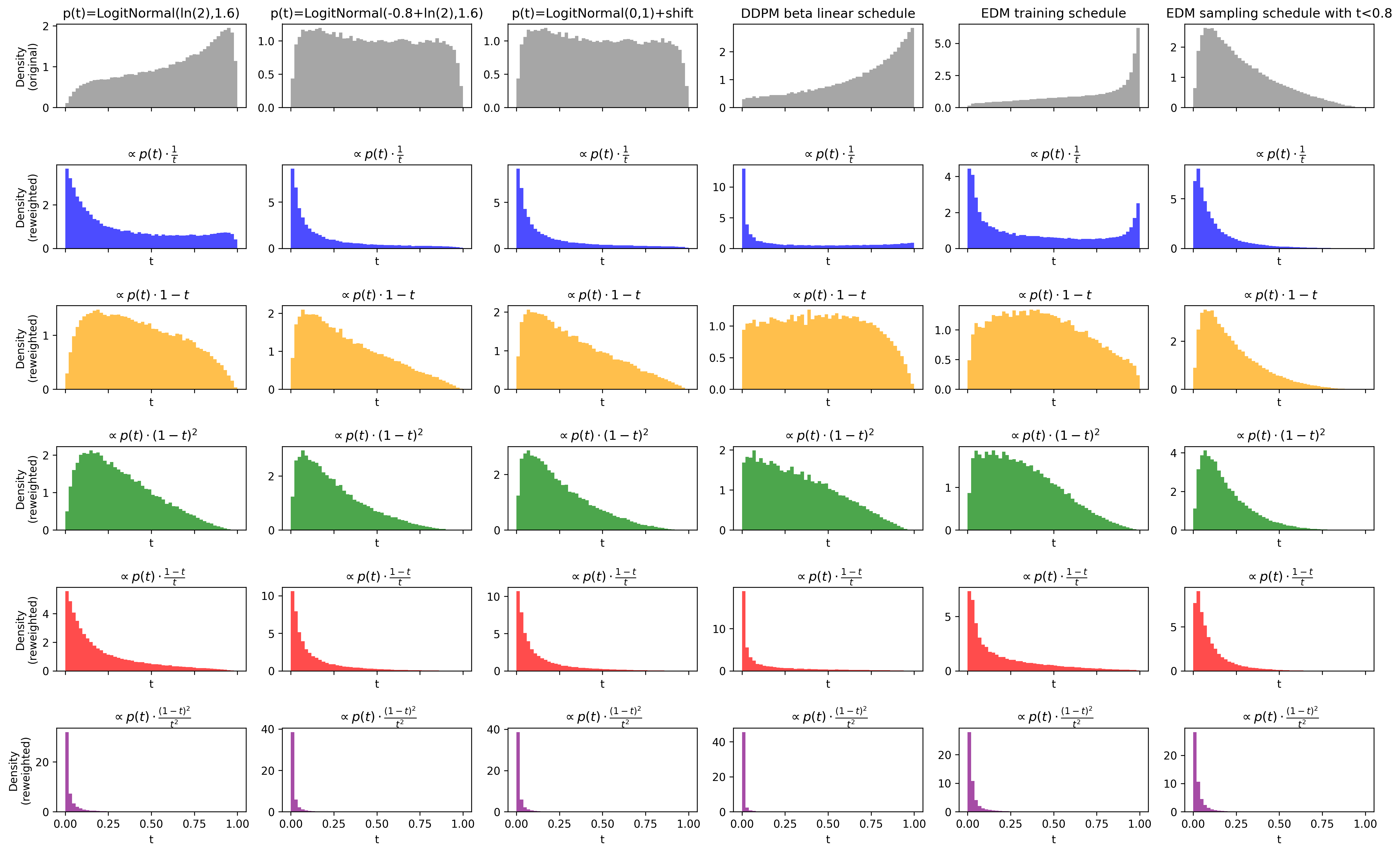

📊 实验亮点
实验结果表明,Score Distillation (SiD) 可以成功应用于多种预训练的文本到图像Flow Matching模型,包括SANA、SD3-Medium、SD3.5-Medium/Large和FLUX.1-dev。在这些模型上,SiD无需教师微调或架构更改即可实现快速高质量的图像生成,验证了该方法在不同模型和数据集上的泛化能力。
🎯 应用场景
该研究成果可广泛应用于图像生成领域,尤其是在需要快速生成高质量图像的场景中,例如游戏开发、虚拟现实、内容创作等。通过蒸馏加速Flow Matching模型,可以显著降低计算成本,提高生成效率,并为实时图像生成应用提供可能性。
📄 摘要(原文)
Diffusion models achieve high-quality image generation but are limited by slow iterative sampling. Distillation methods alleviate this by enabling one- or few-step generation. Flow matching, originally introduced as a distinct framework, has since been shown to be theoretically equivalent to diffusion under Gaussian assumptions, raising the question of whether distillation techniques such as score distillation transfer directly. We provide a simple derivation -- based on Bayes' rule and conditional expectations -- that unifies Gaussian diffusion and flow matching without relying on ODE/SDE formulations. Building on this view, we extend Score identity Distillation (SiD) to pretrained text-to-image flow-matching models, including SANA, SD3-Medium, SD3.5-Medium/Large, and FLUX.1-dev, all with DiT backbones. Experiments show that, with only modest flow-matching- and DiT-specific adjustments, SiD works out of the box across these models, in both data-free and data-aided settings, without requiring teacher finetuning or architectural changes. This provides the first systematic evidence that score distillation applies broadly to text-to-image flow matching models, resolving prior concerns about stability and soundness and unifying acceleration techniques across diffusion- and flow-based generators. A project page is available at https://yigu1008.github.io/SiD-DiT.