Perceive, Reflect and Understand Long Video: Progressive Multi-Granular Clue Exploration with Interactive Agents
作者: Jiahua Li, Kun Wei, Zhe Xu, Zibo Su, Xu Yang, Cheng Deng
分类: cs.CV
发布日期: 2025-09-29
💡 一句话要点
CogniGPT:交互式多粒度线索探索框架,用于高效长视频理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 多粒度感知 交互式代理 视觉认知 大型语言模型
📋 核心要点
- 现有长视频理解方法难以兼顾任务关键信息的完整性和效率,面临时间复杂性和信息稀疏性的挑战。
- CogniGPT通过多粒度感知代理和验证增强反射代理的交互循环,模拟人类视觉认知过程,高效探索任务相关线索。
- 实验表明,CogniGPT在多个数据集上超越现有方法,在EgoSchema上仅用少量帧就达到与Gemini 1.5-Pro相当的性能。
📝 摘要(中文)
长视频由于其时间复杂性和稀疏的任务相关信息,对AI系统提出了巨大的推理挑战。尽管各种基于大型语言模型(LLM)的方法在长视频理解方面取得了进展,但它们在捕获任务关键信息的完整性和效率方面仍然存在困难。受人类渐进式视觉认知的启发,我们提出了CogniGPT,一个利用多粒度感知代理(MGPA)和验证增强反射代理(VERA)之间的交互循环的框架,用于高效和可靠的长视频理解。具体来说,MGPA模仿人类视觉的发散和聚焦注意力来捕获任务相关信息,而VERA验证感知到的关键线索,以减轻幻觉并优化后续的感知策略。通过这种交互过程,CogniGPT探索最少数量的信息丰富且可靠的任务相关线索。在EgoSchema、Video-MME、NExT-QA和MovieChat数据集上的大量实验表明,CogniGPT在准确性和效率方面都具有优越性。值得注意的是,在EgoSchema上,它仅使用11.2帧就超越了现有的免训练方法,并达到了与Gemini 1.5-Pro相当的性能。
🔬 方法详解
问题定义:长视频理解任务面临时间跨度大、信息冗余和任务相关信息稀疏的挑战。现有基于LLM的方法虽然取得一定进展,但在效率和准确性上仍有不足,难以在有限的计算资源下提取关键信息,容易产生幻觉,影响理解的可靠性。
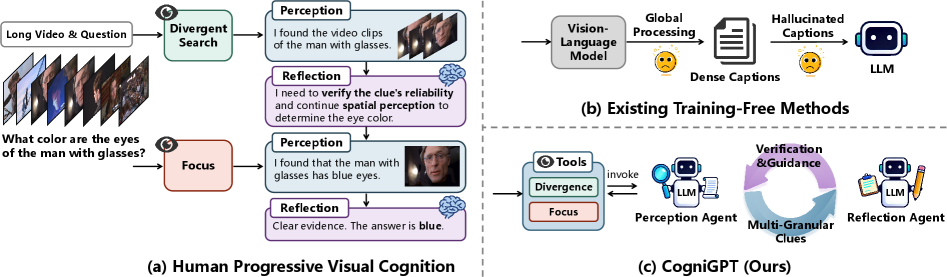
核心思路:受人类视觉认知过程的启发,CogniGPT的核心思路是通过模拟人类的渐进式视觉认知,采用交互式的探索方式,逐步聚焦于任务相关的关键线索。通过多粒度感知和验证反射,减少冗余信息的干扰,提高信息提取的效率和准确性。
技术框架:CogniGPT框架包含两个主要模块:多粒度感知代理(MGPA)和验证增强反射代理(VERA)。MGPA负责从视频中提取不同粒度的信息,模拟人类视觉的发散和聚焦注意力。VERA则负责验证MGPA提取的关键线索,通过反思和推理,纠正错误信息,并指导MGPA进行下一轮的感知。这两个模块通过交互循环,逐步提炼出最相关的任务信息。
关键创新:CogniGPT的关键创新在于其交互式的探索方式和多粒度的感知策略。与传统的单向信息处理流程不同,CogniGPT通过MGPA和VERA之间的反馈循环,实现了信息的动态调整和优化。多粒度的感知策略允许模型从不同层次的信息中提取线索,从而更全面地理解视频内容。
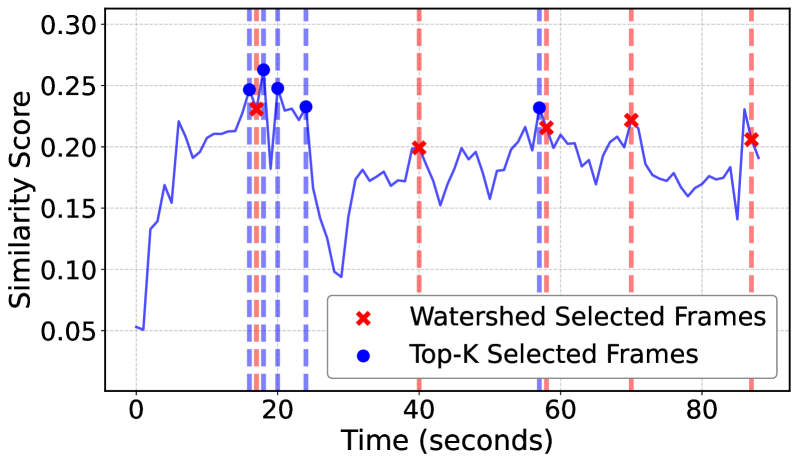
关键设计:MGPA采用多层感知器(MLP)或Transformer等模型,从视频帧中提取视觉特征。VERA则使用大型语言模型(LLM)进行推理和验证,判断MGPA提取的线索是否可靠。损失函数的设计旨在鼓励MGPA提取更准确、更相关的线索,并促使VERA进行更有效的验证和反思。具体的参数设置和网络结构根据不同的任务和数据集进行调整。
🖼️ 关键图片

📊 实验亮点
CogniGPT在EgoSchema、Video-MME、NExT-QA和MovieChat等多个长视频理解数据集上进行了评估,实验结果表明,CogniGPT在准确性和效率方面均优于现有方法。特别是在EgoSchema数据集上,CogniGPT仅使用11.2帧就超越了现有的免训练方法,并达到了与Gemini 1.5-Pro相当的性能,证明了其在长视频理解方面的强大能力。
🎯 应用场景
CogniGPT在长视频理解方面具有广泛的应用前景,例如智能监控、视频内容分析、自动驾驶、教育视频理解等。该研究可以帮助AI系统更有效地理解和利用长视频中的信息,提高决策的准确性和效率,并为未来的视频智能应用提供新的思路。
📄 摘要(原文)
Long videos, characterized by temporal complexity and sparse task-relevant information, pose significant reasoning challenges for AI systems. Although various Large Language Model (LLM)-based approaches have advanced long video understanding, they still struggle to achieve both completeness and efficiency in capturing task-critical information. Inspired by human progressive visual cognition, we propose CogniGPT, a framework that leverages an interactive loop between Multi-Granular Perception Agent (MGPA) and Verification-Enhanced Reflection Agent (VERA) for efficient and reliable long video understanding. Specifically, MGPA mimics human visual divergent and focused attention to capture task-related information, while VERA verifies perceived key clues to mitigate hallucination and optimize subsequent perception strategies. Through this interactive process, CogniGPT explores a minimal set of informative and reliable task-related clues. Extensive experiments on EgoSchema, Video-MME, NExT-QA, and MovieChat datasets demonstrate CogniGPT's superiority in both accuracy and efficiency. Notably, on EgoSchema, it surpasses existing training-free methods using only 11.2 frames and achieves performance comparable to Gemini 1.5-Pro.