Training-Free Token Pruning via Zeroth-Order Gradient Estimation in Vision-Language Models
作者: Youngeun Kim, Youjia Zhang, Huiling Liu, Aecheon Jung, Sunwoo Lee, Sungeun Hong
分类: cs.CV
发布日期: 2025-09-29
💡 一句话要点
提出无训练的令牌剪枝方法以降低视觉语言模型的推理成本
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 令牌剪枝 零阶扰动 多模态推理 推理效率 敏感度估计 深度学习
📋 核心要点
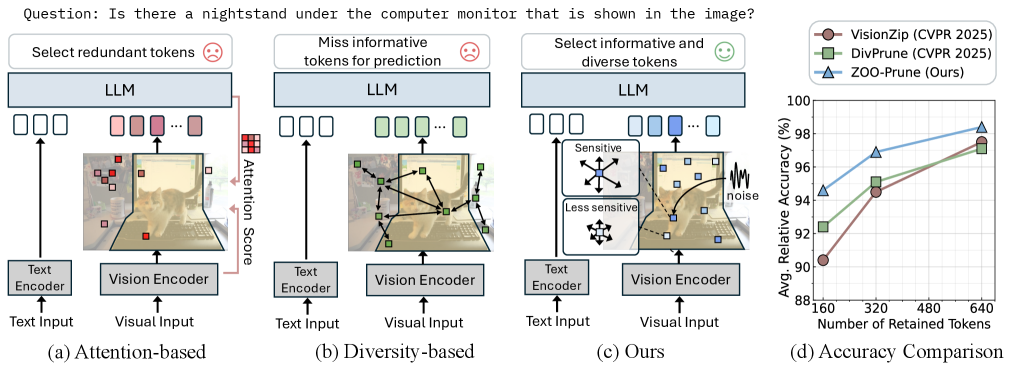
- 现有的令牌剪枝方法在稳定性和准确性上存在不足,导致冗余选择和重要信息丢失。
- 本文提出了一种基于零阶扰动的敏感度估计方法,旨在无训练地选择对模型输出影响较大的令牌。
- 实验结果显示,该方法在剪枝率和推理效率上显著优于现有技术,提升了模型的整体性能。
📝 摘要(中文)
大型视觉语言模型(VLMs)在多模态推理中表现出色,但由于冗余视觉令牌,推理成本较高。现有的剪枝方法存在局限性,基于注意力的方法依赖不稳定的注意力分数,而基于多样性的方法可能会丢失重要信息。本文提出了一种无训练的框架,基于简单的直觉:敏感度高的令牌更可能影响模型输出,并应捕捉互补的视觉线索。通过在投影层使用零阶扰动估计令牌敏感度,本文的方法在不进行反向传播的情况下,通过轻量级的前向传递来近似每个令牌的影响。实验表明,该方法在多个VLM和基准测试中表现优异,剪枝率高达94.4%,同时保持准确性,推理速度提升至基线的2.30倍。
🔬 方法详解
问题定义:本文旨在解决大型视觉语言模型中冗余视觉令牌导致的高推理成本问题。现有方法在稳定性和准确性上存在不足,可能导致重要信息的丢失。
核心思路:提出了一种无训练的令牌剪枝框架,基于令牌的敏感度来选择对模型输出影响较大的令牌。通过零阶扰动估计,能够在不进行反向传播的情况下评估令牌的影响。
技术框架:整体流程包括在投影层施加小的随机扰动,观察其对输出的影响,从而估计每个令牌的敏感度。该方法依赖于轻量级的前向传递,避免了复杂的训练过程。
关键创新:最重要的创新在于使用零阶扰动来估计令牌敏感度,这一方法与传统的基于注意力或多样性的方法有本质区别,能够更有效地选择互补信息而非冗余信息。
关键设计:在参数设置上,采用了简单的扰动策略,损失函数设计为关注输出变化的敏感度,网络结构则聚焦于投影层的轻量化设计,以提高计算效率。
🖼️ 关键图片


📊 实验亮点
实验结果表明,本文提出的方法在多个视觉语言模型上均表现优异,剪枝率高达94.4%,同时保持模型的准确性,推理速度相比基线提升至2.30倍,显著提高了推理效率。
🎯 应用场景
该研究的潜在应用领域包括图像与文本的多模态理解、智能搜索引擎、自动图像标注等。通过降低推理成本,能够在资源受限的环境中实现更高效的模型部署,推动相关技术的实际应用和发展。
📄 摘要(原文)
Large Vision-Language Models (VLMs) enable strong multimodal reasoning but incur heavy inference costs from redundant visual tokens. Token pruning alleviates this issue, yet existing approaches face limitations. Attention-based methods rely on raw attention scores, which are often unstable across layers and heads and can lead to redundant selections. Diversity-based methods improve robustness by selecting tokens far apart in feature space but risk dropping regions needed for accurate prediction. We propose \ours, a training-free framework built on a simple intuition: tokens with higher sensitivity are more likely to influence the model's output, and they should also capture complementary visual cues rather than overlapping information. To achieve this, we estimate token sensitivity using zeroth-order perturbations at the projection layer, a shallow and computationally light component of the model. This approach measures how small random perturbations affect the projection outputs, allowing us to approximate each token's influence through lightweight forward passes without backpropagation. Extensive experiments across multiple VLMs and benchmarks show that \ours consistently outperforms prior methods, pruning up to 94.4\% of tokens while maintaining accuracy and significantly improving efficiency, achieving up to 2.30x faster end-to-end inference over the baseline.