Vision Function Layer in Multimodal LLMs
作者: Cheng Shi, Yizhou Yu, Sibei Yang
分类: cs.CV
发布日期: 2025-09-29
备注: Accepted at NeurIPS 2025 (preview; camera-ready in preparation)
💡 一句话要点
揭示多模态LLM视觉功能层,实现高效可定制模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 视觉功能层 模型定制 数据选择
📋 核心要点
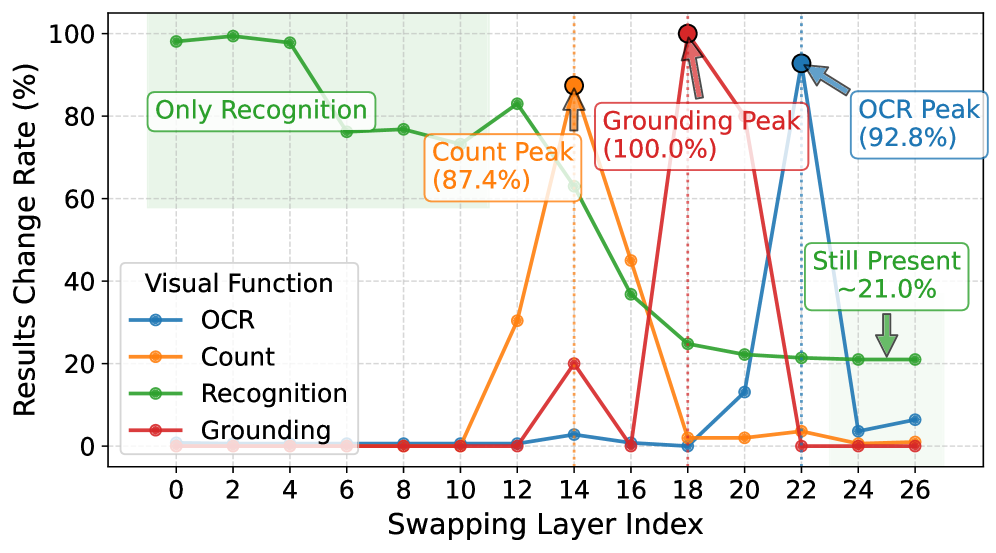
- 现有MLLM视觉功能分散在不同层,缺乏针对性优化方法。
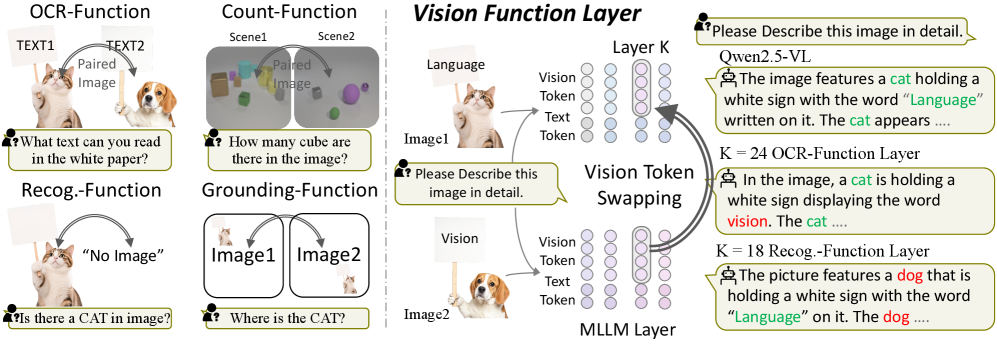
- 提出视觉功能层(VFL)概念,通过视觉Token交换分析层级功能。
- VFL-LoRA和VFL-select方法在模型定制和数据选择上表现出色。
📝 摘要(中文)
本研究发现多模态大型语言模型(MLLM)中与视觉相关的功能解码分布在不同的解码器层中。通常,计数、定位或OCR识别等每个功能都集中在两到三层,我们将其定义为视觉功能层(VFL)。此外,不同VFL的深度及其顺序在不同的MLLM中表现出一致的模式,这与人类行为非常吻合(例如,首先进行识别,然后进行计数,最后进行定位)。这些发现源于视觉Token交换,这是一种新颖的分析框架,它修改目标KV缓存条目,以精确地阐明解码期间的特定层功能。此外,这些见解为定制MLLM以适应实际下游应用提供了巨大的效用。例如,当LoRA训练选择性地应用于其功能与训练数据对齐的VFL时,VFL-LoRA不仅优于full-LoRA,而且还可以防止领域外功能遗忘。此外,通过分析消融特定VFL时训练数据的性能差异,VFL-select自动按功能对数据进行分类,从而实现高效的数据选择,以直接增强相应的功能。因此,VFL-select在数据选择方面超越了人类专家,并且仅使用原始数据集的20%即可达到完整数据性能的98%。这项研究提供了对MLLM视觉处理的更深入理解,从而促进了更高效,可解释和鲁棒的模型的创建。
🔬 方法详解
问题定义:现有的多模态大型语言模型(MLLMs)在处理视觉信息时,其功能解码过程分散在不同的网络层中,缺乏对特定视觉功能的精细控制和优化手段。这导致模型在特定任务上效率低下,且容易发生领域外功能遗忘的问题。因此,如何理解和利用MLLM中不同层级的视觉功能,成为了一个亟待解决的问题。
核心思路:本论文的核心思路是识别并分离MLLM中负责特定视觉功能的网络层,即“视觉功能层”(Vision Function Layers, VFLs)。通过分析这些VFLs,可以更深入地理解MLLM的视觉处理机制,并针对性地进行模型优化和数据选择。这种思路类似于对神经网络进行手术,精准地操作特定功能模块,从而提高模型的效率和性能。
技术框架:该研究提出了一个名为“视觉Token交换”(Visual Token Swapping)的分析框架。该框架通过修改目标KV缓存条目,来精确地阐明解码过程中特定层的功能。通过分析不同层对视觉Token的响应,可以确定负责特定视觉功能的VFLs。此外,该研究还提出了两种基于VFLs的应用方法:VFL-LoRA和VFL-select。VFL-LoRA通过选择性地对VFLs进行LoRA训练,来提高模型在特定任务上的性能,并防止领域外功能遗忘。VFL-select则通过分析消融特定VFL时训练数据的性能差异,来自动按功能对数据进行分类,从而实现高效的数据选择。
关键创新:该研究最重要的技术创新点在于提出了“视觉功能层”(VFL)的概念,并开发了“视觉Token交换”(Visual Token Swapping)分析框架。VFL的概念打破了以往将MLLM视为黑盒的观点,揭示了其内部视觉功能的组织结构。视觉Token交换框架则提供了一种有效的方法来识别和分析这些VFLs。与现有方法相比,该研究能够更精细地理解MLLM的视觉处理机制,并针对性地进行模型优化和数据选择。
关键设计:在VFL-LoRA中,关键的设计在于如何选择需要进行LoRA训练的VFLs。该研究通过分析训练数据与不同VFLs的功能对齐程度,来选择最相关的VFLs。在VFL-select中,关键的设计在于如何定义消融特定VFL时训练数据的性能差异。该研究通过计算消融前后模型在训练数据上的损失差异,来衡量VFL对特定功能的贡献程度。
🖼️ 关键图片
📊 实验亮点
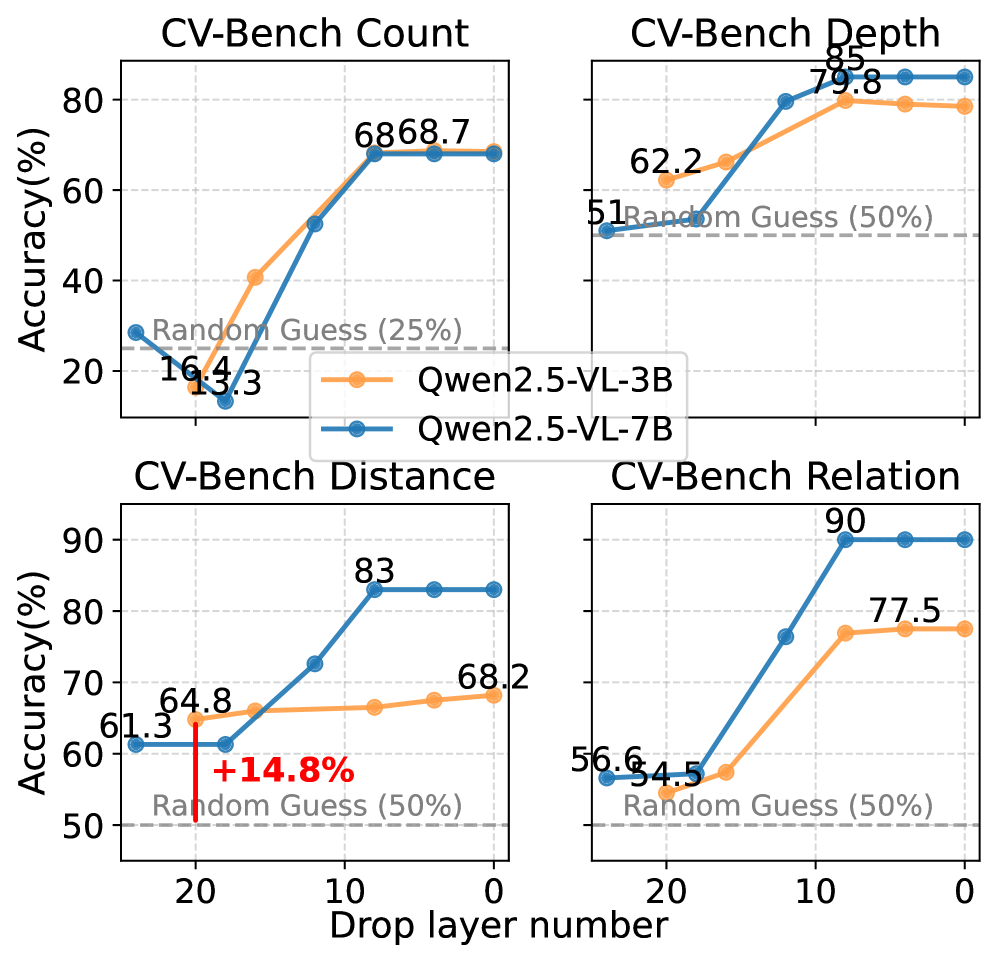
实验结果表明,VFL-LoRA在特定任务上优于full-LoRA,并能有效防止领域外功能遗忘。VFL-select在数据选择方面超越了人类专家,并且仅使用原始数据集的20%即可达到完整数据性能的98%。这些结果证明了VFL概念和相关方法的有效性。
🎯 应用场景
该研究成果可应用于各种需要多模态理解的场景,如智能客服、自动驾驶、医疗诊断等。通过定制MLLM的视觉功能层,可以提高模型在特定任务上的性能和效率。此外,VFL-select方法可以用于数据挖掘和数据增强,从而提高模型的鲁棒性和泛化能力。未来,该研究有望推动多模态人工智能技术的发展,并为实际应用带来更大的价值。
📄 摘要(原文)
This study identifies that visual-related functional decoding is distributed across different decoder layers in Multimodal Large Language Models (MLLMs). Typically, each function, such as counting, grounding, or OCR recognition, narrows down to two or three layers, which we define as Vision Function Layers (VFL). Additionally, the depth and its order of different VFLs exhibits a consistent pattern across different MLLMs, which is well-aligned with human behaviors (e.g., recognition occurs first, followed by counting, and then grounding). These findings are derived from Visual Token Swapping, our novel analytical framework that modifies targeted KV cache entries to precisely elucidate layer-specific functions during decoding. Furthermore, these insights offer substantial utility in tailoring MLLMs for real-world downstream applications. For instance, when LoRA training is selectively applied to VFLs whose functions align with the training data, VFL-LoRA not only outperform full-LoRA but also prevent out-of-domain function forgetting. Moreover, by analyzing the performance differential on training data when particular VFLs are ablated, VFL-select automatically classifies data by function, enabling highly efficient data selection to directly bolster corresponding capabilities. Consequently, VFL-select surpasses human experts in data selection, and achieves 98% of full-data performance with only 20% of the original dataset. This study delivers deeper comprehension of MLLM visual processing, fostering the creation of more efficient, interpretable, and robust models.