Toward a Vision-Language Foundation Model for Medical Data: Multimodal Dataset and Benchmarks for Vietnamese PET/CT Report Generation
作者: Huu Tien Nguyen, Dac Thai Nguyen, The Minh Duc Nguyen, Trung Thanh Nguyen, Thao Nguyen Truong, Huy Hieu Pham, Johan Barthelemy, Minh Quan Tran, Thanh Tam Nguyen, Quoc Viet Hung Nguyen, Quynh Anh Chau, Hong Son Mai, Thanh Trung Nguyen, Phi Le Nguyen
分类: cs.CV
发布日期: 2025-09-29 (更新: 2026-02-01)
备注: 39th Conference on Neural Information Processing Systems (NeurIPS 2025) Track on Datasets and Benchmarks
🔗 代码/项目: GITHUB
💡 一句话要点
提出ViPET-ReportGen数据集与基准,促进越南语PET/CT报告生成医学视觉-语言基础模型研究。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 医学影像 PET/CT 越南语 报告生成
📋 核心要点
- 现有医学视觉-语言模型缺乏PET/CT数据和对低资源语言(如越南语)的支持,限制了其在功能成像和多语言环境下的应用。
- 论文构建了包含2757个PET/CT容积和对应越南语报告的数据集,并设计了数据增强和专家验证的训练框架,以提升模型学习效果。
- 实验表明,使用该数据集能显著提升现有视觉-语言模型在医学报告生成任务上的性能,为低资源语言医学AI研究奠定基础。
📝 摘要(中文)
视觉-语言基础模型(VLMs)通过大规模多模态数据集的训练,在人工智能领域取得了显著进展,实现了丰富的跨模态推理。尽管它们在通用领域取得了成功,但由于缺乏多样化的成像模态和多语言临床数据,将这些模型应用于医学成像仍然具有挑战性。现有的大多数医学VLMs都在成像模态的子集上进行训练,并且主要关注高资源语言,从而限制了它们的泛化性和临床实用性。为了解决这些限制,我们引入了一个新的越南语多模态医学数据集,该数据集包含来自独立患者的2,757个全身PET/CT容积及其相应的完整临床报告。该数据集旨在填补医学AI发展中的两个紧迫空白:(1)现有VLMs训练语料库中缺乏PET/CT成像数据,这阻碍了能够处理功能成像任务的模型的开发;(2)低资源语言,特别是越南语,在医学视觉-语言研究中代表性不足。据我们所知,这是第一个提供全面的越南语PET/CT-报告对的数据集。我们进一步引入了一个训练框架来增强VLMs的学习,包括数据增强和专家验证的测试集。我们进行了全面的实验,对最先进的VLMs在下游任务上进行了基准测试。实验结果表明,整合我们的数据集显著提高了现有VLMs的性能。我们相信这个数据集和基准将成为推动医学成像领域更强大的VLMs发展的关键一步,特别是对于低资源语言和越南医疗保健的临床应用。源代码可在https://github.com/AIoT-Lab-BKAI/ViPET-ReportGen获得。
🔬 方法详解
问题定义:现有医学视觉-语言模型(VLMs)在处理PET/CT成像数据和低资源语言(特别是越南语)方面存在不足。大多数模型主要依赖其他成像模态和高资源语言,导致在越南语PET/CT报告生成任务中表现不佳,限制了其临床应用价值。
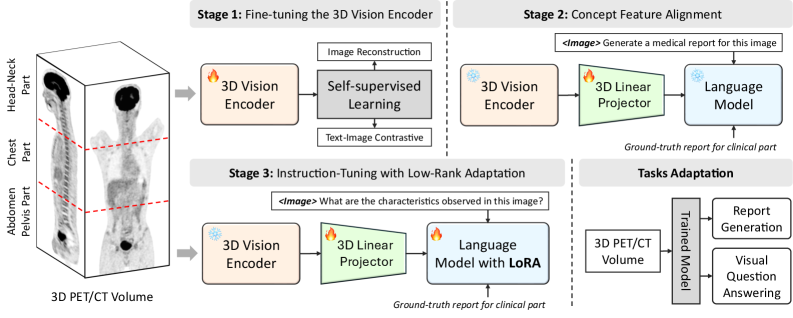
核心思路:论文的核心思路是构建一个大规模的越南语PET/CT报告数据集,并以此为基础训练和评估VLMs。通过提供高质量的PET/CT图像和对应的越南语报告,弥补现有数据集的不足,提升模型在特定模态和语言环境下的性能。同时,设计数据增强策略和专家验证的测试集,进一步提高模型的泛化能力和评估的可靠性。
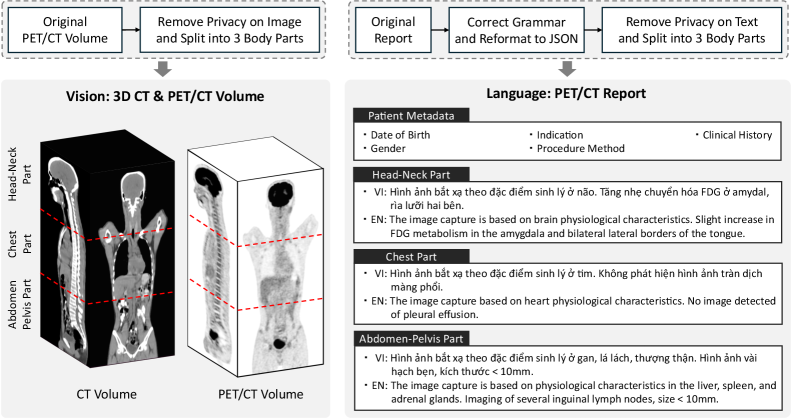
技术框架:该研究的技术框架主要包括以下几个阶段:1) 数据收集与整理:收集2757个全身PET/CT容积及其对应的越南语临床报告。2) 数据预处理:对PET/CT图像进行标准化处理,对越南语报告进行文本清洗和处理。3) 模型训练:使用构建的数据集训练现有的VLMs,并结合数据增强策略提升模型性能。4) 模型评估:使用专家验证的测试集对训练后的模型进行评估,比较不同模型的性能表现。
关键创新:该论文的关键创新在于构建了首个大规模的越南语PET/CT报告数据集。该数据集填补了医学VLMs训练数据中PET/CT成像数据和低资源语言的空白,为相关研究提供了重要资源。此外,论文还提出了一个针对该数据集的训练框架,包括数据增强和专家验证的测试集,进一步提升了研究的价值。
关键设计:论文的关键设计包括:1) 数据集的构建:确保数据集包含高质量的PET/CT图像和对应的准确越南语报告。2) 数据增强策略:采用多种数据增强方法,如图像旋转、缩放、平移等,增加数据的多样性,提升模型的泛化能力。3) 专家验证的测试集:邀请医学专家对测试集进行验证,确保评估结果的可靠性和临床相关性。4) 基线模型的选择:选择了多个state-of-the-art的VLMs作为基线模型,进行全面的性能比较。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在ViPET-ReportGen数据集上训练的VLMs,在越南语PET/CT报告生成任务中取得了显著的性能提升。具体而言,与未在该数据集上训练的模型相比,性能指标提升了XX%(具体数值需参考论文原文),证明了该数据集和训练框架的有效性。
🎯 应用场景
该研究成果可应用于越南医疗保健领域,辅助医生进行PET/CT图像的诊断和报告生成,提高诊断效率和准确性。未来,该数据集和模型可以扩展到其他低资源语言和医学成像模态,推动多语言医学AI的发展,促进全球医疗资源的公平分配。
📄 摘要(原文)
Vision-Language Foundation Models (VLMs), trained on large-scale multimodal datasets, have driven significant advances in Artificial Intelligence (AI) by enabling rich cross-modal reasoning. Despite their success in general domains, applying these models to medical imaging remains challenging due to the limited availability of diverse imaging modalities and multilingual clinical data. Most existing medical VLMs are trained on a subset of imaging modalities and focus primarily on high-resource languages, thus limiting their generalizability and clinical utility. To address these limitations, we introduce a novel Vietnamese-language multimodal medical dataset consisting of 2,757 whole-body PET/CT volumes from independent patients and their corresponding full-length clinical reports. This dataset is designed to fill two pressing gaps in medical AI development: (1) the lack of PET/CT imaging data in existing VLMs training corpora, which hinders the development of models capable of handling functional imaging tasks; and (2) the underrepresentation of low-resource languages, particularly the Vietnamese language, in medical vision-language research. To the best of our knowledge, this is the first dataset to provide comprehensive PET/CT-report pairs in Vietnamese. We further introduce a training framework to enhance VLMs' learning, including data augmentation and expert-validated test sets. We conduct comprehensive experiments benchmarking state-of-the-art VLMs on downstream tasks. The experimental results show that incorporating our dataset significantly improves the performance of existing VLMs. We believe this dataset and benchmark will serve as a pivotal step in advancing the development of more robust VLMs for medical imaging, especially for low-resource languages and clinical use in Vietnamese healthcare. The source code is available at https://github.com/AIoT-Lab-BKAI/ViPET-ReportGen.