SCOPE: Semantic Conditioning for Sim2Real Category-Level Object Pose Estimation in Robotics
作者: Peter Hönig, Stefan Thalhammer, Jean-Baptiste Weibel, Matthias Hirschmanner, Markus Vincze
分类: cs.CV, cs.RO
发布日期: 2025-09-29
🔗 代码/项目: GITHUB
💡 一句话要点
SCOPE:利用语义条件进行Sim2Real机器人类别级物体姿态估计
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 物体姿态估计 类别级估计 Sim2Real 扩散模型 语义条件 机器人操作 DINOv2
📋 核心要点
- 现有物体操作方法需要精确的物体姿态估计,但在开放环境中,机器人会遇到未知物体,需要语义理解才能泛化到已知类别之外。
- SCOPE利用DINOv2特征作为连续语义先验,消除了对离散类别标签的需求,并结合逼真的训练数据和点法线的噪声模型,缩小Sim2Real差距。
- SCOPE在合成训练的类别级物体姿态估计中,优于当前最先进水平,在5°5cm指标上实现了31.9%的相对改进,并能成功抓取未知类别的物体。
📝 摘要(中文)
本文提出SCOPE,一种基于扩散模型的类别级物体姿态估计模型,通过利用DINOv2特征作为连续语义先验,消除了对离散类别标签的需求。结合逼真的训练数据和点法线的噪声模型,SCOPE缩小了类别级物体姿态估计中的Sim2Real差距。通过交叉注意力注入连续语义先验,SCOPE能够学习超越已知类别分布的物体实例的规范化物体坐标系。在合成训练的类别级物体姿态估计中,SCOPE优于当前最先进水平,在5°5cm指标上实现了31.9%的相对改进。在两个实例级数据集上的额外实验表明,该模型能够泛化到已知物体类别之外,从而能够以高达100%的成功率抓取未知类别的未见物体。
🔬 方法详解
问题定义:论文旨在解决机器人操作中,对未知类别物体的类别级姿态估计问题。现有方法通常依赖于离散的类别标签,限制了模型对新物体的泛化能力,并且存在Sim2Real的差距,导致在真实环境中性能下降。
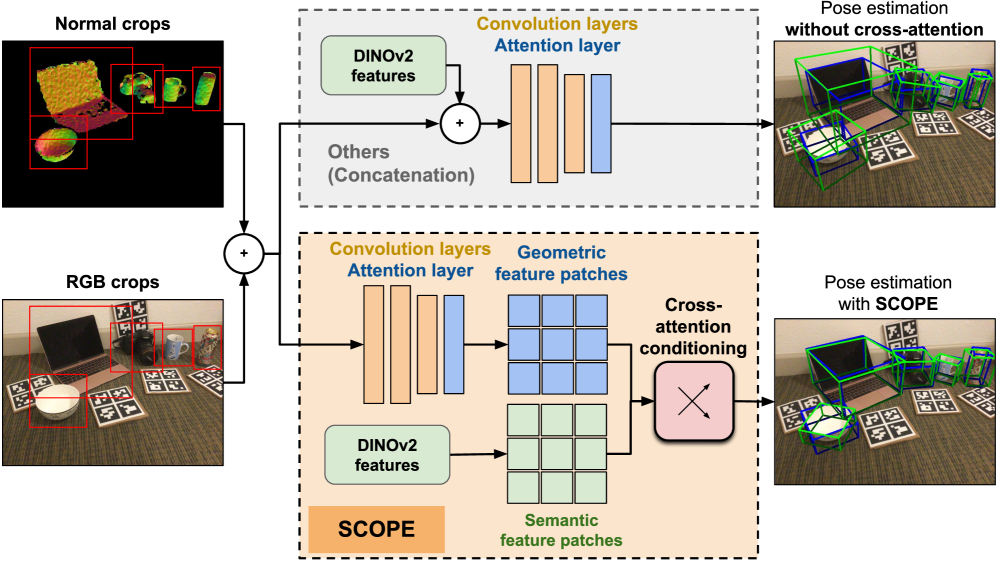
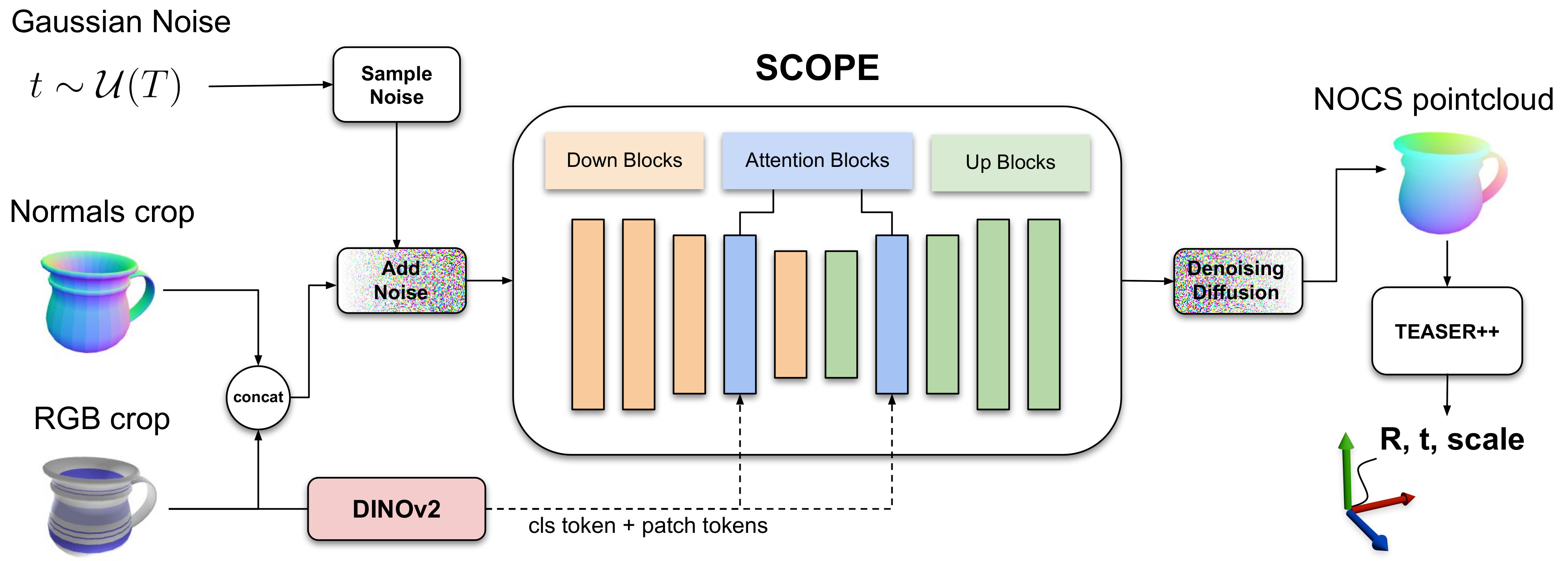
核心思路:论文的核心思路是利用DINOv2提取的连续语义特征作为先验知识,取代传统的离散类别标签。通过将语义信息融入到扩散模型中,使模型能够学习到物体之间的相似性,从而实现对未知物体的姿态估计。
技术框架:SCOPE的整体框架包含以下几个主要模块:1) 使用DINOv2提取输入点云的语义特征;2) 将语义特征通过交叉注意力机制注入到扩散模型中,引导扩散过程;3) 使用逼真的合成数据进行训练,并加入点法线的噪声模型,以减小Sim2Real差距;4) 通过扩散模型的逆过程,从噪声中生成物体的姿态估计。
关键创新:最重要的技术创新点在于使用连续的语义特征作为条件,取代了传统的离散类别标签。这种方法使得模型能够学习到物体之间的连续关系,从而实现对未知物体的泛化。此外,通过交叉注意力机制将语义信息注入到扩散模型中,能够更好地引导扩散过程,提高姿态估计的准确性。
关键设计:论文的关键设计包括:1) 使用DINOv2作为特征提取器,获取高质量的语义特征;2) 设计交叉注意力模块,将语义特征融入到扩散模型的每一步;3) 使用逼真的合成数据进行训练,并加入点法线的噪声模型,以模拟真实环境中的噪声;4) 使用5°5cm作为评估指标,衡量姿态估计的准确性。
🖼️ 关键图片

📊 实验亮点
SCOPE在合成训练的类别级物体姿态估计中,取得了显著的性能提升,在5°5cm指标上实现了31.9%的相对改进,超越了当前最先进水平。此外,在两个实例级数据集上的实验表明,SCOPE能够泛化到未知物体类别,并以高达100%的成功率抓取未知类别的物体,展示了其强大的泛化能力。
🎯 应用场景
该研究成果可应用于机器人操作、自动驾驶、增强现实等领域。在机器人操作中,可以使机器人能够抓取和操作未知物体,提高机器人的智能化水平。在自动驾驶中,可以用于识别和定位道路上的各种物体,提高自动驾驶的安全性。在增强现实中,可以用于将虚拟物体与真实场景进行精确对齐,提高用户体验。
📄 摘要(原文)
Object manipulation requires accurate object pose estimation. In open environments, robots encounter unknown objects, which requires semantic understanding in order to generalize both to known categories and beyond. To resolve this challenge, we present SCOPE, a diffusion-based category-level object pose estimation model that eliminates the need for discrete category labels by leveraging DINOv2 features as continuous semantic priors. By combining these DINOv2 features with photorealistic training data and a noise model for point normals, we reduce the Sim2Real gap in category-level object pose estimation. Furthermore, injecting the continuous semantic priors via cross-attention enables SCOPE to learn canonicalized object coordinate systems across object instances beyond the distribution of known categories. SCOPE outperforms the current state of the art in synthetically trained category-level object pose estimation, achieving a relative improvement of 31.9\% on the 5$^\circ$5cm metric. Additional experiments on two instance-level datasets demonstrate generalization beyond known object categories, enabling grasping of unseen objects from unknown categories with a success rate of up to 100\%. Code available: https://github.com/hoenigpeter/scope.