CORE-3D: Context-aware Open-vocabulary Retrieval by Embeddings in 3D
作者: Mohamad Amin Mirzaei, Pantea Amoie, Ali Ekhterachian, Matin Mirzababaei, Babak Khalaj
分类: cs.CV, cs.AI
发布日期: 2025-09-29 (更新: 2025-12-07)
备注: Submitted for ICLR 2026 conference
💡 一句话要点
CORE-3D:通过3D嵌入和上下文感知实现开放词汇检索
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景理解 开放词汇检索 语义分割 视觉语言模型 上下文感知 SemanticSAM
📋 核心要点
- 现有方法在3D语义映射中存在掩码碎片化和语义分配不准确的问题,限制了其在复杂环境中的应用。
- 论文提出CORE-3D,利用SemanticSAM生成更精确的对象级掩码,并采用上下文感知的CLIP编码策略增强语义信息。
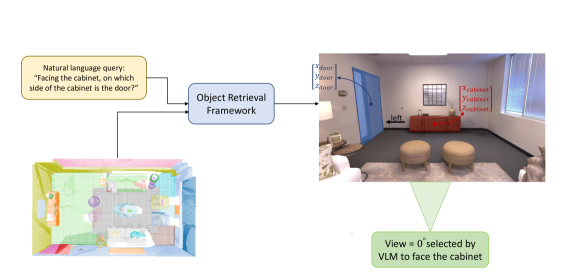
- 实验结果表明,CORE-3D在3D语义分割和基于语言查询的对象检索任务上,显著优于现有方法。
📝 摘要(中文)
3D场景理解对于具身智能和机器人至关重要,它支持可靠的交互和导航感知。最近的方法通过将嵌入向量分配给视觉-语言模型(VLM)生成的2D类别无关掩码,并将这些掩码投影到3D空间中,实现了零样本、开放词汇的3D语义映射。然而,由于直接使用原始掩码,这些方法通常会产生碎片化的掩码和不准确的语义分配,从而限制了它们在复杂环境中的有效性。为了解决这个问题,我们利用SemanticSAM进行渐进式粒度细化,以生成更准确和更多的对象级掩码,从而减轻了诸如vanilla SAM等掩码生成模型中常见的过度分割现象,并改善了下游的3D语义分割。为了进一步增强语义上下文,我们采用了一种上下文感知的CLIP编码策略,该策略使用经验确定的权重整合每个掩码的多个上下文视图,从而提供更丰富的视觉上下文。我们在多个3D场景理解任务(包括3D语义分割和基于语言查询的对象检索)以及多个基准数据集上评估了我们的方法。实验结果表明,与现有方法相比,我们的方法有了显著的改进,突出了我们方法的有效性。
🔬 方法详解
问题定义:论文旨在解决3D场景理解中,现有方法由于掩码质量不高和缺乏上下文信息,导致语义分割和对象检索性能不佳的问题。现有方法直接使用视觉-语言模型生成的原始掩码,容易产生碎片化和不准确的语义分配,尤其是在复杂环境中,这严重限制了3D场景理解的准确性和可靠性。
核心思路:论文的核心思路是通过改进掩码生成和语义编码两个方面来提升3D场景理解的性能。首先,利用SemanticSAM生成更准确的对象级掩码,减少过度分割。其次,采用上下文感知的CLIP编码策略,整合多个上下文视图,提供更丰富的视觉上下文信息。
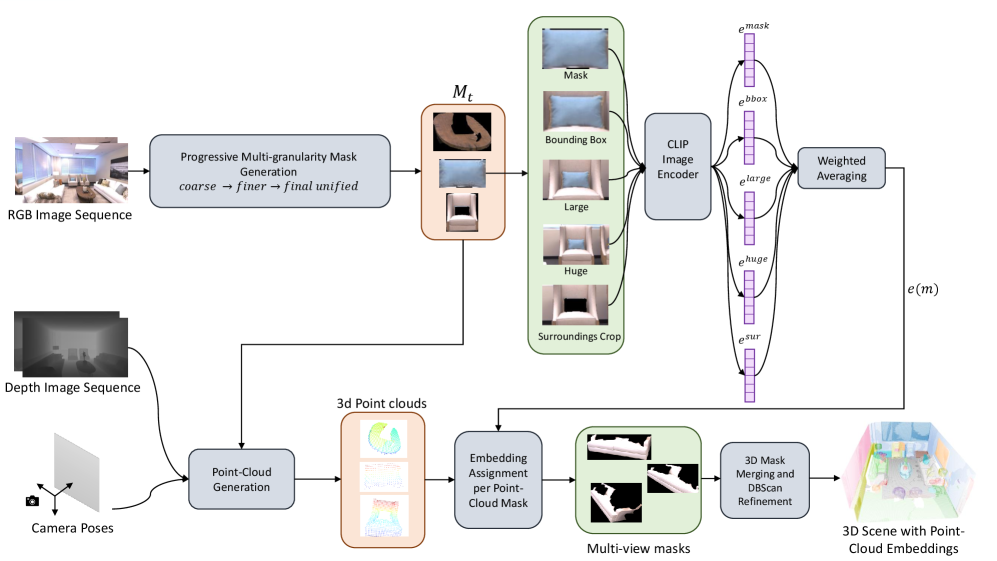
技术框架:CORE-3D的整体框架包含以下几个主要阶段:1) 使用SemanticSAM进行渐进式粒度细化,生成高质量的对象级掩码;2) 对每个掩码提取多个上下文视图;3) 使用上下文感知的CLIP编码策略,整合多个上下文视图的特征,生成最终的语义嵌入;4) 将2D掩码投影到3D空间,并进行3D语义分割和对象检索。
关键创新:论文的关键创新在于:1) 利用SemanticSAM生成更准确的对象级掩码,有效缓解了过度分割问题;2) 提出了上下文感知的CLIP编码策略,通过整合多个上下文视图,显著增强了语义信息的丰富度。这种上下文感知的设计使得模型能够更好地理解场景中的对象及其相互关系。
关键设计:在上下文感知的CLIP编码策略中,论文使用经验确定的权重来整合不同上下文视图的特征。具体的权重设置和视图选择策略在论文中进行了详细描述。此外,SemanticSAM的渐进式粒度细化过程也需要仔细调整参数,以获得最佳的掩码生成效果。损失函数的设计也至关重要,需要平衡不同任务之间的损失,以实现最佳的整体性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CORE-3D在3D语义分割和基于语言查询的对象检索任务上均取得了显著的提升。与现有方法相比,CORE-3D能够生成更准确的3D语义地图,并能够更准确地根据语言查询检索到目标对象。具体的性能提升数据在论文的实验部分进行了详细展示。
🎯 应用场景
该研究成果可广泛应用于机器人导航、增强现实、虚拟现实、自动驾驶等领域。通过提升3D场景理解的准确性和可靠性,可以使机器人更好地感知和理解周围环境,从而实现更智能的交互和导航。在AR/VR领域,可以提供更逼真的场景渲染和更自然的交互体验。在自动驾驶领域,可以提高车辆对周围环境的感知能力,从而提升驾驶安全性。
📄 摘要(原文)
3D scene understanding is fundamental for embodied AI and robotics, supporting reliable perception for interaction and navigation. Recent approaches achieve zero-shot, open-vocabulary 3D semantic mapping by assigning embedding vectors to 2D class-agnostic masks generated via vision-language models (VLMs) and projecting these into 3D. However, these methods often produce fragmented masks and inaccurate semantic assignments due to the direct use of raw masks, limiting their effectiveness in complex environments. To address this, we leverage SemanticSAM with progressive granularity refinement to generate more accurate and numerous object-level masks, mitigating the over-segmentation commonly observed in mask generation models such as vanilla SAM, and improving downstream 3D semantic segmentation. To further enhance semantic context, we employ a context-aware CLIP encoding strategy that integrates multiple contextual views of each mask using empirically determined weighting, providing much richer visual context. We evaluate our approach on multiple 3D scene understanding tasks, including 3D semantic segmentation and object retrieval from language queries, across several benchmark datasets. Experimental results demonstrate significant improvements over existing methods, highlighting the effectiveness of our approach.