Generalist Multi-Class Anomaly Detection via Distillation to Two Heterogeneous Student Networks
作者: Hangil Park, Yongmin Seo, Tae-Kyun Kim
分类: cs.CV
发布日期: 2025-09-29
💡 一句话要点
提出基于知识蒸馏的双异构学生网络,用于通用多类别异常检测。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 异常检测 知识蒸馏 双模型集成 通用异常检测 多类别异常检测
📋 核心要点
- 现有异常检测方法在工业和语义异常检测任务间泛化性差,且对数据集和单类别任务敏感。
- 提出双模型集成框架,利用知识蒸馏将教师模型的知识传递给两个异构学生模型,分别擅长局部和语义异常检测。
- 实验结果表明,该方法在多个数据集上,单类别和多类别设置下均达到SOTA,验证了其通用性和有效性。
📝 摘要(中文)
异常检测(AD)在各种实际应用中扮演着重要角色。然而,现有的AD方法通常偏向于工业检测,难以推广到更广泛的任务,如语义异常检测,反之亦然。尽管最近的方法试图解决通用异常检测问题,但它们的性能仍然对数据集特定的设置和单类别任务敏感。本文提出了一种基于知识蒸馏(KD)的双模型集成方法来弥合这一差距。我们的框架由一个教师模型和两个学生模型组成:一个擅长检测工业AD中patch级别微小缺陷的Encoder-Decoder模型和一个针对语义AD优化的Encoder-Encoder模型。两个模型都利用共享的预训练编码器(DINOv2)来提取高质量的特征表示。使用Noisy-OR目标联合学习双模型,并通过各自模型导出的局部和语义异常分数,使用联合概率获得最终的异常分数。我们在单类别和多类别设置下的八个公共基准上评估了我们的方法:用于工业检测的MVTec-AD、MVTec-LOCO、VisA和Real-IAD,以及用于语义异常检测的CIFAR-10/100、FMNIST和View。所提出的方法在两个领域的多类别和单类别设置中都实现了最先进的精度,证明了在异常检测的多个领域中的泛化能力。我们的模型在MVTec-AD上实现了99.7%的图像级AUROC,在CIFAR-10上实现了97.8%的图像级AUROC,这明显优于之前的多类别设置中的通用AD模型,甚至高于单个基准上最好的专家模型。
🔬 方法详解
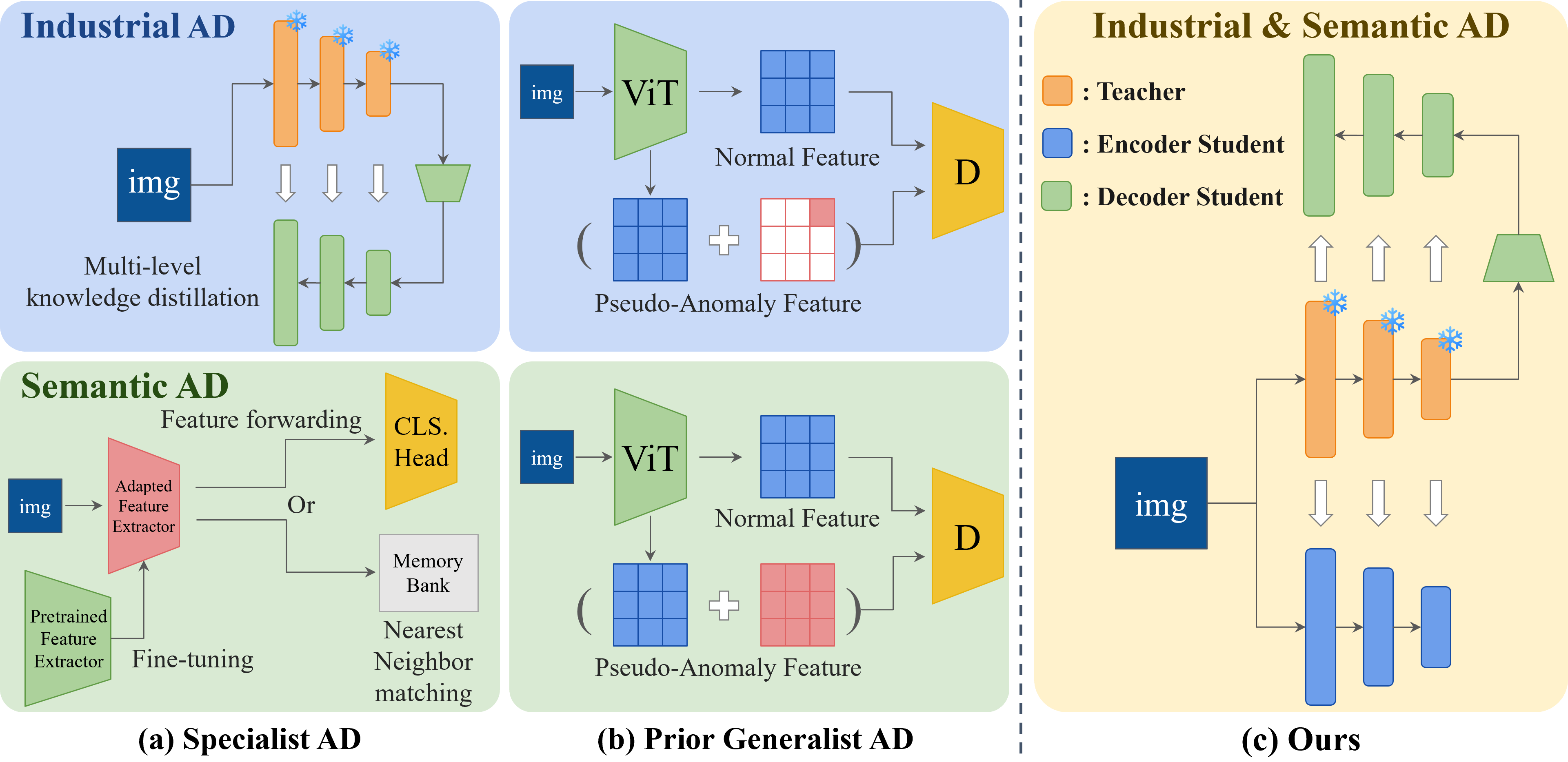
问题定义:现有异常检测方法通常针对特定领域(如工业检测或语义异常检测)进行优化,难以在不同领域之间泛化。此外,这些方法对数据集的特定设置和单类别任务表现敏感,限制了其在实际应用中的适用性。因此,需要一种能够处理多类别、跨领域的通用异常检测方法。
核心思路:论文的核心思路是利用知识蒸馏,将一个强大的教师模型的知识传递给两个专门设计的学生模型。这两个学生模型分别擅长不同类型的异常检测(局部缺陷和语义异常),从而实现更全面的异常检测能力。通过集成两个学生模型的输出,可以提高整体的泛化性能。
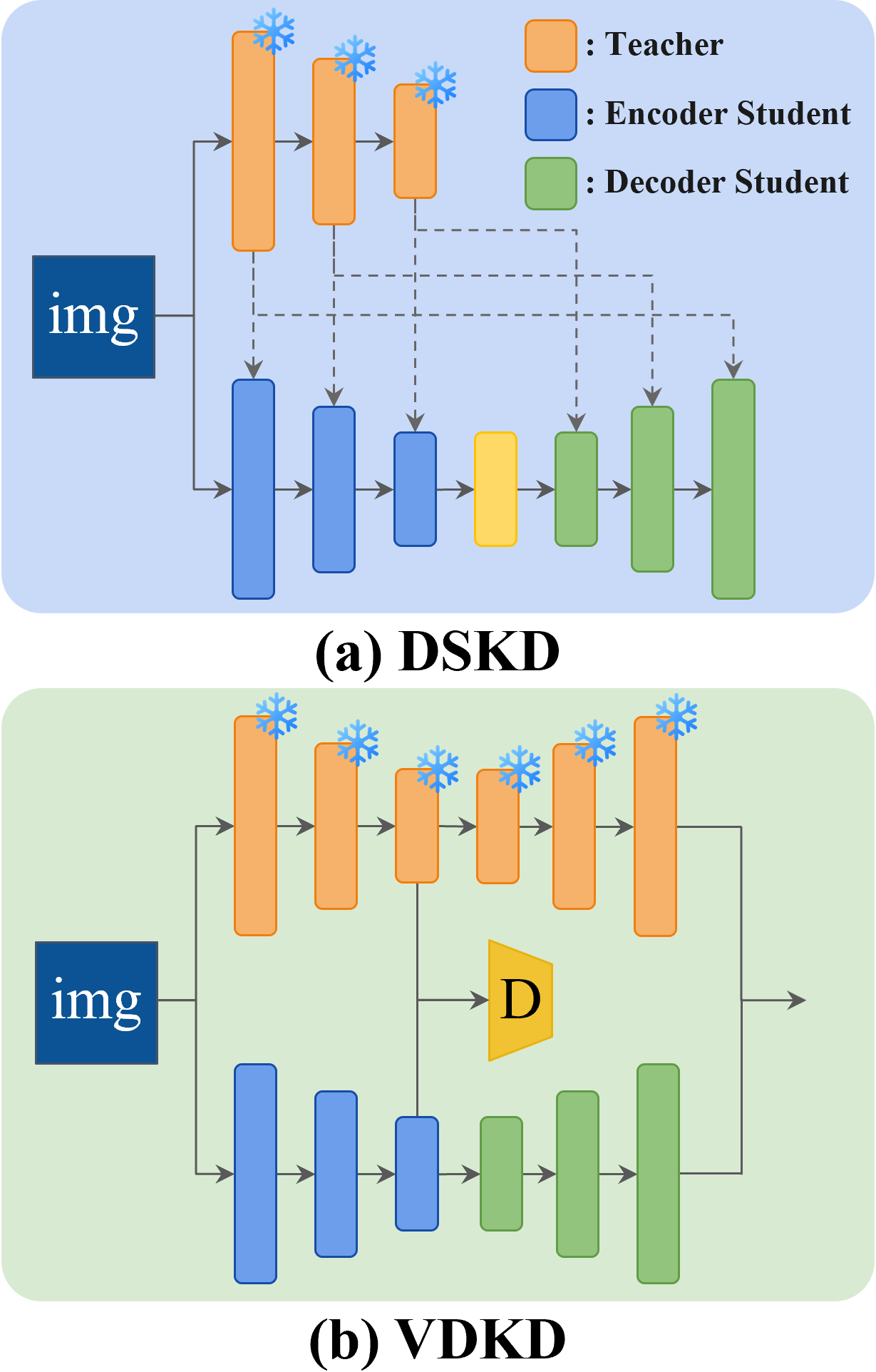
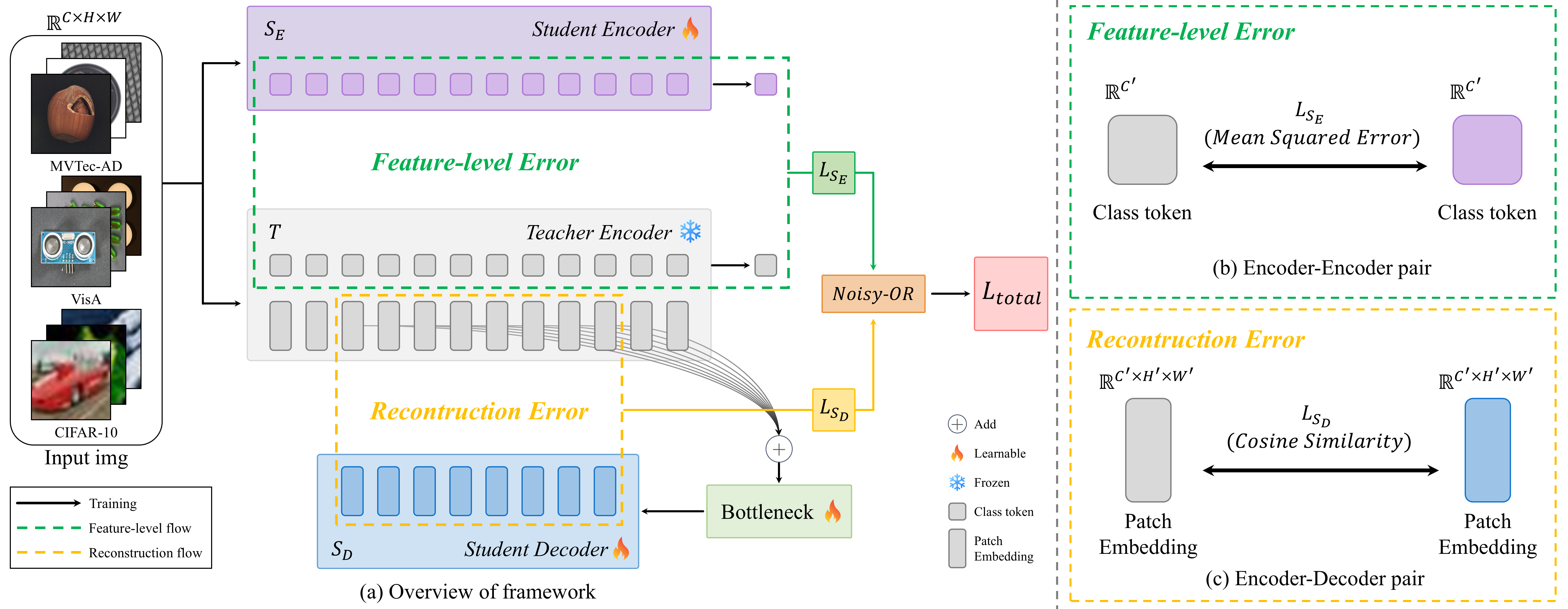
技术框架:该框架包含一个教师模型和两个学生模型。教师模型使用预训练的DINOv2编码器提取高质量的特征表示。两个学生模型分别是:1) Encoder-Decoder模型,用于检测patch级别的微小缺陷,适用于工业异常检测;2) Encoder-Encoder模型,用于检测语义异常。两个学生模型通过知识蒸馏从教师模型学习,并使用Noisy-OR目标函数进行联合训练。最终的异常分数通过结合两个学生模型的局部和语义异常分数得到。
关键创新:该方法的主要创新在于使用双异构学生模型进行知识蒸馏,从而能够同时捕捉局部缺陷和语义异常。这种双模型集成方法提高了模型的泛化能力,使其能够适应不同的异常检测任务和数据集。此外,使用Noisy-OR目标函数进行联合训练,可以有效地结合两个学生模型的输出。
关键设计:DINOv2预训练模型作为共享编码器,提供高质量的特征表示。Encoder-Decoder模型和Encoder-Encoder模型的具体网络结构未知,但其设计目标分别是patch级别的缺陷检测和语义异常检测。Noisy-OR目标函数的具体形式未知,但其作用是联合两个学生模型的输出,提高整体的异常检测性能。异常分数的计算方式是结合局部和语义异常分数的联合概率,具体计算公式未知。
🖼️ 关键图片
📊 实验亮点
该方法在MVTec-AD数据集上实现了99.7%的图像级AUROC,在CIFAR-10数据集上实现了97.8%的图像级AUROC。这些结果显著优于现有的通用异常检测模型,甚至超过了在特定数据集上训练的专家模型。这表明该方法具有很强的泛化能力和优越的性能。
🎯 应用场景
该研究成果可广泛应用于工业质检、医疗影像分析、自动驾驶等领域。在工业质检中,可用于检测产品表面的缺陷。在医疗影像分析中,可用于辅助医生诊断疾病。在自动驾驶中,可用于检测道路上的异常物体,提高行车安全性。该方法具有很高的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Anomaly detection (AD) plays an important role in various real-world applications. Recent advancements in AD, however, are often biased towards industrial inspection, struggle to generalize to broader tasks like semantic anomaly detection and vice versa. Although recent methods have attempted to address general anomaly detection, their performance remains sensitive to dataset-specific settings and single-class tasks. In this paper, we propose a novel dual-model ensemble approach based on knowledge distillation (KD) to bridge this gap. Our framework consists of a teacher and two student models: an Encoder-Decoder model, specialized in detecting patch-level minor defects for industrial AD and an Encoder-Encoder model, optimized for semantic AD. Both models leverage a shared pre-trained encoder (DINOv2) to extract high-quality feature representations. The dual models are jointly learned using the Noisy-OR objective, and the final anomaly score is obtained using the joint probability via local and semantic anomaly scores derived from the respective models. We evaluate our method on eight public benchmarks under both single-class and multi-class settings: MVTec-AD, MVTec-LOCO, VisA and Real-IAD for industrial inspection and CIFAR-10/100, FMNIST and View for semantic anomaly detection. The proposed method achieved state-of-the-art accuracies in both domains, in multi-class as well as single-class settings, demonstrating generalization across multiple domains of anomaly detection. Our model achieved an image-level AUROC of 99.7% on MVTec-AD and 97.8% on CIFAR-10, which is significantly better than the prior general AD models in multi-class settings and even higher than the best specialist models on individual benchmarks.