UI2V-Bench: An Understanding-based Image-to-video Generation Benchmark
作者: Ailing Zhang, Lina Lei, Dehong Kong, Zhixin Wang, Jiaqi Xu, Fenglong Song, Chun-Le Guo, Chang Liu, Fan Li, Jie Chen
分类: cs.CV
发布日期: 2025-09-29
💡 一句话要点
提出UI2V-Bench以解决图像到视频生成的语义理解问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像到视频生成 语义理解 推理能力 多模态大语言模型 生成模型评估 视频合成 评估基准
📋 核心要点
- 现有的I2V生成模型评估方法主要集中在视频质量和时间一致性上,缺乏对语义理解和推理能力的考量。
- 论文提出了UI2V-Bench基准,专注于语义理解和推理,设计了基于MLLM的评估方法以填补这一空白。
- 通过对约500对文本-图像对的评估,UI2V-Bench展示了与人类评估的强一致性,验证了其有效性。
📝 摘要(中文)
生成扩散模型正在快速发展,并因其广泛的应用而受到越来越多的关注。图像到视频(I2V)生成已成为视频合成领域的主要焦点。然而,现有评估基准主要关注视频质量和时间一致性,忽视了模型理解输入图像中特定主题语义的能力,以及生成视频是否符合物理法则和人类常识。为了解决这一问题,我们提出了UI2V-Bench,一个专注于语义理解和推理的I2V模型评估基准。它引入了四个主要评估维度:空间理解、属性绑定、类别理解和推理。我们设计了基于多模态大语言模型(MLLM)的两种评估方法,以评估这些维度。UI2V-Bench包含约500对精心构建的文本-图像对,并对多种开源和闭源I2V模型进行了评估。总体而言,UI2V-Bench填补了I2V评估中的关键空白,强调了语义理解和推理能力,为未来的研究和模型开发提供了强有力的框架和数据集。
🔬 方法详解
问题定义:本论文旨在解决现有图像到视频生成模型评估中对语义理解和推理能力的忽视,现有方法主要关注视频的质量和一致性,未能全面评估模型的理解能力。
核心思路:论文提出UI2V-Bench基准,通过引入空间理解、属性绑定、类别理解和推理四个维度,全面评估I2V模型的语义理解能力。设计基于多模态大语言模型的评估方法,以实现更细致的语义理解和推理。
技术框架:UI2V-Bench的整体架构包括两个主要评估模块:实例级管道用于细粒度的语义理解,反馈式推理管道用于逐步因果评估。这两个模块结合使用,以提供全面的评估结果。
关键创新:最重要的创新点在于引入了基于MLLM的评估方法,强调了语义理解和推理能力的评估,与传统方法相比,提供了更深入的分析和反馈。
关键设计:在设计中,论文构建了约500对文本-图像对,并通过人类评估与MLLM指标进行对比,确保评估的有效性和可靠性。
🖼️ 关键图片
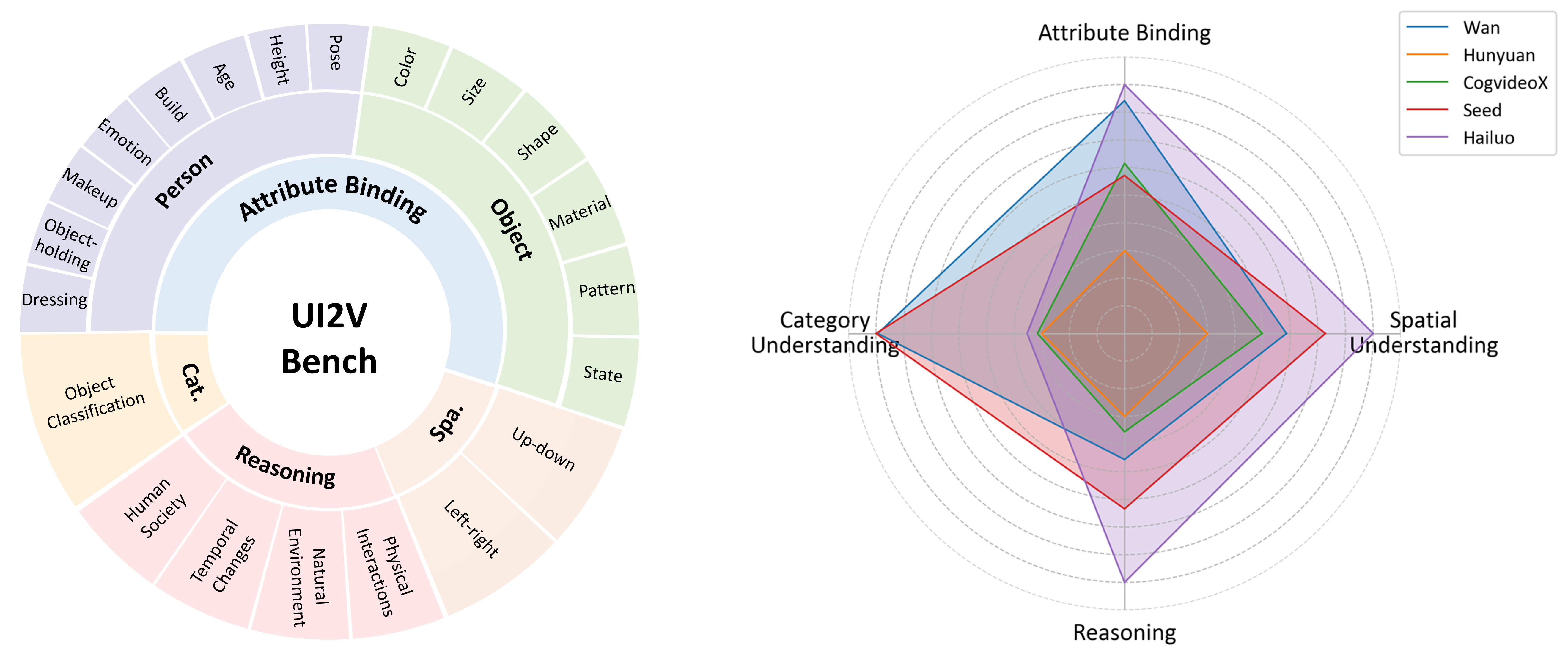
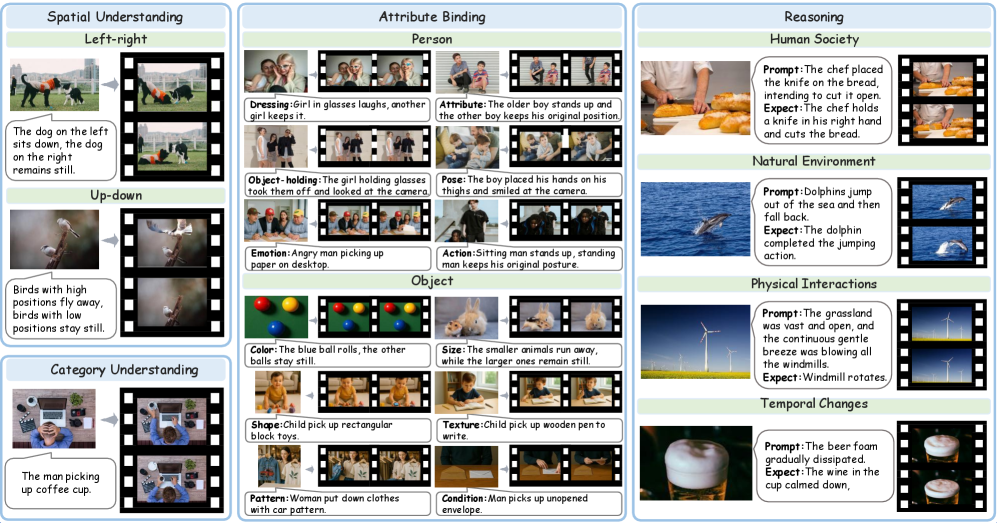
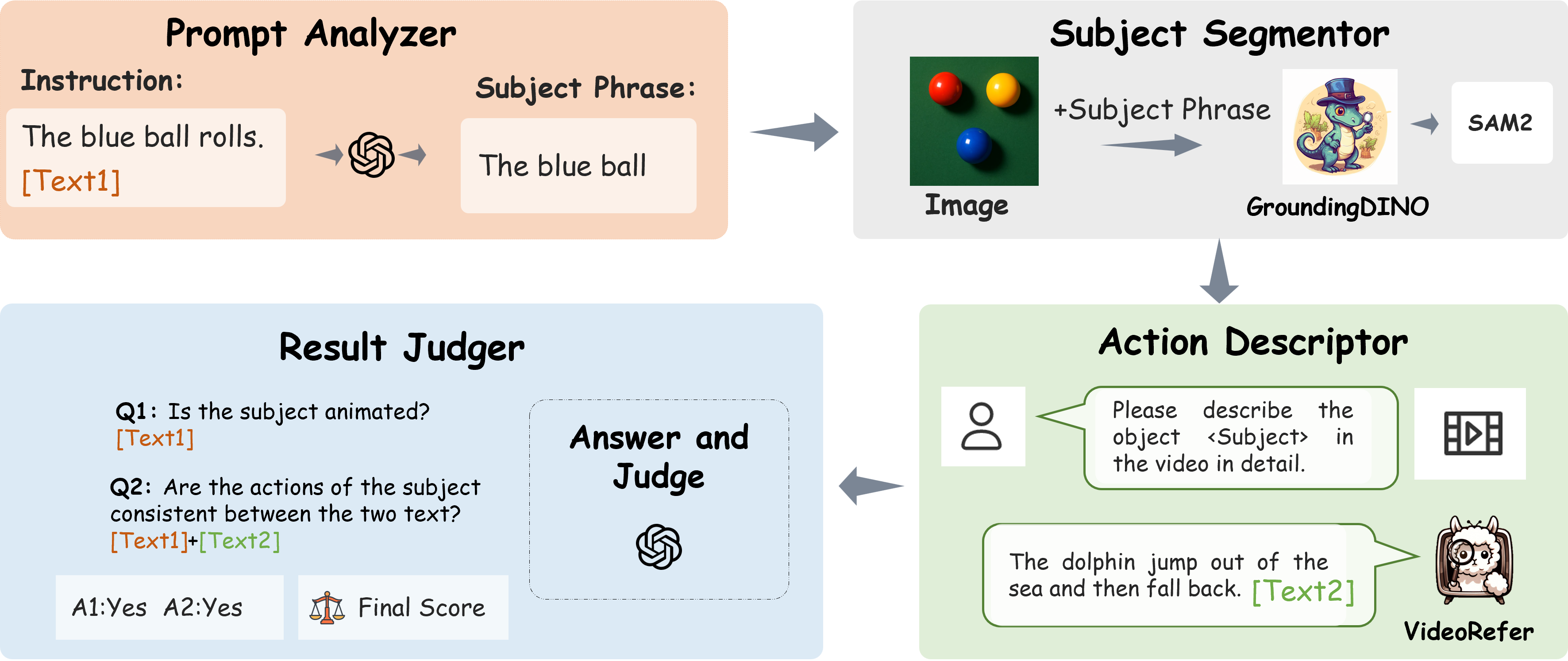
📊 实验亮点
实验结果显示,UI2V-Bench在评估I2V模型时,与人类评估结果高度一致,验证了其评估方法的有效性。通过引入新的评估维度,模型在语义理解和推理能力上有显著提升,提供了更全面的性能分析。
🎯 应用场景
该研究的潜在应用领域包括视频生成、虚拟现实、游戏开发等,能够为这些领域提供更高质量的生成模型评估标准。通过强调语义理解和推理能力,UI2V-Bench将推动相关技术的进步,促进更智能的内容生成和交互体验。
📄 摘要(原文)
Generative diffusion models are developing rapidly and attracting increasing attention due to their wide range of applications. Image-to-Video (I2V) generation has become a major focus in the field of video synthesis. However, existing evaluation benchmarks primarily focus on aspects such as video quality and temporal consistency, while largely overlooking the model's ability to understand the semantics of specific subjects in the input image or to ensure that the generated video aligns with physical laws and human commonsense. To address this gap, we propose UI2V-Bench, a novel benchmark for evaluating I2V models with a focus on semantic understanding and reasoning. It introduces four primary evaluation dimensions: spatial understanding, attribute binding, category understanding, and reasoning. To assess these dimensions, we design two evaluation methods based on Multimodal Large Language Models (MLLMs): an instance-level pipeline for fine-grained semantic understanding, and a feedback-based reasoning pipeline that enables step-by-step causal assessment for more accurate evaluation. UI2V-Bench includes approximately 500 carefully constructed text-image pairs and evaluates a range of both open source and closed-source I2V models across all defined dimensions. We further incorporate human evaluations, which show strong alignment with the proposed MLLM-based metrics. Overall, UI2V-Bench fills a critical gap in I2V evaluation by emphasizing semantic comprehension and reasoning ability, offering a robust framework and dataset to support future research and model development in the field.