REALIGN: Regularized Procedure Alignment with Matching Video Embeddings via Partial Gromov-Wasserstein Optimal Transport
作者: Soumyadeep Chandra, Kaushik Roy
分类: cs.CV, cs.AI
发布日期: 2025-09-29
备注: 10 pages, 4 figures, 6 tables
💡 一句话要点
REALIGN:基于正则化融合部分Gromov-Wasserstein最优传输的程序视频对齐方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 程序视频学习 自监督学习 最优传输 Gromov-Wasserstein 视频对齐 时间关系建模 对比学习
📋 核心要点
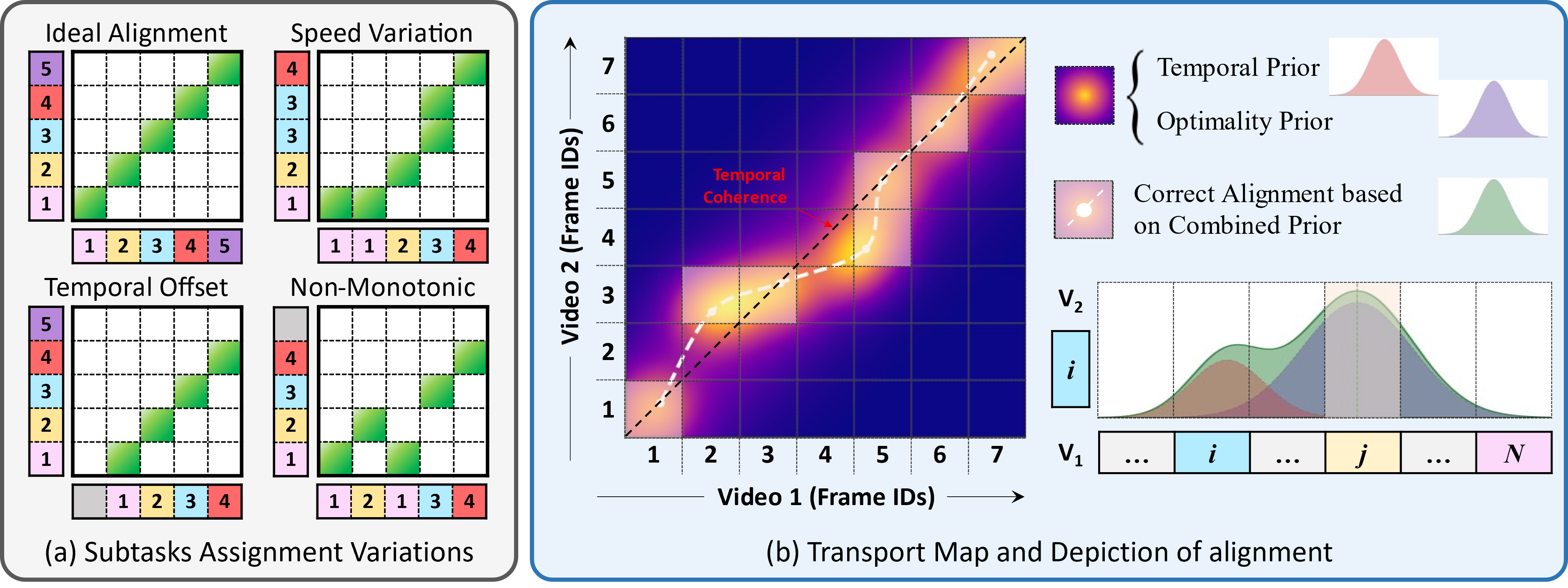
- 现有程序视频学习方法难以处理真实教学视频中的背景片段、重复动作和乱序步骤等问题。
- REALIGN通过正则化融合部分Gromov-Wasserstein最优传输,联合建模视觉对应关系和时间关系,实现鲁棒对齐。
- 实验表明,REALIGN在多个基准测试中显著提升了F1分数和时间IoU,并生成了更易解释的传输映射。
📝 摘要(中文)
从程序视频中学习仍然是自监督表征学习中的一个核心挑战,因为现实世界的教学数据通常包含背景片段、重复动作和乱序步骤。这种可变性违反了许多对齐方法所基于的强单调性假设。现有最优方法,如OPEL,利用Kantorovich最优传输(KOT)来构建帧到帧的对应关系,但仅依赖于特征相似性,而未能捕捉任务的更高阶时间结构。本文提出REALIGN,一个基于正则化融合部分Gromov-Wasserstein最优传输(R-FPGWOT)的程序学习自监督框架。与KOT相比,我们的公式在部分对齐方案下联合建模视觉对应关系和时间关系,从而能够稳健地处理教学视频中常见的无关帧、重复动作和非单调步骤顺序。为了稳定训练,我们将FPGWOT距离与序列间对比学习相结合,避免了对多个正则化器的需求,并防止崩溃到退化解。在以自我为中心的(EgoProceL)和第三人称(ProceL,CrossTask)基准测试中,REALIGN实现了高达18.9%的平均F1分数提升和超过30%的时间IoU增益,同时产生了更易于解释的传输映射,保留了关键步骤顺序并过滤掉了噪声。
🔬 方法详解
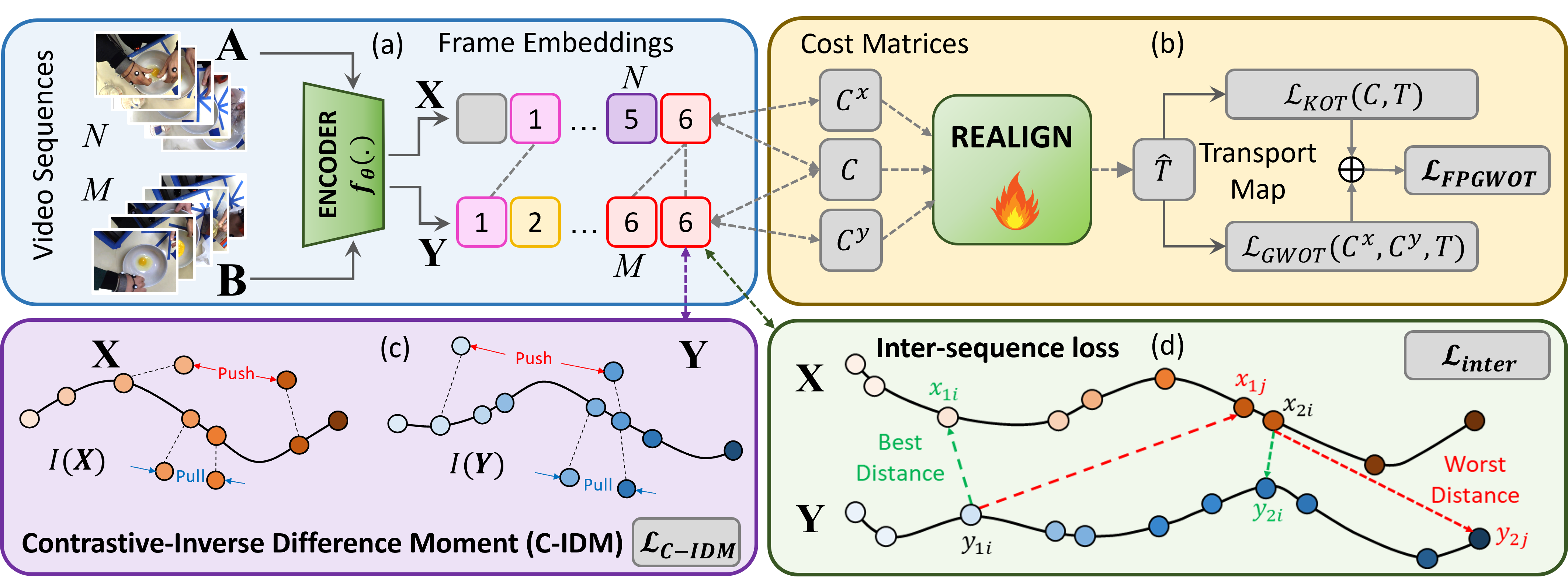
问题定义:论文旨在解决程序视频中由于背景片段、重复动作和乱序步骤导致的对齐问题。现有方法,如OPEL,主要依赖帧与帧之间的特征相似性,忽略了视频的时序结构,导致对齐效果不佳。
核心思路:论文的核心思路是利用正则化融合部分Gromov-Wasserstein最优传输(R-FPGWOT)来联合建模视频帧之间的视觉对应关系和时序关系。通过部分对齐,可以处理无关帧和重复动作;通过Gromov-Wasserstein最优传输,可以更好地捕捉视频的时序结构。
技术框架:REALIGN框架包含以下主要步骤:1) 提取视频帧的视觉特征;2) 构建帧之间的视觉相似度矩阵和时序关系矩阵;3) 利用R-FPGWOT计算最优传输映射,该映射指示了帧之间的对应关系;4) 使用序列间对比学习来稳定训练过程,并防止模型崩溃。
关键创新:最重要的技术创新点在于使用R-FPGWOT来联合建模视觉对应关系和时序关系,并采用部分对齐方案。与传统的Kantorovich最优传输相比,R-FPGWOT能够更好地捕捉视频的时序结构,并处理无关帧和重复动作。
关键设计:论文的关键设计包括:1) 使用Fused Gromov-Wasserstein来融合视觉和时序信息;2) 使用Partial Optimal Transport来处理无关帧;3) 使用序列间对比学习作为正则化项,避免模型坍塌;4) 损失函数结合了FPGWOT距离和对比学习损失。
🖼️ 关键图片
📊 实验亮点
REALIGN在EgoProceL、ProceL和CrossTask等基准测试中取得了显著的性能提升。例如,在EgoProceL数据集上,REALIGN的平均F1分数提升了高达18.9%,时间IoU增益超过30%。实验结果表明,REALIGN能够生成更易于解释的传输映射,保留关键步骤顺序并过滤掉噪声,从而实现更准确的程序视频对齐。
🎯 应用场景
REALIGN可应用于机器人技能学习、自动教学视频分析、视频检索等领域。通过准确对齐程序视频,可以帮助机器人理解人类的动作意图,从而模仿学习新的技能。此外,该方法还可以用于自动分析教学视频,提取关键步骤,并生成简洁的教学指南。在视频检索方面,REALIGN可以用于搜索包含特定步骤的视频片段。
📄 摘要(原文)
Learning from procedural videos remains a core challenge in self-supervised representation learning, as real-world instructional data often contains background segments, repeated actions, and steps presented out of order. Such variability violates the strong monotonicity assumptions underlying many alignment methods. Prior state-of-the-art approaches, such as OPEL, leverage Kantorovich Optimal Transport (KOT) to build frame-to-frame correspondences, but rely solely on feature similarity and fail to capture the higher-order temporal structure of a task. In this paper, we introduce REALIGN, a self-supervised framework for procedure learning based on Regularized Fused Partial Gromov-Wasserstein Optimal Transport (R-FPGWOT). In contrast to KOT, our formulation jointly models visual correspondences and temporal relations under a partial alignment scheme, enabling robust handling of irrelevant frames, repeated actions, and non-monotonic step orders common in instructional videos. To stabilize training, we integrate FPGWOT distances with inter-sequence contrastive learning, avoiding the need for multiple regularizers and preventing collapse to degenerate solutions. Across egocentric (EgoProceL) and third-person (ProceL, CrossTask) benchmarks, REALIGN achieves up to 18.9% average F1-score improvements and over 30% temporal IoU gains, while producing more interpretable transport maps that preserve key-step orderings and filter out noise.