DINOReg: Strong Point Cloud Registration with Vision Foundation Model
作者: Congjia Chen, Yufu Qu
分类: cs.CV
发布日期: 2025-09-29
🔗 代码/项目: GITHUB
💡 一句话要点
DINOReg:利用视觉基础模型实现强大的点云配准
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 点云配准 视觉基础模型 DINOv2 多模态融合 RGB-D数据 特征融合 混合位置编码
📋 核心要点
- 现有方法在点云配准中未能充分利用RGB-D图像的纹理和语义信息,且图像特征融合过程存在信息损失。
- DINOReg利用DINOv2提取图像的视觉特征,并在patch级别与几何特征融合,从而结合视觉语义与几何结构信息。
- 实验表明,DINOReg在RGBD-3DMatch和RGBD-3DLoMatch数据集上显著优于现有方法,性能提升明显。
📝 摘要(中文)
点云配准是三维计算机视觉中的一项基本任务。现有方法大多仅依赖几何信息进行特征提取和匹配。最近,一些研究将RGB-D数据中的颜色信息融入特征提取,虽然取得了显著改进,但并未充分利用图像中丰富的纹理和语义信息,且特征融合方式有损图像信息,限制了性能。本文提出了DINOReg,一种充分利用视觉和几何信息解决点云配准问题的网络。受视觉基础模型进展的启发,我们采用DINOv2从图像中提取信息丰富的视觉特征,并在patch级别融合视觉和几何特征。这种设计有效地结合了DINOv2提取的丰富纹理和全局语义信息,以及几何骨干网络捕获的详细几何结构信息。此外,提出了一种混合位置嵌入来编码图像空间和点云空间的位置信息,增强了模型感知patch之间空间关系的能力。在RGBD-3DMatch和RGBD-3DLoMatch数据集上的大量实验表明,我们的方法相比最先进的纯几何方法和多模态配准方法,取得了显著的改进,patch内点比例提高了14.2%,配准召回率提高了15.7%。代码已公开。
🔬 方法详解
问题定义:点云配准旨在找到两个或多个点云之间的空间变换关系,是三维重建、SLAM等应用的基础。现有方法主要依赖点云的几何特征,忽略了RGB-D数据中图像所蕴含的丰富纹理和语义信息。即使一些方法引入了颜色信息,也未能充分利用图像特征,并且在特征融合过程中存在信息损失,限制了配准精度。
核心思路:DINOReg的核心思路是充分利用视觉基础模型DINOv2提取的图像特征,并将其与点云的几何特征进行有效融合。DINOv2能够提取图像的全局语义信息和局部纹理细节,与几何特征形成互补,从而提升配准的准确性和鲁棒性。通过在patch级别进行特征融合,可以更好地保留图像信息,避免信息损失。
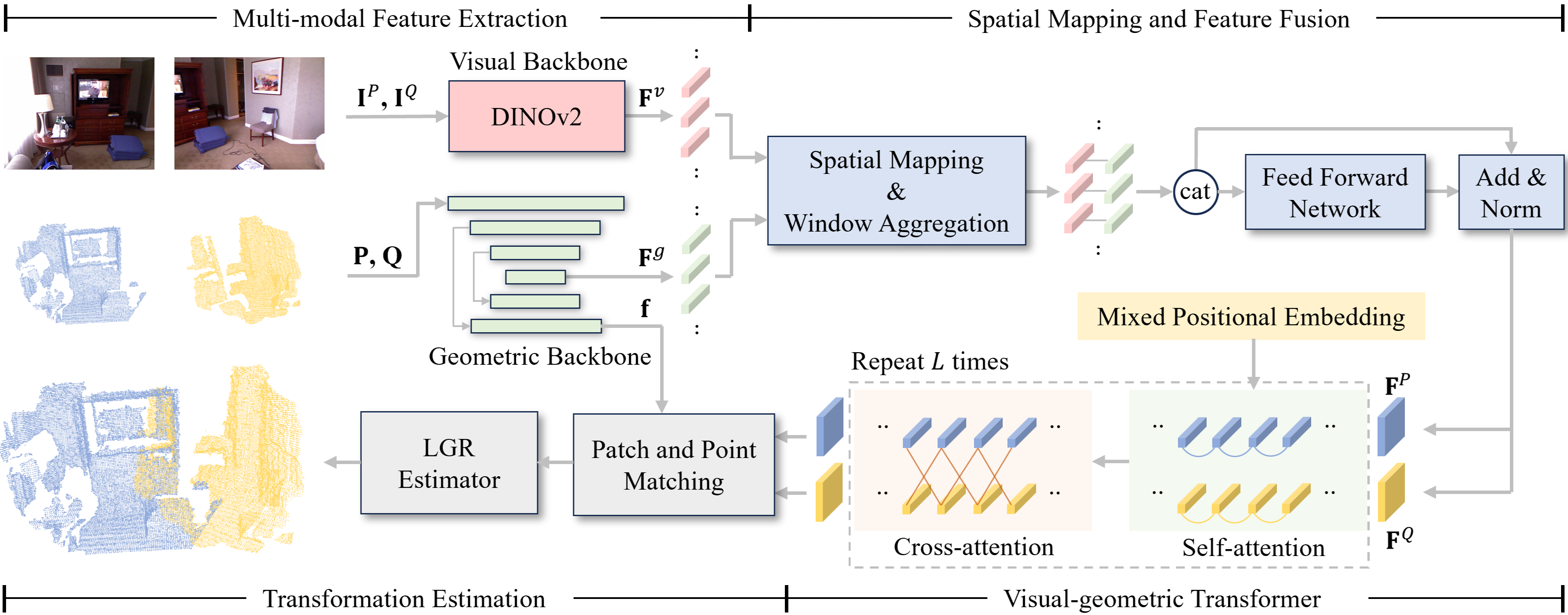
技术框架:DINOReg的整体框架包括以下几个主要模块:1) 几何特征提取模块:使用几何骨干网络提取点云的几何特征。2) 视觉特征提取模块:使用DINOv2提取RGB图像的视觉特征。3) 特征融合模块:在patch级别融合几何特征和视觉特征。4) 混合位置编码模块:编码图像空间和点云空间的位置信息。5) 配准模块:基于融合后的特征进行点云配准。
关键创新:DINOReg的关键创新在于:1) 充分利用了视觉基础模型DINOv2提取的图像特征,弥补了传统方法对图像信息利用不足的缺陷。2) 提出了在patch级别进行特征融合的方法,有效保留了图像信息,避免了信息损失。3) 提出了混合位置编码,增强了模型对patch之间空间关系的感知能力。与现有方法相比,DINOReg能够更有效地利用视觉和几何信息,从而提升配准精度。
关键设计:DINOReg的关键设计包括:1) 使用DINOv2作为视觉特征提取器,利用其强大的特征提取能力。2) 在patch级别进行特征融合,保证图像信息的完整性。3) 设计混合位置编码,结合图像空间和点云空间的位置信息。4) 使用对比损失函数训练网络,提高特征的区分性。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
DINOReg在RGBD-3DMatch和RGBD-3DLoMatch数据集上进行了实验,结果表明,DINOReg相比最先进的纯几何方法和多模态配准方法,取得了显著的改进。具体来说,在RGBD-3DMatch数据集上,DINOReg的patch内点比例提高了14.2%,配准召回率提高了15.7%。这些结果表明,DINOReg能够更有效地利用视觉和几何信息,从而提升配准精度。
🎯 应用场景
DINOReg在机器人导航、三维重建、增强现实等领域具有广泛的应用前景。例如,在机器人导航中,可以利用DINOReg进行环境地图的构建和定位;在三维重建中,可以利用DINOReg将多个扫描的点云数据进行精确对齐;在增强现实中,可以利用DINOReg将虚拟物体与真实场景进行精确配准。该研究的实际价值在于提高了点云配准的精度和鲁棒性,为相关应用提供了更好的技术支持。未来,可以进一步探索DINOReg在动态场景和大规模场景中的应用。
📄 摘要(原文)
Point cloud registration is a fundamental task in 3D computer vision. Most existing methods rely solely on geometric information for feature extraction and matching. Recently, several studies have incorporated color information from RGB-D data into feature extraction. Although these methods achieve remarkable improvements, they have not fully exploited the abundant texture and semantic information in images, and the feature fusion is performed in an image-lossy manner, which limit their performance. In this paper, we propose DINOReg, a registration network that sufficiently utilizes both visual and geometric information to solve the point cloud registration problem. Inspired by advances in vision foundation models, we employ DINOv2 to extract informative visual features from images, and fuse visual and geometric features at the patch level. This design effectively combines the rich texture and global semantic information extracted by DINOv2 with the detailed geometric structure information captured by the geometric backbone. Additionally, a mixed positional embedding is proposed to encode positional information from both image space and point cloud space, which enhances the model's ability to perceive spatial relationships between patches. Extensive experiments on the RGBD-3DMatch and RGBD-3DLoMatch datasets demonstrate that our method achieves significant improvements over state-of-the-art geometry-only and multi-modal registration methods, with a 14.2% increase in patch inlier ratio and a 15.7% increase in registration recall. The code is publicly available at https://github.com/ccjccjccj/DINOReg.