Latent Visual Reasoning
作者: Bangzheng Li, Ximeng Sun, Jiang Liu, Ze Wang, Jialian Wu, Xiaodong Yu, Hao Chen, Emad Barsoum, Muhao Chen, Zicheng Liu
分类: cs.CV, cs.CL
发布日期: 2025-09-29 (更新: 2025-10-05)
💡 一句话要点
提出潜在视觉推理(LVR),实现视觉嵌入空间内的自回归推理,提升视觉问答性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉推理 多模态学习 视觉问答 自回归模型 潜在空间
📋 核心要点
- 现有MLLM视觉推理受限于语言空间,视觉信息作为静态输入,缺乏对视觉信息的动态推理能力。
- LVR通过在视觉嵌入空间中进行自回归推理,使模型能够直接操作和理解视觉信息,提升推理能力。
- 实验表明,LVR在视觉问答任务上显著优于现有方法,尤其在细粒度视觉理解方面有明显提升。
📝 摘要(中文)
多模态大型语言模型(MLLMs)通过在语言空间中结合思维链(CoT)推理,在各种任务中取得了显著进展。最近的研究通过利用外部工具进行视觉编辑来扩展这一方向,从而增强了推理轨迹中的视觉信号。然而,这些方法仍然受到根本限制:推理仍然局限于语言空间,视觉信息被视为静态前提条件。我们引入了潜在视觉推理(LVR),这是一种新的范式,可以直接在视觉嵌入空间中实现自回归推理。视觉编码器首先将图像投影到与语言模型共享的联合语义空间中的视觉token。然后训练语言模型生成潜在状态,这些状态重建对于回答查询至关重要的关键视觉token,从而构成潜在视觉推理的过程。通过将LVR与标准文本生成交错,我们的模型在感知密集型视觉问答任务上取得了显著的提升。此外,我们还调整了GRPO算法,对潜在推理进行强化学习,进一步平衡LVR和文本生成。我们表明,LVR显著提高了细粒度的视觉理解和感知能力,在MMVP上达到了71.67%,而Qwen2.5-VL为66.67%。代码库和模型权重将在稍后发布。
🔬 方法详解
问题定义:现有方法在进行视觉推理时,主要依赖于语言空间,将视觉信息视为静态的输入,缺乏在视觉层面进行动态推理的能力。这限制了模型在需要精细视觉理解的任务中的表现,例如需要理解图像中细微差别的视觉问答。
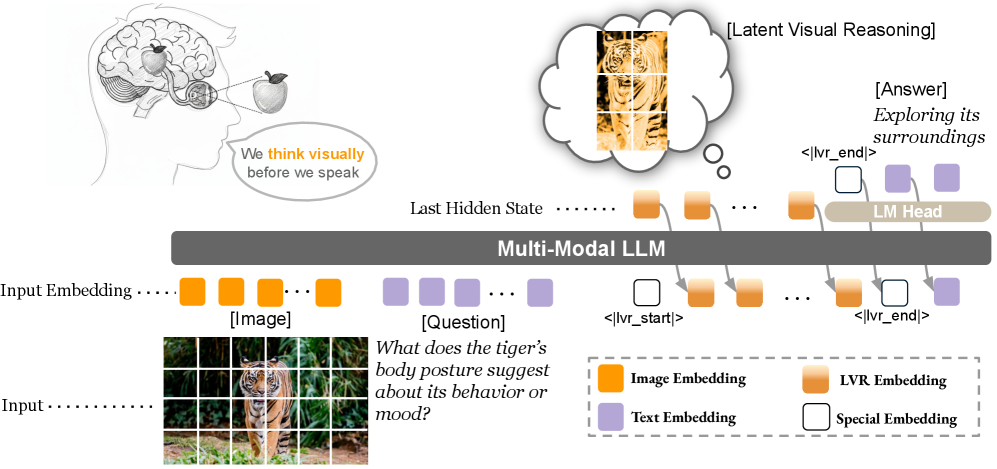
核心思路:LVR的核心思路是将视觉信息投影到与语言模型共享的联合语义空间,并在该空间中进行自回归推理。通过训练语言模型生成能够重建关键视觉token的潜在状态,实现视觉层面的推理,从而弥补现有方法的不足。
技术框架:LVR包含以下主要模块:1) 视觉编码器:将图像投影到视觉token;2) 语言模型:生成潜在状态,用于重建关键视觉token;3) LVR与文本生成交错模块:将视觉推理与文本生成相结合,实现多模态推理。整体流程是,给定图像和问题,视觉编码器提取视觉特征,语言模型基于问题和视觉特征生成潜在状态,这些状态用于重建关键视觉token,最后结合文本生成答案。
关键创新:LVR最重要的创新点在于实现了在视觉嵌入空间中的自回归推理。与现有方法不同,LVR不再将视觉信息视为静态输入,而是允许模型在视觉层面进行动态操作和推理,从而更好地理解图像内容。
关键设计:LVR的关键设计包括:1) 联合语义空间:确保视觉token和语言token可以在同一空间中进行交互;2) 潜在状态生成:训练语言模型生成能够有效重建关键视觉token的潜在状态;3) GRPO算法的调整:使用强化学习平衡LVR和文本生成,优化整体性能。具体参数设置和网络结构细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
LVR在MMVP数据集上取得了显著的性能提升,达到了71.67%,相比于Qwen2.5-VL的66.67%有明显优势。这表明LVR在细粒度视觉理解和感知方面具有更强的能力。实验结果验证了LVR在视觉问答任务中的有效性,并为未来的研究提供了新的方向。
🎯 应用场景
LVR具有广泛的应用前景,例如智能监控、自动驾驶、医学影像分析等领域。通过提升模型对细粒度视觉信息的理解能力,LVR可以帮助机器更好地理解周围环境,做出更准确的决策,从而提高工作效率和安全性。未来,LVR有望成为多模态人工智能的重要组成部分。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have achieved notable gains in various tasks by incorporating Chain-of-Thought (CoT) reasoning in language spaces. Recent work extends this direction by leveraging external tools for visual editing, thereby enhancing the visual signal along the reasoning trajectories. Nevertheless, these approaches remain fundamentally constrained: reasoning is still confined to the language space, with visual information treated as static preconditions. We introduce Latent Visual Reasoning (LVR), a new paradigm that enables autoregressive reasoning directly in the visual embedding space. A visual encoder first projects images into visual tokens within a joint semantic space shared with the language model. The language model is then trained to generate latent states that reconstruct key visual tokens critical for answering the query, constituting the process of latent visual reasoning. By interleaving LVR with standard text generation, our model achieves substantial gains on perception-intensive visual question answering tasks. In addition, we adapt the GRPO algorithm to conduct reinforcement learning on latent reasoning, further balancing LVR and textual generation. We show that LVR substantially improves fine-grained visual understanding and perception, achieving 71.67% on MMVP compared to 66.67% with Qwen2.5-VL. Code base and model weights will be released later.