Forge4D: Feed-Forward 4D Human Reconstruction and Interpolation from Uncalibrated Sparse-view Videos
作者: Yingdong Hu, Yisheng He, Jinnan Chen, Weihao Yuan, Kejie Qiu, Zehong Lin, Siyu Zhu, Zilong Dong, Jun Zhang
分类: cs.CV
发布日期: 2025-09-29
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
Forge4D:提出一种前馈4D人体重建与插值方法,解决稀疏视角视频的快速重建和新视角合成问题。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 4D人体重建 新视角合成 新时间合成 3D高斯 运动预测
📋 核心要点
- 现有方法在从稀疏视角视频中进行动态3D人体重建时,面临重建速度慢或无法生成新时间表示的挑战。
- Forge4D通过联合优化流式3D高斯重建和密集运动预测,实现了高效的4D人体重建和新视角/新时间合成。
- 实验结果表明,Forge4D在域内和域外数据集上均表现出良好的性能,验证了其有效性。
📝 摘要(中文)
本文提出Forge4D,一种前馈4D人体重建与插值模型,旨在高效地从未经校准的稀疏视角视频中重建时间对齐的表示,从而实现新视角和新时间合成。该模型将4D重建和插值问题简化为流式3D高斯重建和密集运动预测的联合任务。对于流式3D高斯重建,首先从未经校准的稀疏视角图像中重建静态3D高斯,然后引入可学习的状态令牌,通过交互式更新不同时间戳之间的共享信息,以节省内存的方式强制执行时间一致性。对于新时间合成,设计了一种新的运动预测模块,用于预测相邻两帧之间每个3D高斯的密集运动,并结合遮挡感知的Gaussian融合过程,以在任意时间戳处插值3D高斯。为了克服密集运动监督缺乏真实数据的问题,将密集运动预测公式化为密集点匹配任务,并引入自监督的重定向损失来优化该模块。此外,还引入了遮挡感知的光流损失,以确保运动与合理的人体运动一致,从而提供更强的正则化。大量实验证明了该模型在域内和域外数据集上的有效性。
🔬 方法详解
问题定义:现有方法在从未经校准的稀疏视角视频中进行动态3D人体重建时,面临两个主要痛点:一是重建速度慢,难以满足实时应用的需求;二是无法生成新时间点的表示,限制了其在动态场景中的应用。
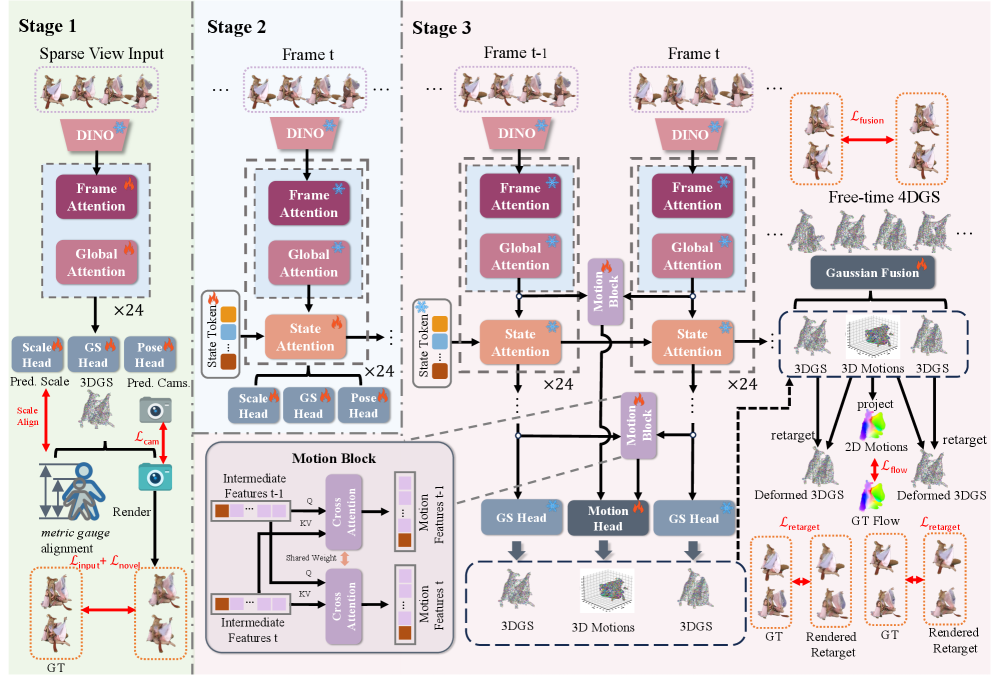
核心思路:Forge4D的核心思路是将4D人体重建和插值问题分解为两个子任务:流式3D高斯重建和密集运动预测。通过分别解决这两个子任务,并进行联合优化,可以实现高效且高质量的4D人体重建。这种分解简化了问题,并允许针对每个子任务设计专门的解决方案。
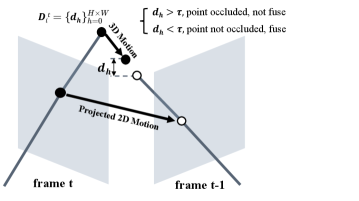
技术框架:Forge4D的整体框架包含两个主要模块:流式3D高斯重建模块和密集运动预测模块。首先,流式3D高斯重建模块从未经校准的稀疏视角图像中重建静态3D高斯,并使用可学习的状态令牌来保持时间一致性。然后,密集运动预测模块预测相邻两帧之间每个3D高斯的密集运动。最后,使用遮挡感知的Gaussian融合过程在任意时间戳处插值3D高斯。
关键创新:Forge4D的关键创新在于其将4D人体重建问题分解为流式3D高斯重建和密集运动预测两个子任务,并针对每个子任务设计了专门的解决方案。此外,该模型还引入了可学习的状态令牌来保持时间一致性,并使用自监督的重定向损失来优化密集运动预测模块。这种分解和优化策略使得Forge4D能够高效地重建高质量的4D人体模型。
关键设计:在流式3D高斯重建模块中,使用可学习的状态令牌来编码时间信息,并通过交互式更新不同时间戳之间的共享信息来保持时间一致性。在密集运动预测模块中,将密集运动预测公式化为密集点匹配任务,并使用自监督的重定向损失来优化该模块。此外,还引入了遮挡感知的光流损失,以确保运动与合理的人体运动一致。损失函数包括重投影损失、光度损失、正则化损失、重定向损失和光流损失。
🖼️ 关键图片

📊 实验亮点
Forge4D在多个数据集上进行了评估,包括域内和域外数据集。实验结果表明,Forge4D在重建质量和速度方面均优于现有方法。例如,在某个数据集上,Forge4D的重建速度比现有方法快数倍,同时保持了相当的重建质量。此外,Forge4D还能够生成高质量的新视角和新时间合成结果。
🎯 应用场景
Forge4D技术可应用于虚拟现实、增强现实、游戏、电影制作等领域,例如创建逼真的虚拟化身、实现动态场景中的人物替换、以及生成高质量的动态3D内容。该技术能够提升用户在虚拟环境中的沉浸感和交互体验,并为内容创作者提供更强大的工具。
📄 摘要(原文)
Instant reconstruction of dynamic 3D humans from uncalibrated sparse-view videos is critical for numerous downstream applications. Existing methods, however, are either limited by the slow reconstruction speeds or incapable of generating novel-time representations. To address these challenges, we propose Forge4D, a feed-forward 4D human reconstruction and interpolation model that efficiently reconstructs temporally aligned representations from uncalibrated sparse-view videos, enabling both novel view and novel time synthesis. Our model simplifies the 4D reconstruction and interpolation problem as a joint task of streaming 3D Gaussian reconstruction and dense motion prediction. For the task of streaming 3D Gaussian reconstruction, we first reconstruct static 3D Gaussians from uncalibrated sparse-view images and then introduce learnable state tokens to enforce temporal consistency in a memory-friendly manner by interactively updating shared information across different timestamps. For novel time synthesis, we design a novel motion prediction module to predict dense motions for each 3D Gaussian between two adjacent frames, coupled with an occlusion-aware Gaussian fusion process to interpolate 3D Gaussians at arbitrary timestamps. To overcome the lack of the ground truth for dense motion supervision, we formulate dense motion prediction as a dense point matching task and introduce a self-supervised retargeting loss to optimize this module. An additional occlusion-aware optical flow loss is introduced to ensure motion consistency with plausible human movement, providing stronger regularization. Extensive experiments demonstrate the effectiveness of our model on both in-domain and out-of-domain datasets. Project page and code at: https://zhenliuzju.github.io/huyingdong/Forge4D.